
愛犬が好きすぎるのでAIで画像と音楽を生成してYouTube動画を作った

はじめに
この記事はnote株式会社 Advent Calendar 2023の10日目の記事です。
もう年末ですね。
AIの進化が激しすぎて夢と希望と絶望を思い知った年でした。
まぁ色々ありましたが、年の最後にはお世話になった方へ日頃の愛と感謝を伝えたいですね
ちなみに私が特に感謝しているのは、4月に我が家にやってきた
保護犬の柴犬らいぞうくんです。
インスタに可愛さが溢れ出ていますが
私の日頃のストレスを癒してくれるセラピー柴です。

らいぞうくんへの愛と感謝が強すぎて画像や動画もたくさん持っているので、生成AIを駆使してらいぞうくんに関するYouTube動画を作りました。
その内容をこの記事に書こうと思います(?)
結論(早く知りたい人向け)
◼︎ YouTube動画の中で使う音楽の生成については、MusicGenという音楽生成モデルを使用。音楽用語に詳しくないので、独自GPTsを作って音楽生成プロンプトを生成しました。
Music Prompt Generator
そして音楽生成プロンプトを使ってYouTube用の音楽を生成しました。
◼︎ YouTube動画の中で使う画像の生成については、Stable Diffusion XLという画像生成モデルを使用。愛犬の画像でチューニングする必要があったのでStable Diffusion XLをLoRAを使ってチューニングしました。芸術用語に詳しくないので、独自GPTsを作って画像生成プロンプトを生成しました。
Image Prompt Generator
そして画像生成プロンプトを使ってYouTube用の画像を生成しました。
◼︎ 愛犬の画像でチューニングしたモデルはHugging Faceに登録しました。
◼︎ Power Directorという動画編集ツールに課金して、上記で作成したYouTube用の音楽と画像を活用。最終的に下記の動画が完成しました!!
1. 動画編集の難しさに直面
愛と感謝の気持ちで当初は走り出したものの、動画編集の作業量がエグいことに気がつきました。
工程を書くとこのような感じです。
動画編集の工程
* 全体構成(文字)
* 台本作成(文字)
* 字幕(文字)
* サムネイル作成(画像)
* BGM(音楽)
* 効果音やエフェクト(画像/動画/音楽)
* 素材画像/素材動画(画像/動画/音楽)
etc...
こうやって箇条書きにすると、めっちゃマルチモーダルな感じです。
毎日動画アップロードしてるようなYouTuberさん、神だと思いました。
しかしながら、今の時代にはとても強い武器があります。
それは生成AI(Generative AI:ジェネレーティブAI)です!
怠惰な私はできるだけこの工程を半自動化する計画を立てました。
動画作成半自動化計画
1. YouTubeチャンネルのコンセプトは「柴犬 x AI」とする
2. 動画のアイデアや台本は思いついたものをベースにChatGPTで精緻化する
3. BGMはYouTubeテンプレートもあるけれど、雰囲気にあっている音楽をAI生成する
4. 愛犬の画像を使って、画像生成モデルをチューニングしてサムネイルや動画素材にする
5. 台本の読み上げが必要ならば音読さんなどに課金する
(声に自信がある時は自分の声を録音するが、その時は一生来ない気がする)
6. 動画編集ソフト(とりあえずPowerDirector)に課金して編集ゲーを頑張る
近い将来、動画生成もAIが全部できるような時代になるだろうけど
ひとまずこれでやろうと思いました。
この記事では特に音楽生成と画像生成についてご紹介していきたいと思います。
2. 音楽生成
2.1 音楽生成モデル紹介
まず音楽生成モデルを使ってみることにします。
最近だとMeta社のAudioCraftのMusicGenが良いらしいです。
なので参考論文も見てみました。
私の解釈でモデルの説明を下記に書いてます。(間違ってたらすいません)
ただ専門用語が多いのでなんとなくわかった程度で大丈夫です。
論文PDFのリンク: Simple and Controllable Music Generation
Chrome翻訳で閲覧したい方向け: ar5iv
・MusicGenのベースとなっているのがEncoDecのアーキテクチャ
・MusicGen にはEncoDec のエンコーダー/量子化/デコーダーに加えて、テキストとメロディーの入力プロンプトを処理するための追加の調整モジュールがある
・エンコーダー部分は、入力内のすべてのフレームのベクトル表現を大量に生成する標準的な畳み込みアーキテクチャ
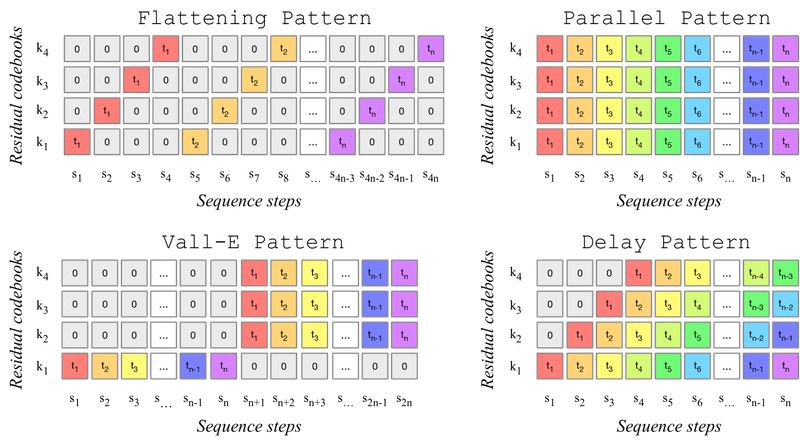
・量子化部分では、残差ベクトル量子化を採用。残差ベクトル量子化したベクトルから得た4つの出力を平坦化したり並列化したりしてインターリーブする。それを各シーケンス ステップの合計 + 位置埋め込みをしてデコーダーに渡すためのベクトルを作る
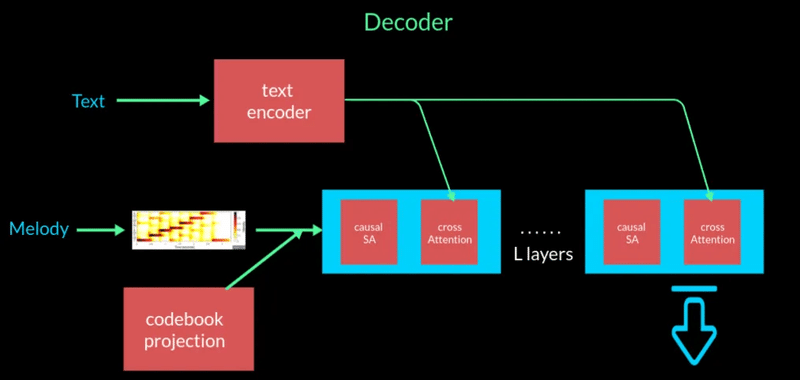
・デコーダー部分は、上記の量子化したベクトルとテキスト/口笛/ハミングなどのメロディーをベクトル化したものを処理することで、テキスト/メロディーを条件とした音楽を生成するようにしている

2.2 音楽生成してみる
なんとなく音楽生成モデルを理解したところで、実際に音楽生成してみましょう。
audiocraftのレポジトリのMusicGenのドキュメントへ行くと
「Open in Colab」というボタンがあります。
これを押すとGoogle Colaboratoryが開きます。
私は一時的にColab Proの契約をしてますが、小さめのモデルを使う分にはTesla T4とかで大丈夫です。
画面をポチポチしていくとgradioのdemo画面へのリンクが出てきます。
リンクをクリックすると下記のような画面が出ます。
テキスト入力するところで好きな音楽のテイストなどを書くと、テキストに応じた音楽が出力できます。
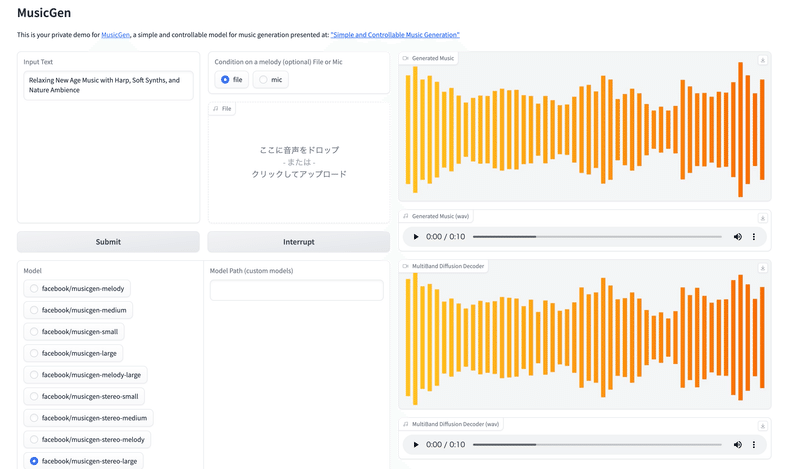
こんな感じでほぼ画面をぽちぽち押すだけで音楽生成できます。
色々と音楽生成モデルが試せそうですが、今回はパラメータがでかいモデル(facebook/musicgen-stereo-large)を使ってみます。
※T4のGPUだと時々メモリーエラーが出るかもしれないです。その時はGPUのインスタンスグレードを上げるか、モデルを小さくしてみてください。
ぜひ小さいモデルと大きいモデルで聴き比べてみてほしいです。
全然違います。
小さいモデル:
facebook/musicgen-medium(1.5B model, text to music only)
ちょっとだけ単調な感じ
大きいモデル:
facebook/musicgen-large(3.3B model, text to music only)
大きいモデルの方が音色の奥行き(?)が違います
これで好きな音楽を生成できそうなので、音楽生成は問題なさそうです!
3. 画像生成
3.1 画像生成モデル紹介
次に画像生成モデルを試そうと思います。
画像生成に関しては、らいぞうくんの画像で画像生成モデルをチューニングしたいので、音楽生成のようにパッとはできなさそうです。
巷ではStable Diffusion XLという画像生成モデルが賑わっていたので、今回はそのモデルを使ってみようと思います。
さらに私は大きなGPUを持ってないので、GPUをたくさん使わなくてもチューニングができると噂のLoRA(Low-Rank Adaptation)でチューニングをしたいと思います。
「Stable Diffusion XL」とか「LoRA」という未知の単語が出てきましたが、ざっくりご紹介します。
3.2 Stable Diffusion XLとは
Stable Diffusion XLを論文など読みながらざっくり説明すると下記の通りです。専門用語が多いのでなんとなくわかった程度で大丈夫です
論文PDFのリンク: SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Chrome翻訳で閲覧したい方向け: ar5iv
・Stable Diffusionの改良版
・全般的にモデルを重くし、U-Netが3倍、Text EncoderがCLIPを2つアンサンブル
・解像度に対する条件付(Encoding)を導入し、ランダムクロップや訓練画像の解像度の低さの問題に対処
・Refinerを追加し、局所的な粗さを改良
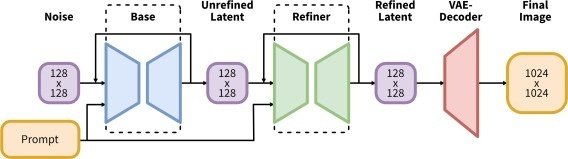
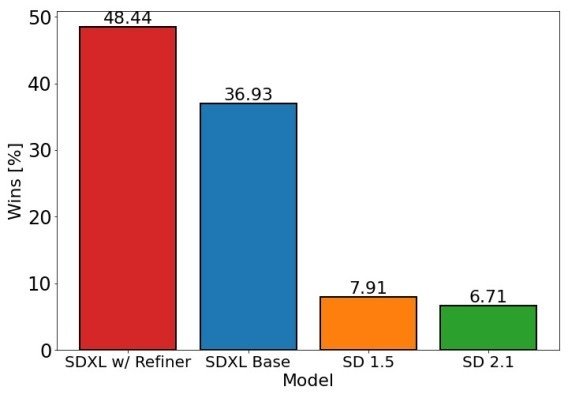
またBaseモデルのみとBaseモデル+Refinerモデルを比較すると結構クオリティが違います。
試しに下記のプロンプトを書いて、画像を比較してみます。
Concept art of Kuroshiba raizo dog running between towering skyscrapers on a New York City street corner, blue hour, neon lighting, highly detailed, artstation, deviantart, impressive scene, impressive composition, impressive lighting, detailed face, realistic, 8k
ニューヨークの街角、そびえ立つ高層ビルの間を走る黒柴らいぞうのコンセプトアート, ブルーアワー, ネオン, 高詳細, アートステーション, デビアントアート, 印象的なシーン, 印象的な構図, 印象的な照明, 詳細な顔
Baseモデルのみ
ぱっと見は綺麗だが足が変だったり全体的にぼやけてたりする画像が結構出力される。

Baseモデル+Refinerモデル
比較的ちゃんとしている画像が多くRefinerが効いている感がある

3.3 LoRAとは
LoRAをざっくり説明すると下記の引用の通りです。
専門用語が多いのでなんとなくわかった程度で大丈夫です
論文PDFのリンク: LoRA: Low-Rank Adaptation of Large Language Models
Chrome翻訳で閲覧したい方向け: ar5iv
論文解説
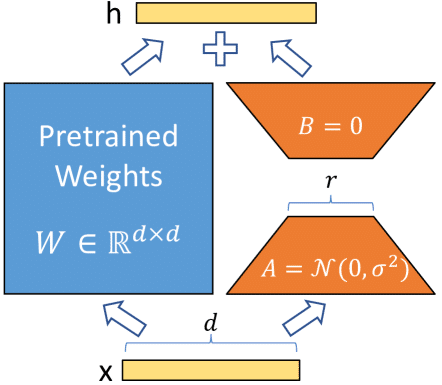

3.4 事前準備
Stable Diffusion XLとLoRAが何となくわかったところで、
Stable Diffusion XLをLoRAチューニングしていきます。
チューニングする時に下記のアカウントとトークンが必要になるので、先にアカウント登録してトークンを準備しましょう。
3.5 画像学習コード解説
実際に下記のGoogle Colabを使って、学習プロセスを回してみたいと思います。Colab内のコメントなども書いてますが、下記に要点だけ箇条書きで書いて雰囲気を知っていただこうと思います。
フォルダのマウント関係がちょっと面倒なので、データやアウトプットなどは自分のGoogle Driveをマウントして使う方式で実行します。
from google.colab import drive
drive.mount('/content/drive')データセットはHugging FaceのHubからsnapshot_downloadを使ってダウンロードできます。
ダウンロードするパスはお好きなところを指定して大丈夫です。
from huggingface_hub import snapshot_download
local_dir = "/content/drive/some/path"
snapshot_download(
"mussso/kuroshiba_raizo",
local_dir=local_dir, repo_type="dataset",
ignore_patterns=[".gitattributes", "README.md"],
)accelerateというPyTorchの CPU / GPU / TPU 対応を共通コードで書けるようにするためのパッケージを使用しますが、画像のような感じで自分の環境に応じて設定していきます。
!accelerate config
下記のようにaccelerateのCLIを使ってらいぞう画像を使用したLoraチューニングをしてみます。
--instance_prompt="Kuroshiba raizo dog"とすることで、学習する画像が黒柴らいぞうであることを明示します。また画像生成するときのプロンプトにKuroshiba raizo dogと書くことでらいぞうのような画像が出てくるようになります。
自分が試した時点ではうまく学習プロセスが起動したのですが、xformersのバージョン次第で動かない時があります。動かない時はちょっとバージョン関係を調整してみてください...(機械学習あるあるではあるけれど...)
!accelerate launch train_dreambooth_lora_sdxl.py \
--pretrained_model_name_or_path="stabilityai/stable-diffusion-xl-base-1.0" \
--pretrained_vae_model_name_or_path="madebyollin/sdxl-vae-fp16-fix" \
--instance_data_dir=local_dir \
--output_dir="/content/drive/MyDrive/img/lora-sdxl-kuroshiba-raizo" \
--mixed_precision="fp16" \
--instance_prompt="Kuroshiba raizo dog" \
--resolution=1024 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--learning_rate=1e-5 \
--report_to="wandb" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--mixed_precision="fp16" \
--enable_xformers_memory_efficient_attention \
--gradient_checkpointing \
--use_8bit_adam \
--max_train_steps=100 \
--checkpointing_steps=717 \
--seed="0" \
--push_to_hub上記の学習プロセスがうまく行くと、Hugging Faceのモデルが作られます!このモデルを画像生成時に指定することで、らいぞうくんの画像に近いものが生成されます。
3.6 画像生成コード解説
次に下記のGoogle Colabを使用して、チューニング済みのモデルから画像生成していこうと思います。Colab内のコメントなども書いてますが、下記に要点だけ箇条書きで書いて雰囲気を知っていただこうと思います。
下記のような実装をすることで、Baseモデル+Refinerモデル+LoRAチューニング済みモデルをパイプラインにロードします。
大きなGPUを使って生成しても良いですが、CPUにモデルをロードするように実装してみます。
※ 実行する時のGoogle Colabのランタイム自体はGPUにしないとエラーが出ることがあるので、T4などを使用してください。
import torch
from diffusers import DiffusionPipeline, AutoencoderKL, StableDiffusionXLImg2ImgPipeline
# Load the base model
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
vae=vae, torch_dtype=torch.float16, variant="fp16",
use_safetensors=True
)
# Load Kuroshiba raizo tuning model
pipe.load_lora_weights("mussso/lora-sdxl-kuroshiba-raizo")
pipe = pipe.to("cpu")
pipe.enable_model_cpu_offload()
# Load the refiner model
refiner = StableDiffusionXLImg2ImgPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16"
)
refiner.to("cpu")
refiner.enable_model_cpu_offload()次にプロンプトを書いて構築したパイプラインを実行します。
height=720, width=1280というサイズにしてますが、大きすぎると変な画像が生成されたりするので微調整が必要です。
生成結果はimagesという配列に保存されるので、適宜Google Driveに保存するなどしてみてください。
prompt = "3D photorealistic pencil drawing of Kuroshiba raizo dog, highly detailed, artstation, deviantart, impressive scene, impressive composition, impressive lighting"
negative_prompt = "low-resolution, blurred"
generator = torch.Generator("cpu").manual_seed(0)
images = []
for i in range(5):
image = pipe(prompt=prompt, negative_prompt=negative_prompt, output_type="latent", generator=generator, height=720, width=1280, device=torch.device('cpu')).images[0]
image = refiner(prompt=prompt, negative_prompt=negative_prompt, image=image[None, :], generator=generator, height=720, width=1280, device=torch.device('cpu')).images[0]
images.append(image)
試しに「Kuroshiba raizo dog」というプロンプトを使って、LoRAチューニングしていない場合とLoRAチューニングしている場合で画像比較してみます。
LoRAチューニングをしない場合
柴犬ぽい画像は出しますが、「Kuroshiba」が何かわかってない様子の画像がたくさん出てきます。

LoRAチューニングをした場合
黒柴らいぞうというのを認識してちゃんと黒柴らいぞうが出てきます

数枚しか使ってないですが、チューニングがちゃんと効いてそうです。
らいぞうくん、めっちゃかっこいいです。
4. プロンプト生成
画像も音楽も準備できました。
あとは生成していくだけなんですが、まだ問題があります。それは...
「画像も音楽も専門用語がわからねぇからプロンプトが書けねぇ」
という致命的な問題です。
4.1 プロンプト書くのムズイ問題
画像に関して言えば、下記のガイドブックにもたくさんのプロンプト芸が描かれていますが、やはり具体的であればあるほど精度も高くなりそうです。
モネっぽい画像が欲しい時
o 印象派のクロードモネの睡蓮のような作画の画像
x エモい感じの画像
結構プロンプトを書くのは難しいのですが、それさえもAIは解決してくれます。
というのも、私の方で画像や音楽生成のプロンプトを書いてくれるGPTsを作ってみました!音楽生成や画像生成のプロンプトを作りたいな、という時にぜひご活用してみてください。変な出力が出たらすいません…
Music Prompt Generator
MusicGenなどで音楽生成するためのプロンプト(英語/日本語)を生成するGPTs
Image Prompt Generator
Stable Diffusionなどで画像生成するためのプロンプト(英語/日本語)を生成するGPTs
※ DALL-Eで画像生成する時にも一応使えますが、クロードモネのような実名を出すとコンテンツポリシーに引っかかってエラーが出るぽいので、そこはお気をつけください。
5. 動画編集
諸々の問題を解決して、素材を作りまくりました。
あとは動画編集ソフトで編集するだけです。
諸々の編集過程は省きますが、PowerDirectorという動画編集ツールに課金して編集してみました。
Adobe Premiere Proなどの動画編集ソフトもあると思いますが、使い勝手の良いツールを選ぶと良いと思います。
そして、最終的に完成した動画はこちらです!!
終わりに
動画編集には音楽や画像、台本作成、字幕、効果音など初心者が詰まるポイントがたくさんあります。
私も独学なので全く洗練された動画を作れてません。
(ちゃんと自覚がある)
生成AIの力を借りることで動画編集の障壁を乗り越えて、自分を表現したい人たちが諦めずにクリエイティビティを発揮できる時代になると良いな、という思いで記事を作ってみました。
もしお時間があればYouTubeチャンネル高評価、登録、note記事のスキをお願いします!
あとnoteでは機械学習エンジニア含めて、採用活動を強化しています。
ぜひ興味ある方がいればカジュアル面談などを申し込んでいただければと思います。
機械学習エンジニアのカジュアル面談に私が参加することもあります。
noteエンジニアアドベントカレンダーはこちら
さらにnoteの技術記事が読みたい方はこちら
さらにさらに、note AI Creativeという子会社も爆誕してます。
今後のnoteにご期待くださいませ!!
長い記事ですが、読んでいただきありがとうございました。
この記事が気に入ったらサポートをしてみませんか?