
Google Colaboratoryの無料GPUで、Deep Learningをしよう

はじめに
皆さん、こんにちは。
最近、Googleから、GPUを無料使用できるトンデモないヤツがリリースされました。
今回は、それを使って、Deep Learningを実施するまでのステップを、書かせていただこうと思います。
誰でも、無料で、どこでもGPUが使えます!
GPUとは?
GPUとは、特にデータ分析界隈で注目されている、コンピュータの計算機構のことです。
一般的なのはコンピュータの計算機構はCPUですが、一部の計算形式についてはGPUを併用することで、数倍から100倍以上の計算速度向上が見込めます。
詳しくは、以下の記事がとても分かりやすいです。
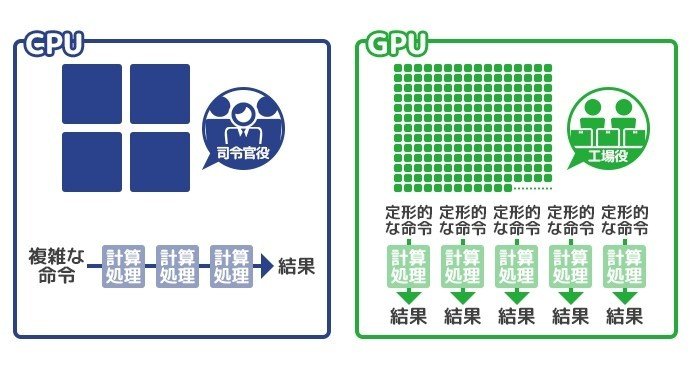
CPUとGPUの違いを抽象的に説明すると、以下です。
(私の師匠の内の1人が、私にしてくれた素晴らしい例え)
CPU:研究者くらい頭の良い計算機構が、1個から数十個で構成される
GPU:小学生くらいの単純計算ができる計算機構が、数千個で構成される
複雑な計算はCPUの方が早い、或いは、CPUじゃないとできなかったりするのですが、単純な計算を数多く処理させるにはGPUの方が早いのです。
先程紹介したページでは、その概念を以下図で表現されています。
ちなみに、GPUは元々コンピュータの画面描画に使われていた計算機構でした。
画像をパッパッと遅延なく描画するために、画像1ピクセル1ピクセルの描画という単純な処理を、並列に処理してそれを実現していたものです。
転じて、単純な計算を一気に行うのに向いているという特性を、特に最近注目されているDeep Learningという技術にフォーカスして、フィットさせたのが技術的なブレイクスルーを引き起こしました。
実はDeep Learningは、全体として見ると複雑な計算機構ですが、最小単位の計算は並列化が可能な単純計算(主に、掛け算と足し算)になるのです。
Deep Learningとは?
Deep Learningとは、一言で言うと、AIを構築するための1手法のことです。
1アルゴリズムとも言えます。
人間の営みを再現、或いは、高速化しようとするのがAIです。
それによって、人間の営みの一部を機械に代替してもらう、或いは、高速化してもらおうというのがAIの目的です。
尚、AIは第四次産業革命と言われていますが、新しい技術によって、なにがしかを自動化・高速化するという流れは、これまでの産業革命と共通するものです。
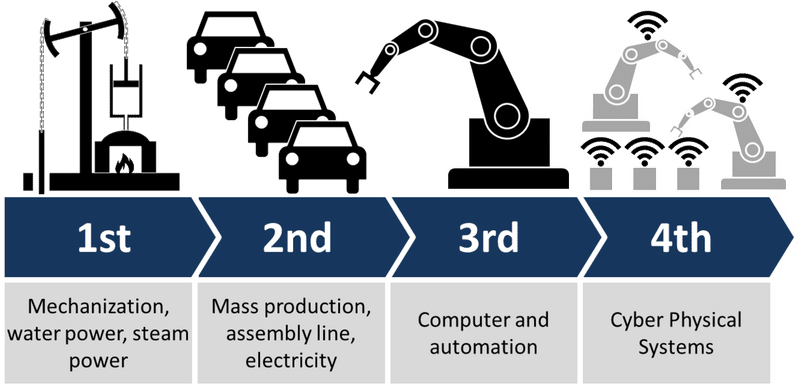
そのAIの実現方法として、最も注目されている手法が機械学習です。
自動化・高速化に向けて重要となる、物事の法則性・ルール・パターンについて、それらを自動的に学び取る機構が、機械学習です。
考えることに特化したAIと言っても良いでしょう。
そして、その機械学習の中で最も注目されている手法がDeep Learningになります。
人間の脳構造をコンピュータ上に再現してみる、という考えの基に成り立つアイデアです。
理論自体は、実は1980年代に確立されていたのですが、コンピュータの計算速度が理論に追い付かず、昨今まで冬の時代を迎えていました。
そのDeep Learningに春を迎えさせたのは、昨今のコンピュータ技術の発展であり、GPUです。
最近のDeep Learingは、特定のケースにおいて、人間の認識性能を超えたという研究結果がチラホラ出てきていますね。
Deep Learningが、人間の営みをガンガン代替していく時代も、そう遠くないのかもしれません。
ちなみに、今紹介した、AI・機械学習・Deep Learningの関係性については、以下ページが分かりやすく説明してくれています。
その中にある図が、とても秀逸です。
しかしながら、GPUは値段が高い…
世の中的に、GPU ✕ Deep Learningが流行っていますが、それは企業の取り組み等で、一般の人がサクッとそれを実施するには、まだ高いハードルがあります。
それは、GPUの値段です。
GPUは高価なのです。
例えば、Deep Learningを実施する上では、エントリーとプロの間くらい、ミドルスペックのPCで、40万円弱します。
プロスペックだと、100万以上の青天井です。
とても、軽い気持ちでは向き合えない値段ですね。💦
尚、GPU搭載のクラウドを使う手もあります。
短期的に試用するには良いかと思いますが、うっかり使い過ぎると金額が跳ね上がるので注意が必要です。
個人的には、オススメしません。
GPUが無料で使えるGoogle Colaboratory
しかし、そんなGPUが無料で使用できる機構をGoogleがリリースしました。
それが、Google Colaboratoryです。
なんとも、信じられないサービス精神です。
私が時代に追い付いていないのか、Google様が御乱心なのか。
なにはともあれ、使えるものは使わせていただきましょう。🙏アリガタヤ...
Google Colaboratoryに関する詳しい説明は、以下の記事が分かりやすいです。
ポイントとして抑えとくべきは、以下かと思います。
(1)Colaboratoryは、Jupyter Notebookと同じ感じで、Pythonが実行できる
(2)GPUは、Google Colaboratory上の設定を変更すれば、使うことができる
(3)Colaboratoryを起動できるのは、最長12時間
(4)Google Drive上に置いてあるファイルを読み込んだり、Google Drive上にファイル出力できたりする(※途中経過が保存できる)
(5)ライブラリのインストールは、Colaboratory上で「!pip install hogehoge」などとする
(6)利用状況は、「!df -h」「!free -h」「!nvidia-smi」などで監視する
以上。
このポイントは、いきなり言われてもピンと来ない人もいるかと思います。
以降の手順上にて、実際に手を動かしながら、上記ポイントについては説明をしていこうと思います。
それでは、早速、GPUを使うまでのステップを実行していきましょう。
GPU ✕ Deep Learning向きのデータを、Kaggleから選定し、Downloadする
GPU ✕ Deep Learningを試すのに、丁度良いのデータがないか、Kaggleを探ってみました。
Kaggleは、世界中の企業や研究者が投稿したデータを、世界中のData Scientistが解き、その精度を競い合うというコンペサイトです。
中には、賞金を提供しているテーマもあり、データ分析界隈で話題騒然となっています。
色々見ていると、うってつけの波形分析データがあったので、それを採用することにしました。
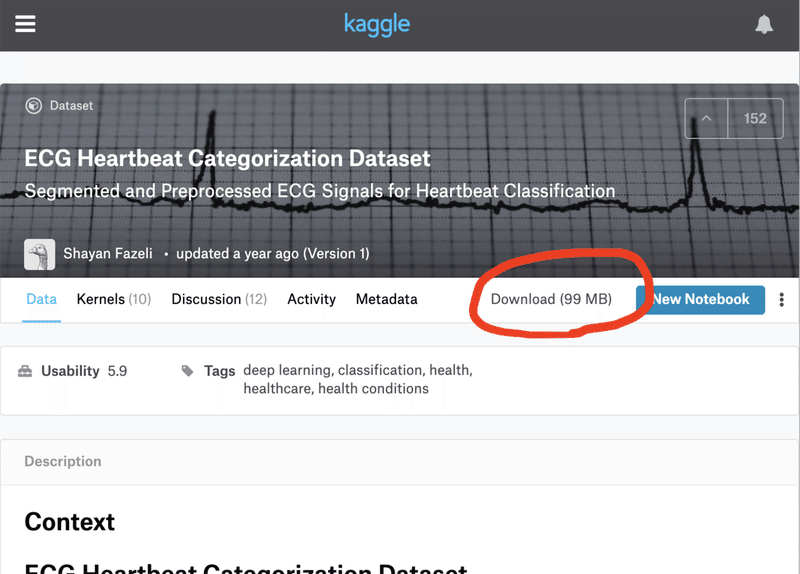
データのダウンロードページは以下です。
心拍の波形データで、正常な場合と、異常な場合(不整脈や心筋梗塞など4種)とを識別するテーマになっています。
データのダウンロードは、ページ上の「Download (99 MB)」をクリックすれば、実行できます。
そして、上記データに紐付くKernelとしては、以下が存在しました。
Kernelとは解法例のことで、「このテーマを、私はこう解きましたよ」という分析のステップが、公開されているものです。
非常に有り難いですね。
Kernelの内容は、波形データに対して、Deep Learningを適用して、波形の識別を実現しているというものです。
精度としては、概ね90%を超える正解率が出ています。
同じ精度が出るかどうか、Google Colaboratoryで試してみましょう。
尚、Kernelソースは、右上のメニューからダウンロードすることができます。
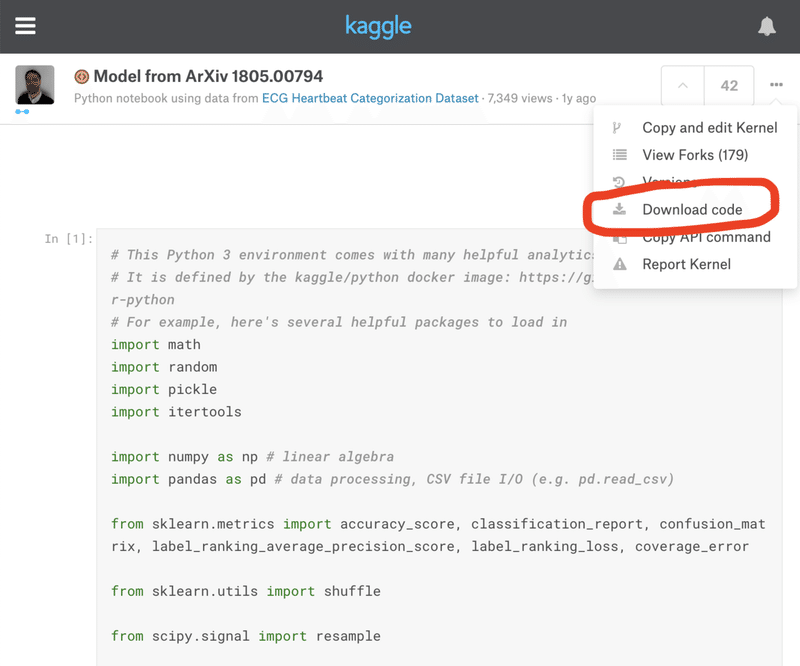
KaggleからDownloadしたデータとプログラムをGoogle Drive上にUPする
KaggleからデータとプログラムがDownloadできたら、それらをGoogle Drive上にUploadしていきます。
先ず、Google Driveを起動します。
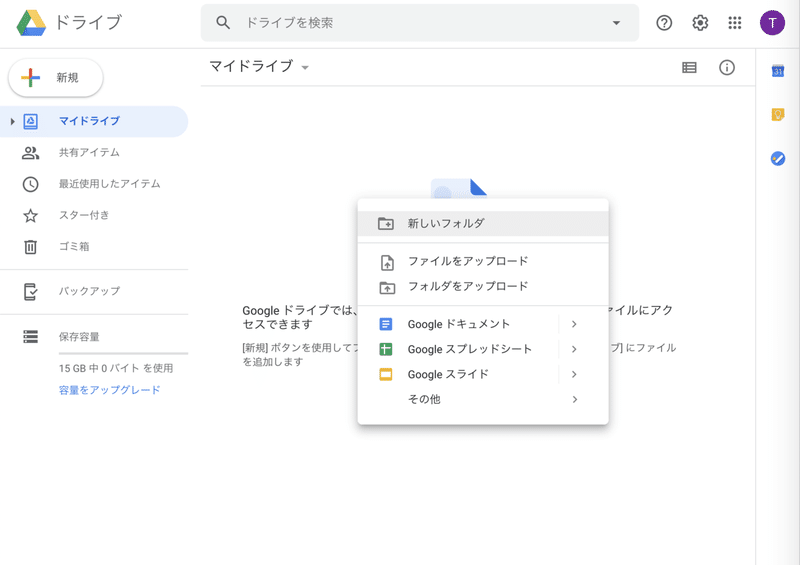
そして、Google Driveのマイドライブ上に、workフォルダを作りましょう。
私は、「colab_work」というフォルダ名にします。
真ん中辺りで、右クリックをして、「新しいフォルダを作成」を選択して…
フォルダ名称に、「colab_work」と入力して、作成ボタンを押します。
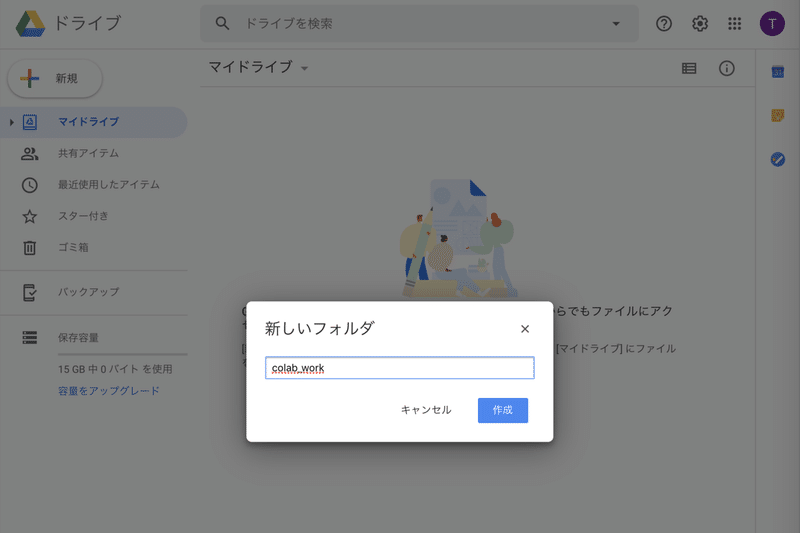
すると、フォルダが作成されました。
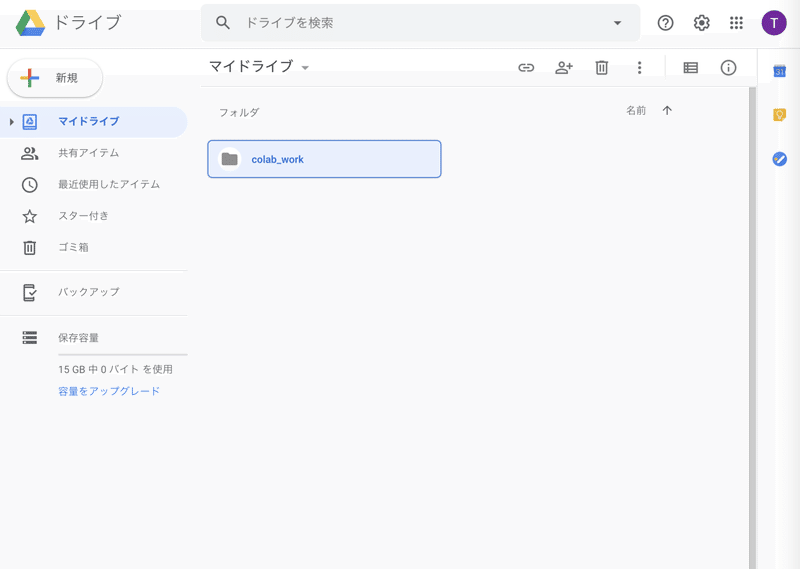
次に、そのフォルダ配下に、KaggleからDownloadした以下をUploadします。
データ(フォルダ):heartbeat
プログラム(ファイル):model-from-arxiv-1805-00794.ipynb
Uploadは、ドラッグ&ドロップで実施できます。
Uploadが済むと、こんな感じになります。
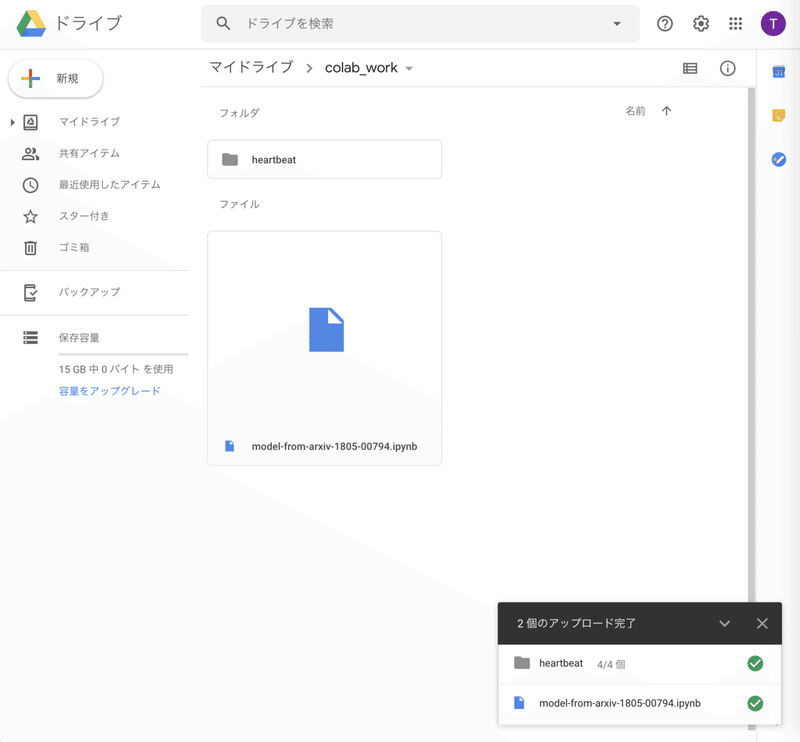
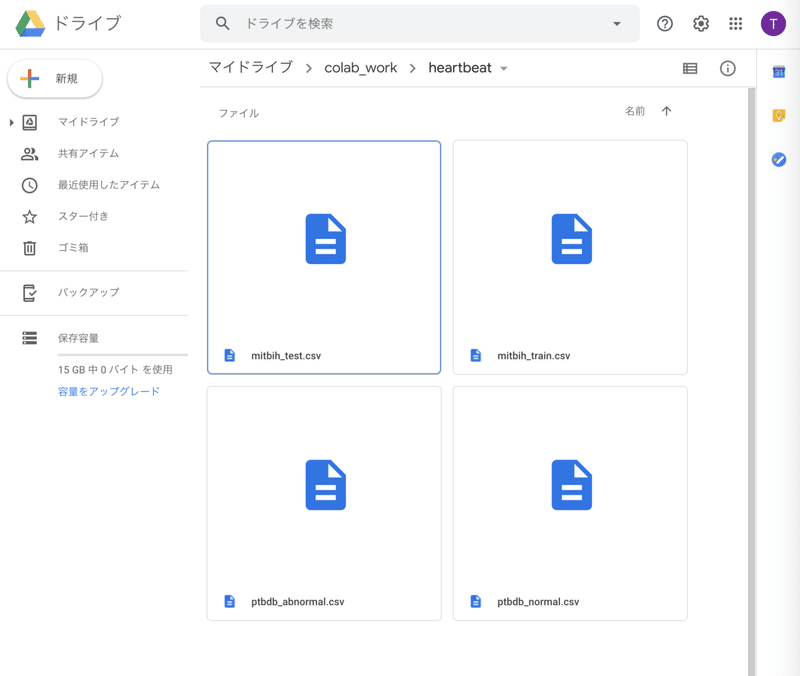
尚、heartbeatフォルダの中には、以下のように4つのファイルが格納されています。
これで、プログラムを実行する準備は完了しました。
Notebookプログラムを、colaboratoryで起動する
「colab_work」フォルダ上にある、「model-from-arxiv-1805-00794.ipynb」ファイルを、ダブルクリックします。
そうすると、以下にように画面遷移をしますので、画面上部の「アプリで開く ▼」を選択します。
すると、メニューが開きますので、更に「その他のアプリを接続」を選択します。
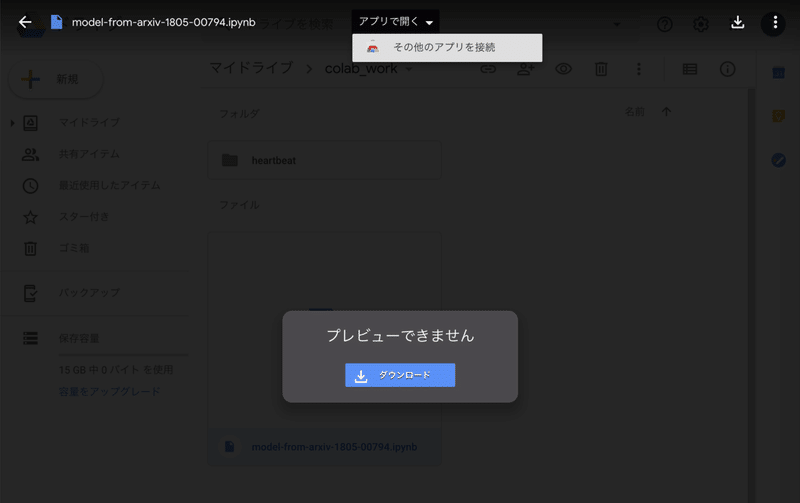
すると、アプリの選択画面に遷移します。
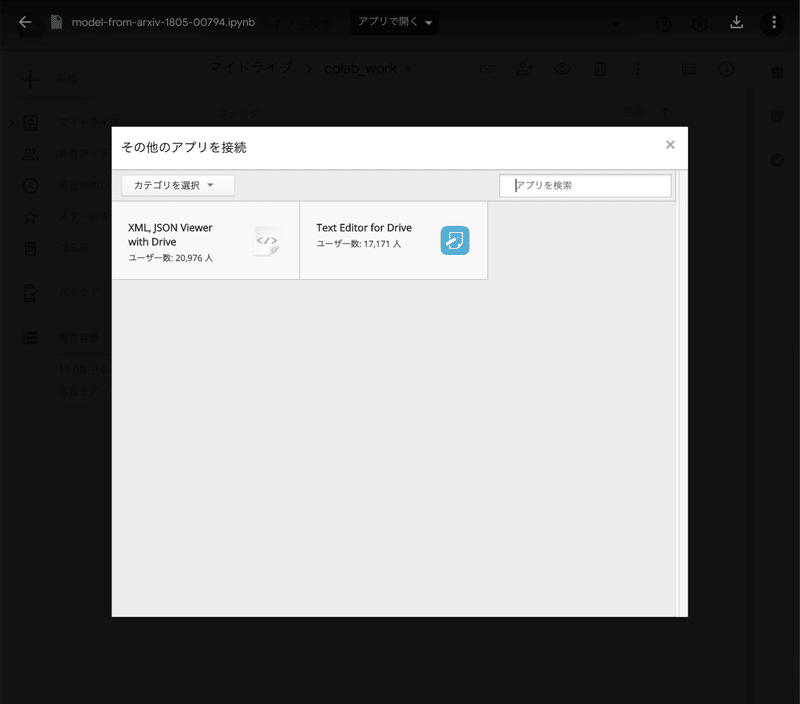
Google Colaboratoryをアプリ起動したいので、「アプリを検索」と書かれた検索窓に「colab」と入力してEnterキーを押します。
すると、Google Colaboratoryが現れます。

ここで、「+ 接続」ボタンを押します。
すると、以下のように画面遷移します。
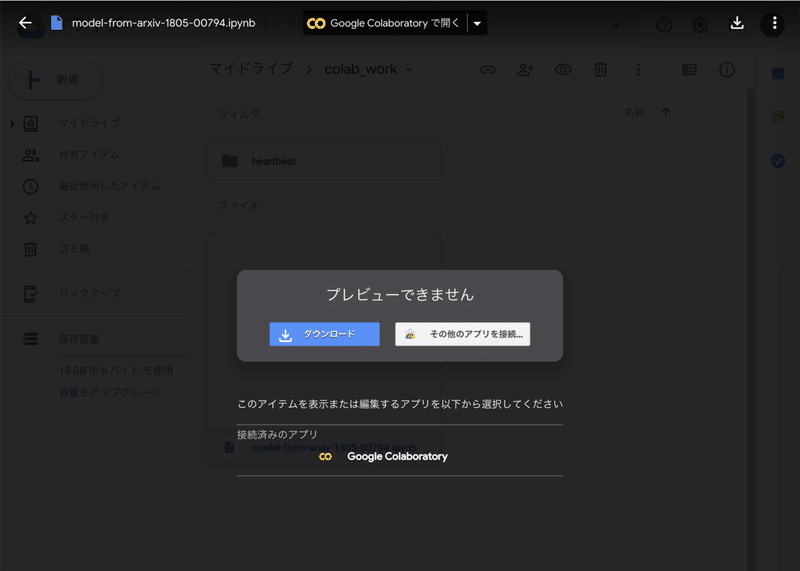
ここで、上部の「Google Colaboratoryで開く」か、画面中段下部の「Google Colaboratory」をクリックすると…
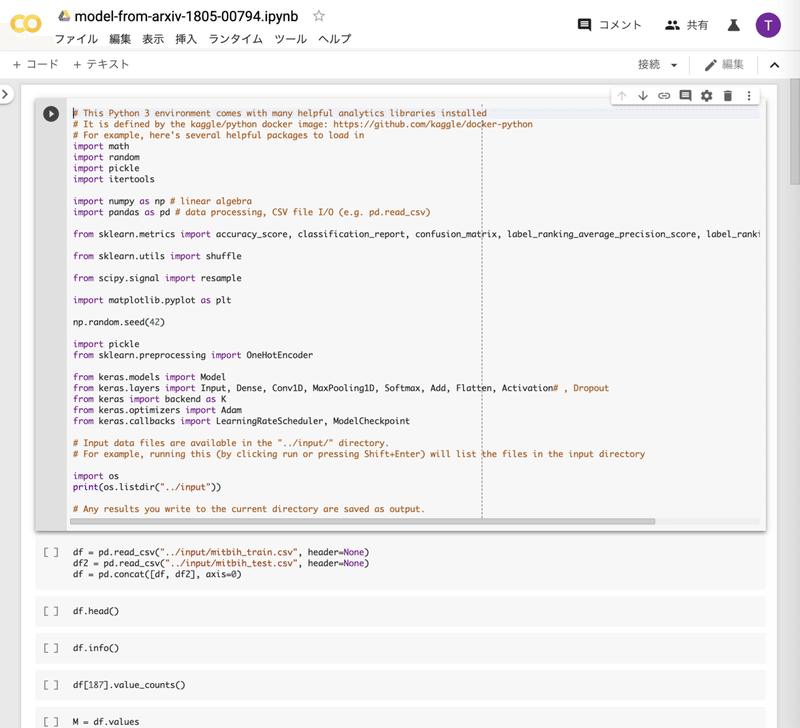
プログラムが、Google Colaboratoryによって開かれました。
Notebookプログラムを、GPUで動くように設定する
さて、プログラムをすぐにでも起動してみたいところですが、まだ準備が足りていません。
というのも、Google Colaboratoryをただ開いた状態では、GPUが使える設定にはなっていません。
そこで、GPUを使用するよう設定を行う必要があります。
GPU使用設定の手順は、先ず、Google Colaboratory上の上部メニューから、「編集 → ノートブックの設定」を選択します。
そうすると、以下のように画面が遷移します。
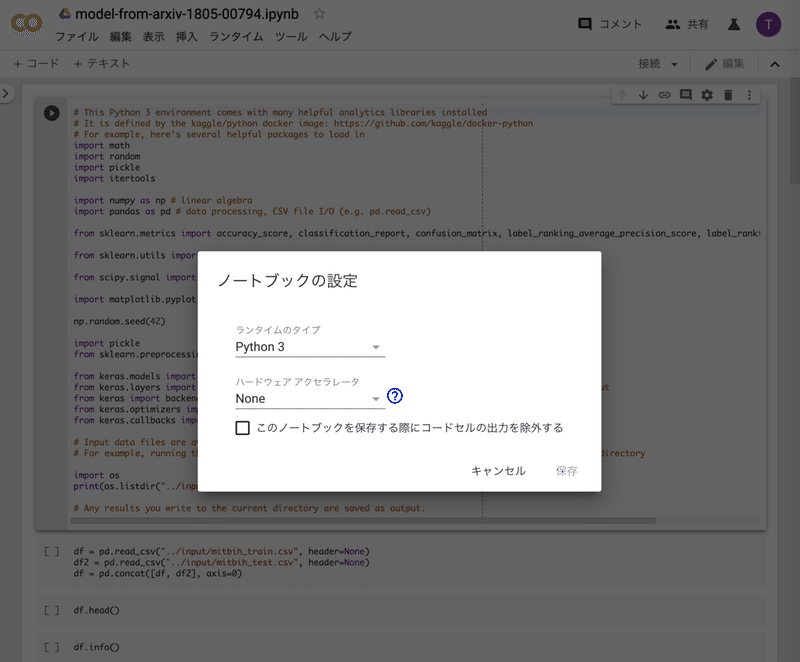
ここで、「ハードウェア アクセラレータ」の設定を、「GPU」に変更します。
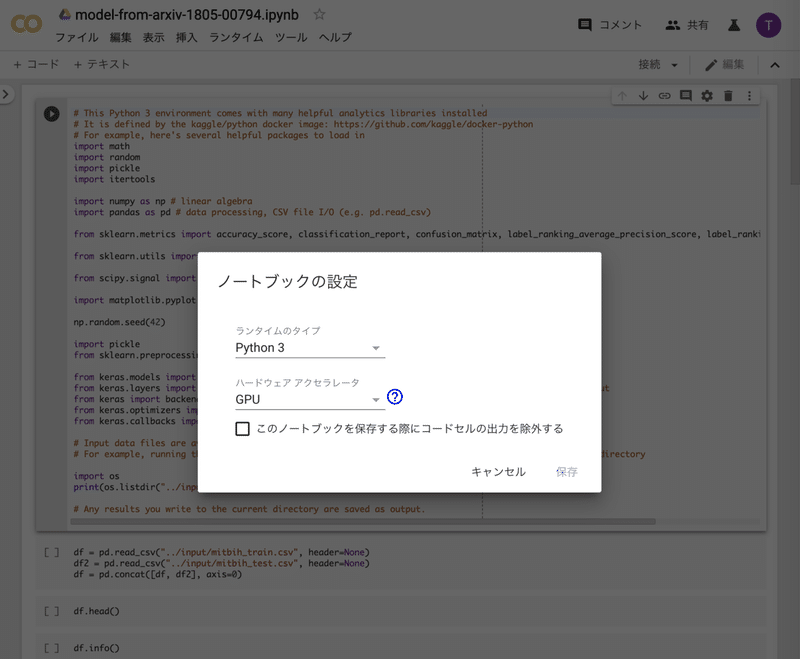
そして、「保存」をクリックします。
これで、GPU使用設定は完了です。
その上で、Google Colaboratoryの上部メニューになる「接続」をクリックします。
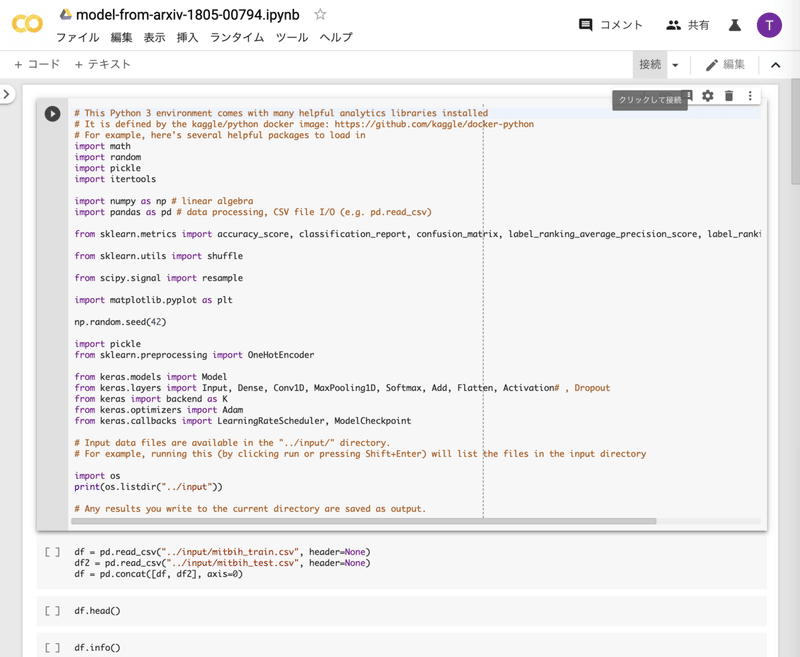
そうすると、画面上部が以下のように遷移します。
これで、実際にGPUが割り当てられました。
尚、先程紹介したGoogle Colaboratoryの解説記事によれば、ここから12時間はGPUが使えるとのことです。
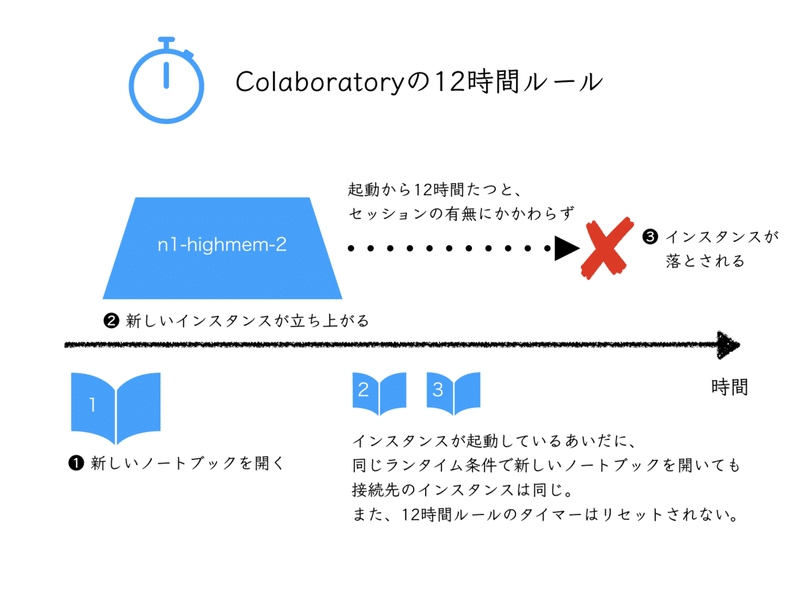
仮に、12時間で終わらない処理を投げたとしても、途中結果を出力しておき、それを元に処理を再開できれば、実質上は無限時間を用して処理を行うことが可能です。
Notebookプログラムから、マイドライブのデータが参照できるようにマウントする
さあ、それではいよいよプログラムを起動!…と行きたいところですが、もう1ステップだけ準備が必要です。
というのも、現在の状態は、Google Driveのデータを参照できるようになっていないので、入力データの読込みや、出力データは吐出しができない状態なのです。
そこで、あなたのGoogle Drive上の「マイドライブ」を参照できるように、Google Colaboratory上でマウントという処理を行います。
マウントとは、そもそもは繋がっていない記憶領域と計算装置を、接続する操作のことです。
Google Colaboratoryは、Googleが所有するサーバーのGPUを拝借して、プログラムを実行する仕組みですが、その拝借先サーバーとあなたのGoogle Driveとはそもそもは繋がっていないので、それを接続させてあげる必要があるのです。
マウントは、プログラムの冒頭にセルを追加して、以下コードを追加することで実施できます。
from google.colab import drive
drive.mount('/content/drive')
では、やってみましょう。
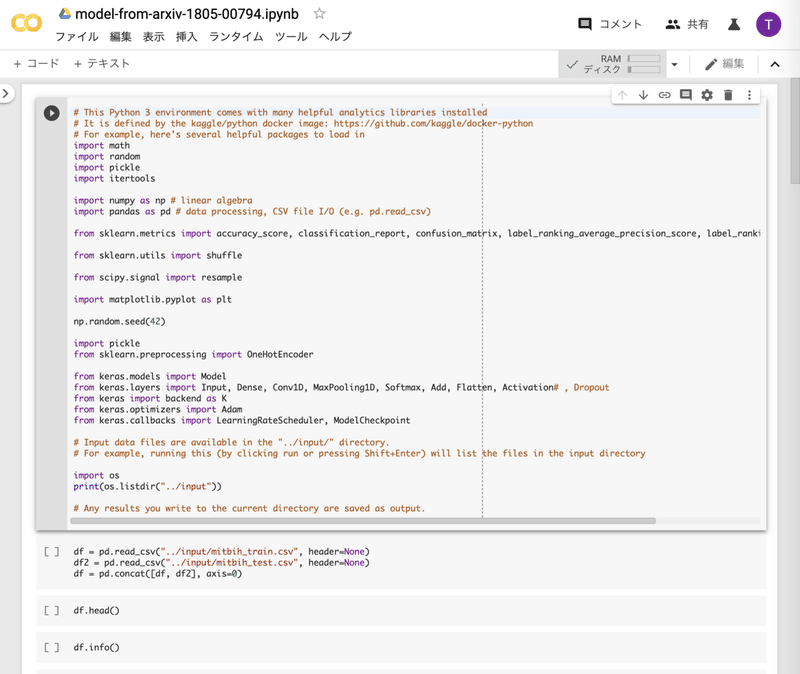
先ず、プログラムの最初のセルを選択した状態で…
左上の「+ コード」をクリックします。
すると、新たにセルが1つ追加されます。
そのセルを冒頭に持っていきたいので、セルの右上部にくっついているメニューの「↑」をクリックしますと…
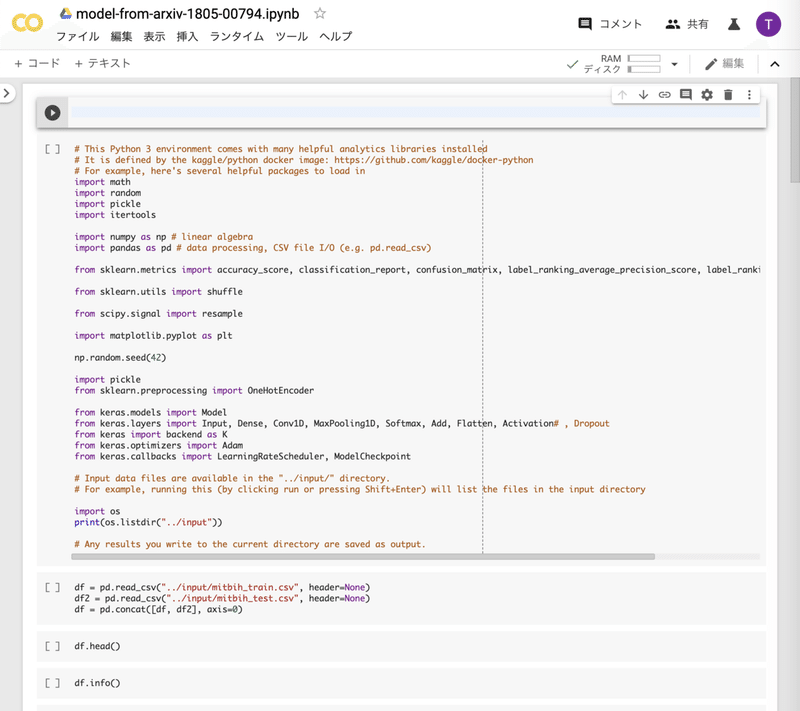
このように、セルに1つ上段に上がり、空セルが最上部に来ました。
このセルの中に以下のコードをコピーします。
from google.colab import drive
drive.mount('/content/drive')
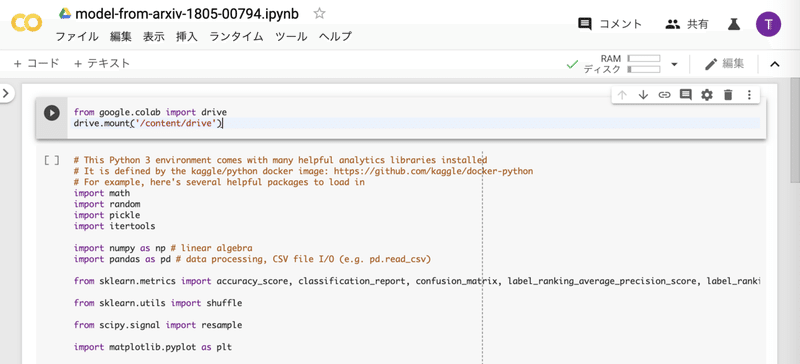
そして、冒頭のセル上で、Shift + Enterキーを押します。
そうすると、そのセルのコードが実行されます。

ここで、「Go to this URL in a browser: https://...」と記載されている右側の青字のURLをクリックして下さい。
すると、アカウントの選択画面が現れますので、マイドライブを参照して欲しいGoogle Driveの所有ユーザーを選択します。
また、Google Drive File Streamからのリクエストは、「許可」をします。
そうすると、以下のような画面に辿り着くかと思います。
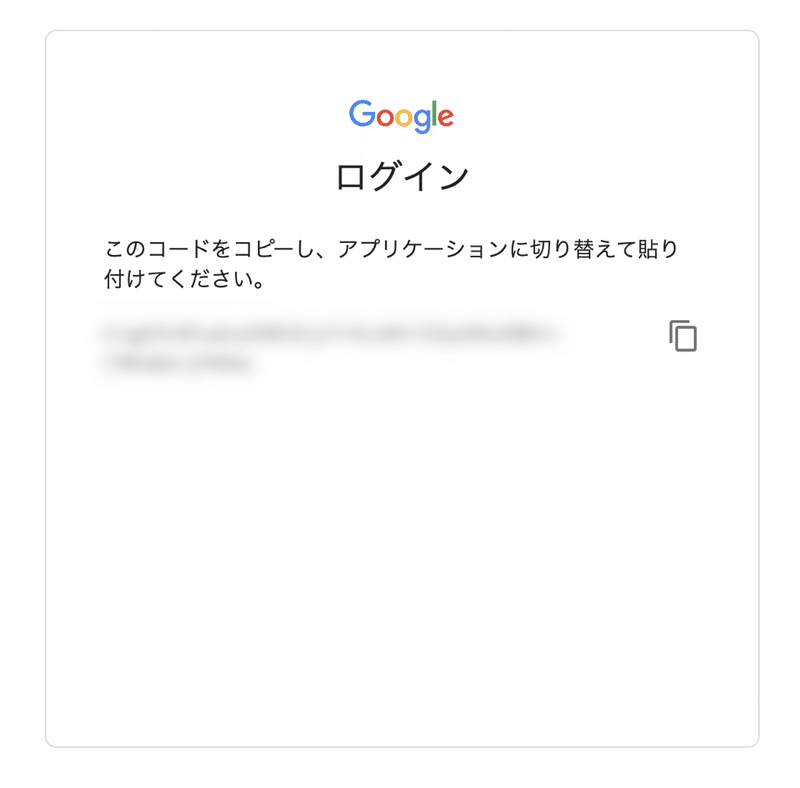
ここに記載されているコードを、Google Colaboratoryにて「Enter your authorization code:」となっている箇所に入力します。

そして、Enterキーを押すと、以下のように「Mounted as /content/drive」と出力されます。
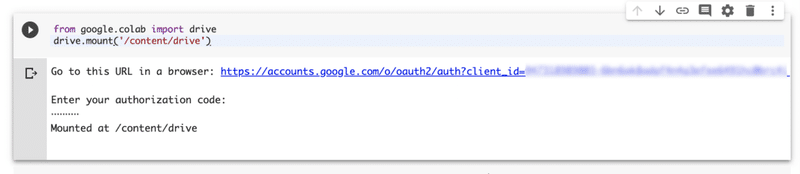
これで、あなたのGoogle Driveのマイドライブがマウントされました。
上記のコード実施にて、マウントされた状態にて、「!ls './drive/My Drive/colab_work/'」とコード実施をすれば、作成したフォルダへとアクセスすることができます。

これで、あなたのGoogle Driveのマイドライブと、Google Colaboratoryが接続されました。
Notebookプログラムのコードをちょっと直して、上から下まで実行する
さあ、それではプログラムを実施しましょう!…と行きたいところですが、最後にほんのちょっと微調整が必要です。
(これがホントに最後です💦)
その調整は、データの参照先フォルダ指定です。
プログラム中に以下のコードがあると思いますので、それを変更して下さい。
(修正前・其の1)
import os
print(os.listdir("../input"))
↓
(修正後・其の1)
import os
print(os.listdir("./drive/My Drive/colab_work/heartbeat/"))
もう一丁、修正です。
(修正前・其の2)
df = pd.read_csv("../input/mitbih_train.csv", header=None)
df2 = pd.read_csv("../input/mitbih_test.csv", header=None)
df = pd.concat([df, df2], axis=0)
↓
(修正後・其の2)
df = pd.read_csv("./drive/My Drive/colab_work/heartbeat/mitbih_train.csv", header=None)
df2 = pd.read_csv("./drive/My Drive/colab_work/heartbeat/mitbih_test.csv", header=None)
df = pd.concat([df, df2], axis=0)
以上。
上記修正を行えば、後はプログラムを上から下まで流すことができます。
大体5分前後で、全ての処理が流れきるかと思います。
最終的に、学習に使用していないテストデータにて、90%超の正解率を叩き出しています。
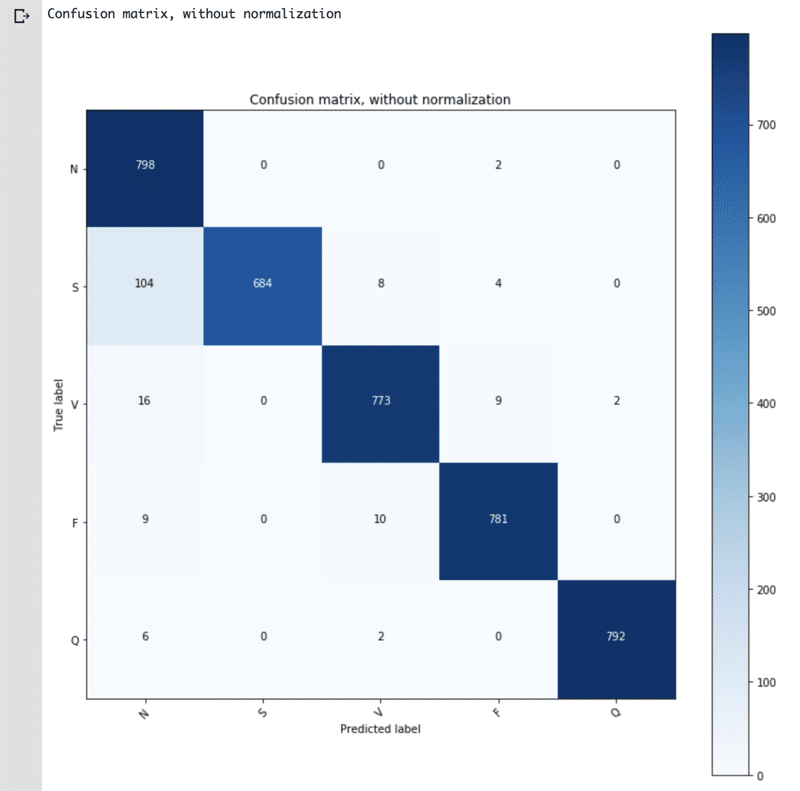
リソース使用状況を見てみる
最後に、コンピュータリソースがどのくらい使用されているのか確認してみましょう。
先程、実施したプログラムの末尾に、コードを追加していきます。
(以下の感じで)
先ず、物理メモリです。
以下コードを実行することで、実現できます。
!free -h結果は、以下のようになります。

物理メモリとは、大まかに言えば、計算対象としてコンピュータ上に展開できるデータ量のことです。
上記であれば、全体として物理メモリが12Gあり、使用されているのが3G、余っているが10G(ザックリ)という感じです。
データ量が多すぎると、メモリがパンクして異常終了してしまうことがありますので、このコマンドを使いながら、状況を確認することが大事です。
次に、GPUの使用量です。
以下コードを実行することで、実現できます。
!nvidia-smi結果は、以下のようになります。
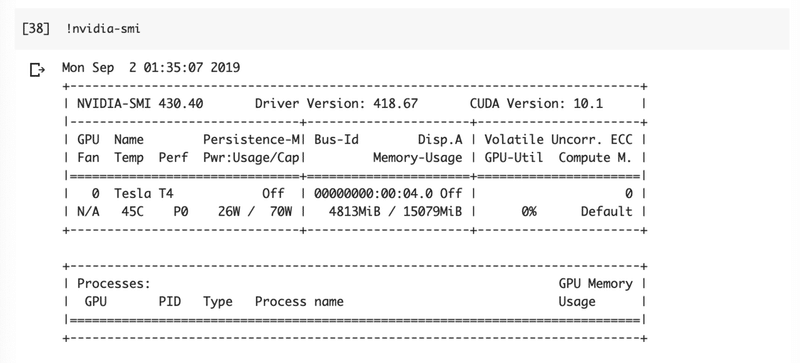
GPUのメモリは、「4813MiB / 15079MiB」と書かれている部分の左側が使用量、右側が全体量です。
使用量が全体量を上回ると、物理メモリ同様、パンクして異常終了します。
今回実施した例で言うと、まだもう少し余裕があったようです。
おわりに
ここまで読んでくださった方、ありがとうございました。🙇
以上にて、Google Colaboratoryでのプログラム実施方法について、理解いただけたかと思います。
おまけ
その後、Google Colaboratoryを使っていて、エディターのフォントが見づらいという問題に直面しました。
その解決方法を追記したいと思います。
Google Chromeの方であれば、「chrome://settings/fonts」をURLに打ち込んで下さい。
そうしますと、以下のようなフォントの設定画面に映ります。
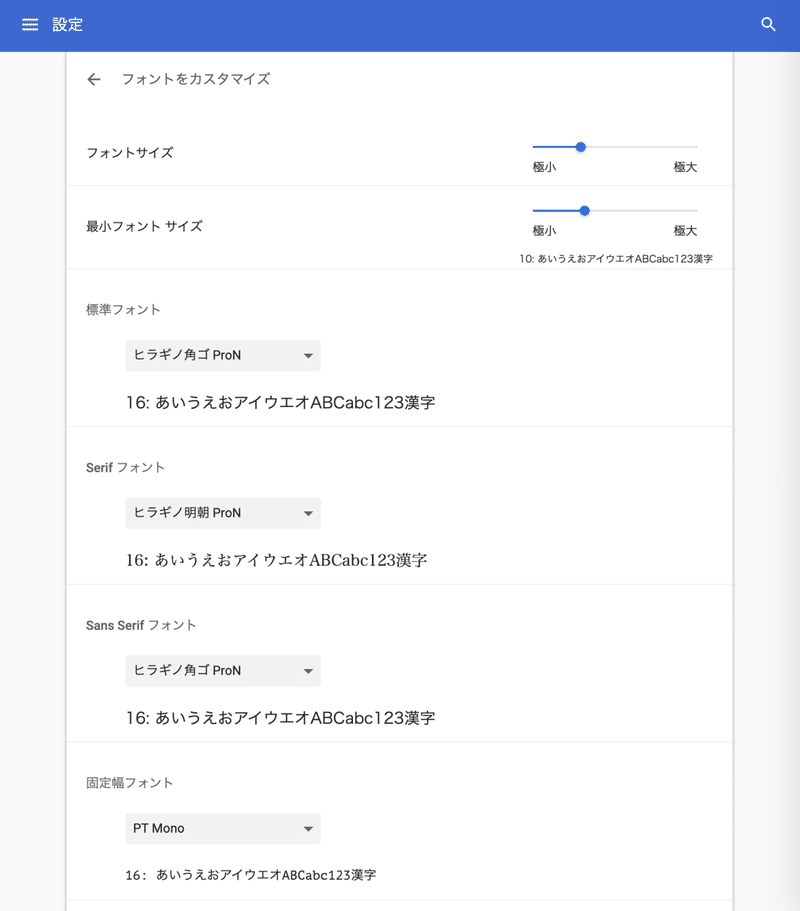
この画面の固定幅フォントが、Google Colaboratoryのエディターフォントに反映されます。
私が色々試してみて、見やすかったのは上記の「PT Mono」でした。
元々は「Osaka」が設定されています。
是非、お試し下さい。
この記事が気に入ったらサポートをしてみませんか?