Kaggleの「ECG Heartbeat Categorization Dataset」を掘り下げてみる

はじめに
皆さん、こんにちは。
今回は、Kaggleに存在する「ECG Heartbeat Categorization Dataset」というテーマについて、どんなデータが扱われていて、どんな風に解かれているのかを掘り下げてみようと思います。
Kaggleにまつわるエトセトラ
Kaggleとは?というような基本的な話は、以下の記事にまとめてありますので、もしよければ参照下さい。
以下は、上記リンクの内容を把握している人向けの話になります。
Kaggleの「ECG Heartbeat Categorization Dataset」とは?
波形データの取扱については、幾つかの方法論がある為、その観点で調べていたところ、Kaggleの「ECG Heartbeat Categorization Dataset」に辿り着きました。
ページは、以下です。
割と取り組んでいる人が多そうなテーマであるようなので、私も掘り下げてみようと思った次第です。
ちなみに、ECGとはElectrocardiogramの略で、心電図という意味です。
Kaggleページに記載してあるデータ説明
Kaggleページに記載してある説明(英語)を、先ずは読んでみました。
タイトルが示すように、心拍に関するデータであるようです。
昔から有名だった心拍データ(MIT-BIH不整脈データセット、PTB診断ECGデータベース)から、幾つかのデータをピックアップしたのが、当該Kaggleのデータであるようです。
データ数はかなり多く、10万件以上の波形データが含まれます。
特に多くの学習データが必要とされるDeep Learningでも、安定した学習が期待できる水準でしょう。
尚、Kaggle上のデータは、既に前処理が完了しているキレイなデータで、1心拍振動が1件となっています。
本来、複数の心拍を持つデータを、1波形ずつに分解するという前処理は、データサイエンティストが工夫を凝らして行う必要があるものですが、それは既に済んでいるということです。
(Kaggleのデータセットは、前処理済みのテーマが殆ど)
信号は、正常な場合と、異常な場合(不整脈や心筋梗塞の影響を受けたもの)が存在します。
正常な場合が1クラス、異常な場合が4クラス、計5クラスの識別を行うタスクとなっています。
データ中、それらクラスは、各々アルファベットで、以下のように示されているとのことです。
正常クラス : N
異常クラス1 : S
異常クラス2 : V
異常クラス3 : F
異常クラス4 : Q
そして、これら信号を、クラス識別することが、このKaggle DatasetのGoalとのことです。
尚、データ説明に関する記載の一部に謝辞として、以下の論文が紹介されています。
「ECG Heartbeat Classification: A Deep Transferable
Representation」と題した論文で、このKaggleデータの解き方を提案したもののようです。
(※論文投稿後に、Kaggleにデータが投稿された模様)
論文「ECG Heartbeat Classification: A Deep Transferable
Representation」を読んでみる
それでは、一先ず、その論文を読んでみることにしましょう。
Univercity of California, Los Angeles(UCLA)の方が書いた論文のようです。
概要としては、心電図による心拍の分類に、DeepなConvolutional Neural Network(以下、CNN)を用いてみたというもので、データとしてはMIT-BIH不整脈データセット・PTB診断ECGデータベースという2つのデータを用いたとのことです。
結果として提案手法は、不整脈分類と心筋梗塞分類とで、各々93.4%と95.9%という精度で予測ができたとのこと。
すごいですね。
背景としては、心電図による心臓の健康状態把握が重要性であるものの、それを人が分析するには時間がかかり過ぎる、という課題感が挙げられています。
また、人間が行ったとしてもエラーが発生しやすい、という課題感もあるようです。
尚、全世界の死亡理由1/3は心血管疾患であり、その兆しである不整脈を正確に発見できることは、とても重要だそうです。
扱うデータとしては、心臓波形1心拍毎に、少なくとも2人の心臓専門医が付けた注釈について、それを医療機器開発機構EC57標準に従い、5つの異なるビートカテゴリを作成する、ということをしているそうです。
要するには、ラベル付は専門家が手動で行っているということですね。
1心拍毎のデータに分けながらデータを取得する方法としては、古典的な手法らしいのですが、以下を採用してるとのことです。
(1) 連続する心電図の信号を、10秒毎のWindowに分割する
(2) 振幅を0〜1の範囲に正規化する
(3) 1次導関数のZERO交差(1次微分値がZEROになるポイント)から、全ての極大値を抽出する
(4) 正規化された振幅が、0.9を超える箇所を、R波のピーク候補として抽出する
(5) R波のピークから、次のR波のピークまえの時間間隔を、R波の各ペアから取得し、その中央値を1心拍の時間とする
(6) (5)で計算した時間の20%増し分のデータを、各R波ピークから取得する(この際、次のR波ピークにかかるようなら、そこ移行は切り捨てるよう)
(7) 事前に定義した固定長時間分のデータ配列に(6)のデータを積上げていく(この際、取得したデータが事前定義固定時間に足りない分は、ZERO埋めする)
これを分かりやすく図で説明してくれているのが以下です。
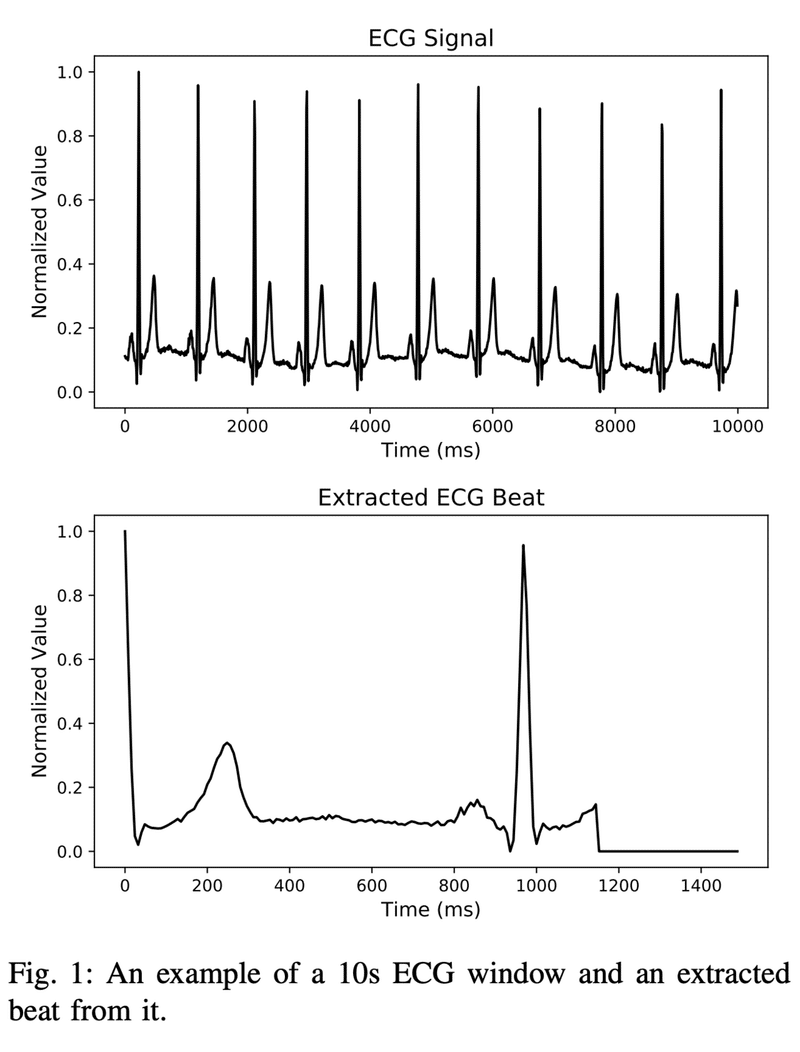
なるほど、参考になりますね。
そして、Kaggleのデータは、これをやってもらった後である訳ですね。
提案手法としては、CNNを使って解いてみたとのことです。
CNNのネットワーク構造は以下になります。
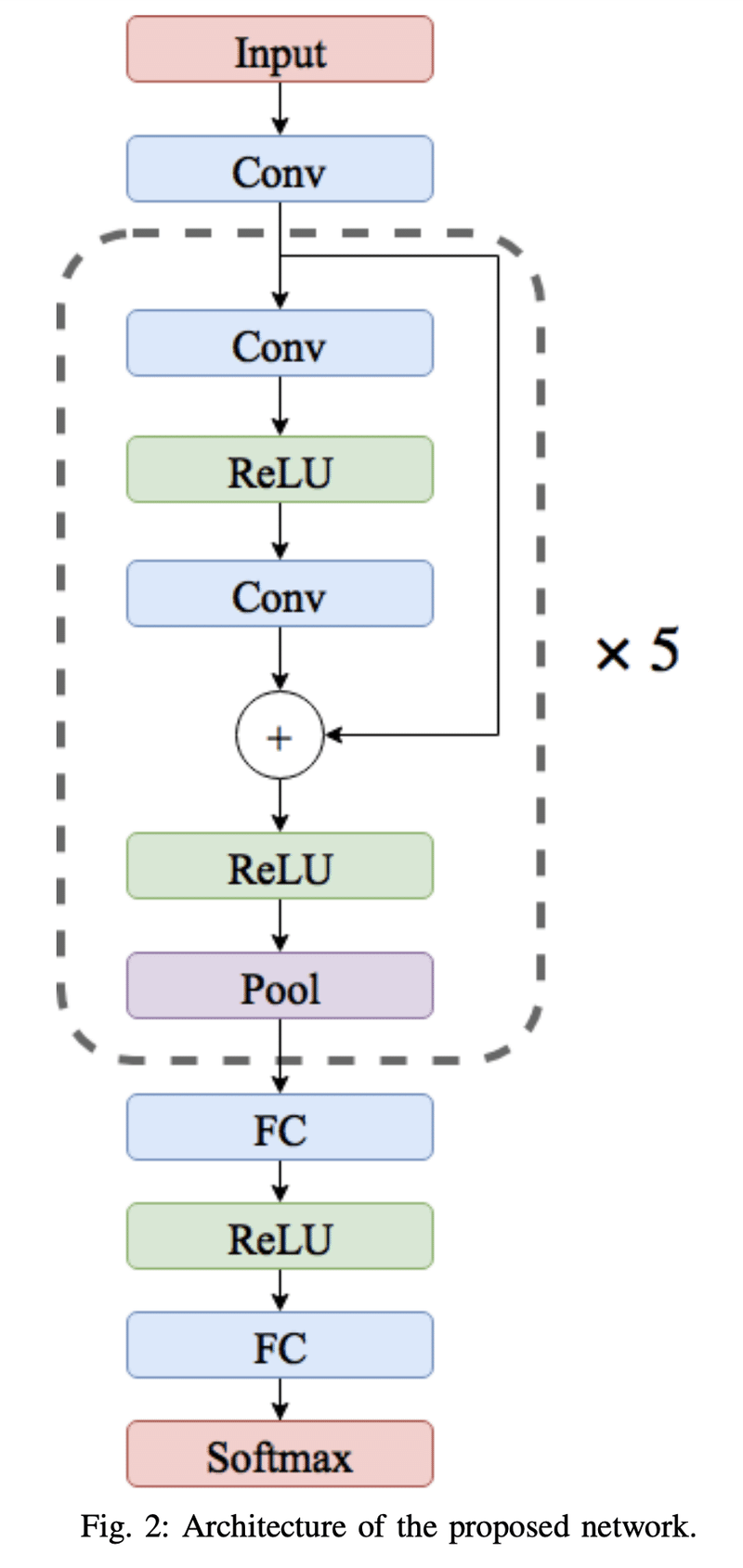
ResNetの考え方が導入されたネットワーク構造になっていますね。
精度については、かなりドメイン寄りの内容が記載されており、読み切ることができなかったのですが、要するには、ルーツが異なるデータセット間においても、提案手法はロバストな汎用性の高い精度が引き出せた、という主張のようです。
未知のデータに対しても、高い精度が期待できる、という形ですね。
Kaggle Notebookを見てみる
さて、次に、「ECG Heartbeat Categorization Dataset」のKaggle Notebook(解読例)を見てみます。
一番いいねの数が多かった、以下のKaggle Notebookを参考にしました。
行われてる処理内容の詳細については、私の方で上記Kaggle Notebookのプログラムに、日本語でコメント・解説を付与したものがありますので、そちらを添付します。
是非参照下さい。
ちなみに、添付のプログラムの実行は、Google Colaboratoryにて行いました。
GPUが無いと、学習に長い時間を要する為です。
Google Colaboratoryによるプログラム実施手順は、以下の記事にまとめてありますので、よろしければ参照下さい。
さて、上記Kaggle Notebookにて行われている処理内容を解説させていただくと、主に以下の内容でありました。
【処理内容】
(1) 基本的には、先程紹介した論文の内容を、丁寧に踏襲している
(2) 識別対象5クラス中の最も件数が少ないデータに対して、Data Augmentation(データ増幅)を実施し、擬似波形を生成することで、件数を増やしている
以上。
論文の内容が分かっている人にとっては、非常にシンプルな内容となっています。
Additional的に実施しているData Augmentation内容は、以下です。
【Data Augmentation内容】
(A) 1心拍毎の波形を、時間方向に伸縮させる
(B) 1心拍毎の波形の起伏部分(山)の幅を、狭めたり広めたりする
(C) ルーレット式で、(A)(B)のどちらかのみを実施したり、両方を実施したりする
図で表すと、以下です。
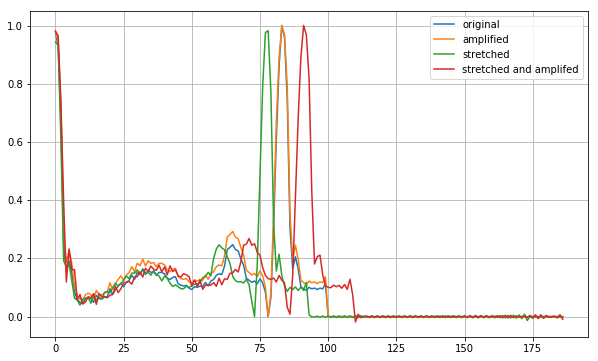
青色が、元々の波形です。
オレンジ色が、波形の膨らみを膨張させた形です。
オレンジ色は、膨らみが収縮されるパターンもあります。
例えば、キレイなsin波形に対して、それを行った場合、以下のようになります。
(赤色が元波形で、緑色がAugmentation波形を重ねて表示したもの)
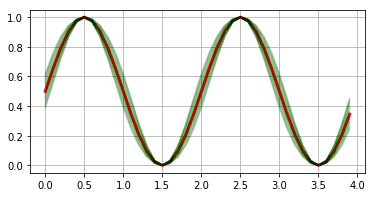
緑色は、波形の時間の伸縮を行っています。
上記の場合は、波形の時間長が短くなっています。
これは、長くなることもあります。
例えば、キレイなsin波形に対して、それを行った場合、以下のようになります。
(赤色が元波形で、緑色がAugmentation波形を重ねて表示したもの)
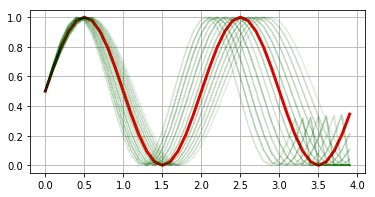
そして、赤色波形が、波形の振幅の膨張と、波形の時間長の増幅を、同時に実施したものです。
これらAugmentationの操作によって、擬似的にデータを増幅している訳です。
もし、この増幅によって作られる波形データが、実際に発生するであろう波形形状の内、学習データに含まれない波形形状を、上手く表せているとすると、汎化性能が向上するであろうことが期待できます。
プログラムの大事なポイントを、かい摘んで解説
上記、私が日本語のコメントを振ったプログラムですが、大事なポイントだけ、かい摘んで解説しようと思います。
先ず、以下のコード部分です。
# 図描画の際の、時間値を算出
# (データセットについて、サンプリングレートが「Sampling Frequency: 125Hz」と記載がある為、125で割っている)
# (参考:https://www.kaggle.com/shayanfazeli/heartbeat)
x = np.arange(0, 187)*8/1000
# 5属性のデータを1本ずつ表示
# figure(図描画出力先)を用意
plt.figure(figsize=(10,6))
# 属性1つ目、通常波形を表示
plt.plot(x, X[C0, :][0], label='Cat. N')
# 属性2つ目、異常波形パターンSを表示
plt.plot(x, X[C1, :][0], label='Cat. S')
# 属性3つ目、異常波形パターンVを表示
plt.plot(x, X[C2, :][0], label='Cat. V')
# 属性4つ目、異常波形パターンFを表示
plt.plot(x, X[C3, :][0], label='Cat. F')
# 属性5つ目、異常波形パターンQを表示
plt.plot(x, X[C4, :][0], label='Cat. Q')
# plot時に設定したlabel値を、描画図上に表記
plt.legend()
# 描画図のタイトルを出力
plt.title('1-beat ECG for every category', fontsize=20)
# 描画図のy軸タイトルを出力
plt.ylabel('Amplitude', fontsize=15)
# 描画図のx軸タイトルを出力
plt.xlabel('Time (ms)', fontsize=15)
# 描画図中に格子線を追加
plt.grid(True)
# 描画図を表示する(これをやらないと、図が表示されない時がある)
plt.show()
上記コードの結果が以下です。
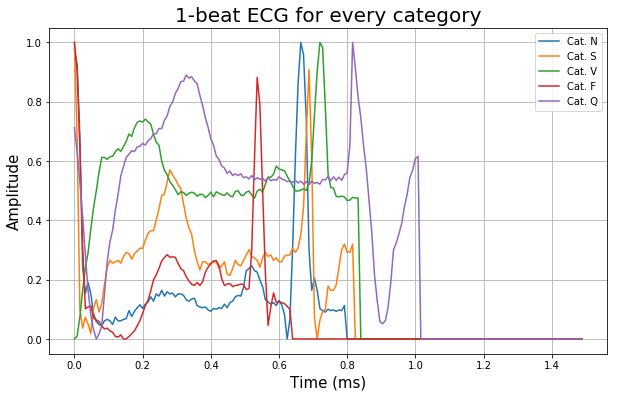
データには、正常クラス1つと、異常クラス4つの計5クラスのデータがあります。
上記コードは、それらを1レコードずつ表示しているものとなります。
また、データのサンプリングレートが125Hzと、Kaggle上のデータ説明に記載されている為、このデータは1秒間に125回のデータ取得が行われていることになります。
そこで、プロットする際のx軸の値は、波形データ長の「0〜186」を125で割ってあげたものを、秒数として扱うと帳尻が合います。
その計算を行っている部分が以下コードです。
# 図描画の際の、時間値を算出
# (データセットについて、サンプルレートが「Sampling Frequency: 125Hz」と記載がある為、125で割っている)
# (参考:https://www.kaggle.com/shayanfazeli/heartbeat)
x = np.arange(0, 187)*8/1000つまり、行ごとに、1要素目に入っているのは 0/125 = 0 秒のデータ、2要素目に入ってるのは 1/125 = 0.008 秒のデータ、3要素目に入っているデータは 2/125 = 0.016 秒のデータ、という感じになります。
更に、126要素目に入ってるのが 125/125 = 1 秒のデータ、最後の187要素目に入っているのは、186/125 = 1.488 秒のデータとなります。
波形データ1つ1つの長さは、1.5秒弱なんですね。
実際には、後半要素には波形データが含まれず、ZEROで補填されています。
そして、1回の心拍にかかる時間は、0.7〜1秒くらいが標準であるようなので、概ね辻褄が合っていそうです。
次に、以下コード部分です。
# 図描画の際の、時間値を算出
x = np.arange(0, 187)*8/1000
# 属性ごとにプロットする線の本数を指定
plot_num = 50
# 属性1つ目、通常波形を表示
plt.figure(figsize=(10,6))
# 属性ごとに表示する波形の数分ループ
for i in range(plot_num):
plt.plot(x, X[C0, :][i], color='r', alpha=0.1)
plt.plot(x, np.mean(X[C0, :], axis=0), color='r', linewidth=3)
plt.title('1-beat ECG for Cat. N', fontsize=20)
plt.ylabel('Amplitude', fontsize=15)
plt.xlabel('Time (ms)', fontsize=15)
plt.grid(True)
plt.show()
# 属性2つ目、異常波形パターンSを表示
plt.figure(figsize=(10,6))
# 属性ごとに表示する波形の数分ループ
for i in range(plot_num):
plt.plot(x, X[C1, :][i], color='g', alpha=0.1)
plt.plot(x, np.mean(X[C1, :], axis=0), color='g', linewidth=3)
plt.title('1-beat ECG for Cat. S', fontsize=20)
plt.ylabel('Amplitude', fontsize=15)
plt.xlabel('Time (ms)', fontsize=15)
plt.grid(True)
plt.show()
# 属性3つ目、異常波形パターンVを表示
plt.figure(figsize=(10,6))
# 属性ごとに表示する波形の数分ループ
for i in range(plot_num):
plt.plot(x, X[C2, :][i], color='b', alpha=0.1)
plt.plot(x, np.mean(X[C2, :], axis=0), color='b', linewidth=3)
plt.title('1-beat ECG for Cat. V', fontsize=20)
plt.ylabel('Amplitude', fontsize=15)
plt.xlabel('Time (ms)', fontsize=15)
plt.grid(True)
plt.show()
# 属性4つ目、異常波形パターンFを表示
plt.figure(figsize=(10,6))
# 属性ごとに表示する波形の数分ループ
for i in range(plot_num):
plt.plot(x, X[C3, :][i], color='c', alpha=0.1)
plt.plot(x, np.mean(X[C3, :], axis=0), color='c', linewidth=3)
plt.title('1-beat ECG for Cat. F', fontsize=20)
plt.ylabel('Amplitude', fontsize=15)
plt.xlabel('Time (ms)', fontsize=15)
plt.grid(True)
plt.show()
# 属性5つ目、異常波形パターンQを表示
plt.figure(figsize=(10,6))
# 属性ごとに表示する波形の数分ループ
for i in range(plot_num):
plt.plot(x, X[C4, :][i], color='m', alpha=0.1)
plt.plot(x, np.mean(X[C4, :], axis=0), color='m', linewidth=3)
plt.title('1-beat ECG for Cat. Q', fontsize=20)
plt.ylabel('Amplitude', fontsize=15)
plt.xlabel('Time (ms)', fontsize=15)
plt.grid(True)
plt.show()
このコードの実施結果が以下です。
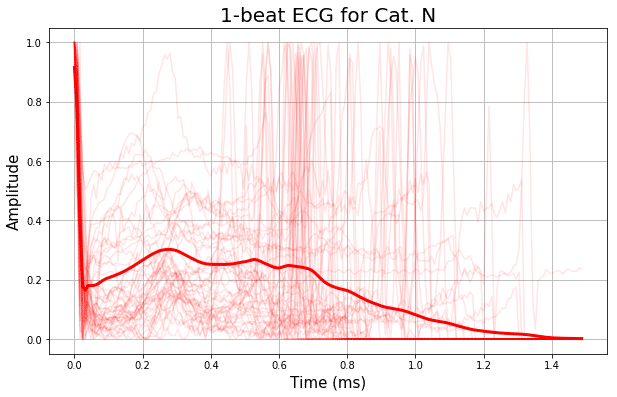
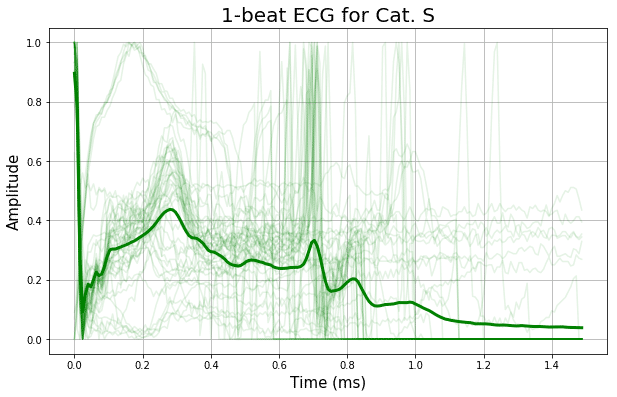
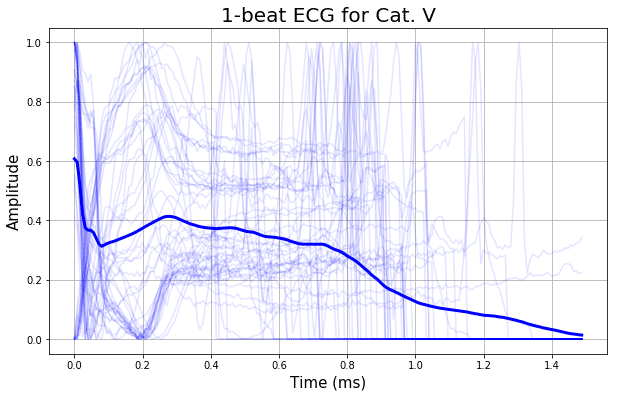
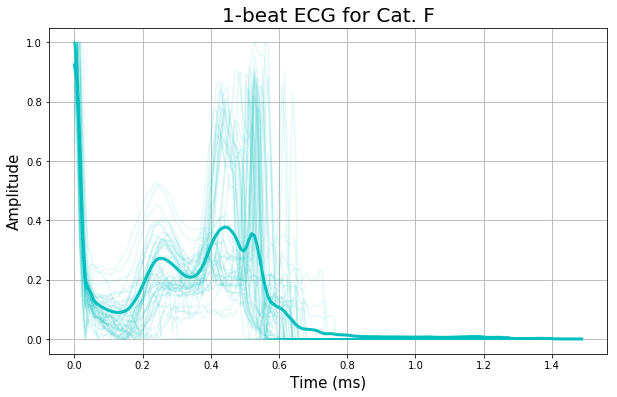
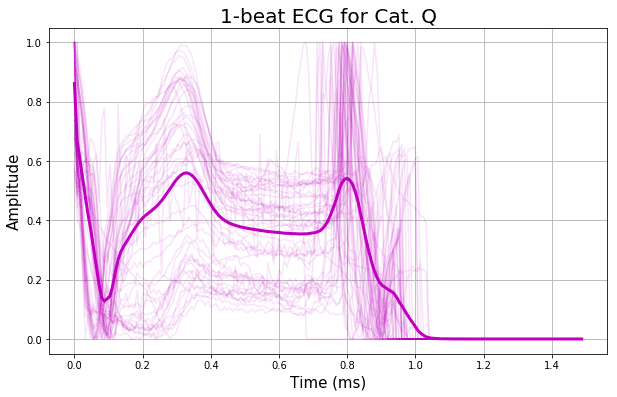
波形の5クラス別に、50本の実は計プロットを重ねて、細線で表示しています。
そして、各クラス毎の全ての波形の平均を、太線で表示しています。
どうでしょうか?
平均を示す太線の形状を見ると、割と特徴的な違いが見て取れますよね。
この時点で、この識別は上手くできそうだな、という予感を感じさせます。
波形の長さは人それぞれなので、着目すべきは前半(0.5秒位まで)でしょうか。
このように、分析の感触を直感的に掴むことは、とても大事なことであると思います。
そして、最後に、学習した識別器の精度を示しているConfusion Matrixです。
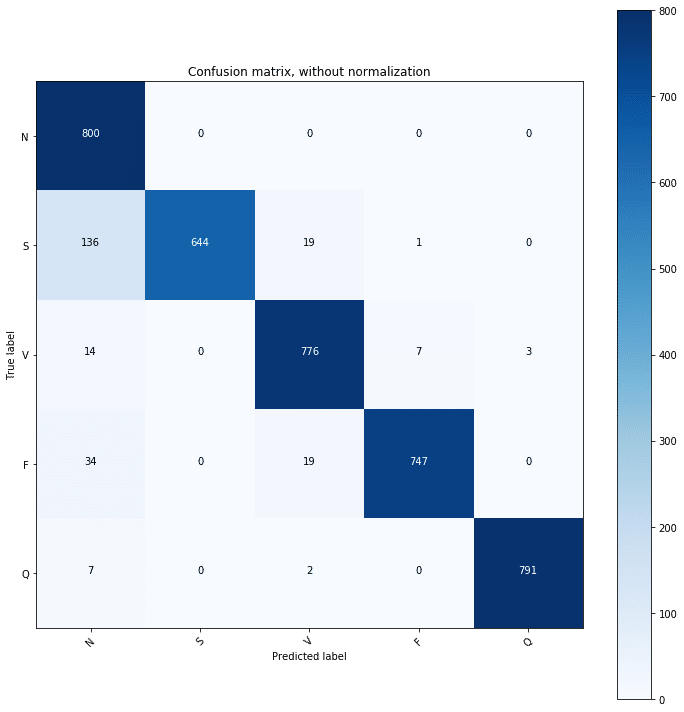
縦軸が予測クラスを表しており、横軸が正解クラスが表しております。
よって、予測クラスと正解クラスの一致を意味する、対角線上の件数が正解数を意味します。
かなりの件数が、対角線上に集まっていますね。
精度の高い識別ができていると言えるでしょう。
(尚、このConfusion Matrixは、Random Seedによって、結構ブレるようなので、実応用をする際には、その辺りをご注意下さい。)
大事なポイントのかい摘み解説は、以上となります。
おわりに
ここまで読んでくださった方、ありがとうございました。🙇
以上にて、Kaggleの「ECG Heartbeat Categorization Dataset」の掘り下げのレポートを終えます。
Kaggle Notebookは、じっくり辿ってみると、実装者の思いなども見えてきて、非常に勉強になります。
これからも、沢山のKaggle Notebookを掘り下げていきたいと思います。
この記事が気に入ったらサポートをしてみませんか?