
Trick or Treat

今日はハロウィンです。数字にいたずらされますか?それとも数字にいたずらをしますか?
はじめに
みなさんは世論調査やアンケート調査をされたことはありますか?おそらく、今までされたことがないという人は非常に少ないはずです。その集計された結果としてのデータを見たことや聞いたことはあると思います。そのデータを見るときに、おそらく平均値に注目されたり、面白い結論に注目されたりすると思います。集計されたデータから見るとそれらの結論は導き出せますが、まとめられたデータについては集計者の意図などが入り、少し違った解釈になることがあります。外国語の本が日本語に翻訳されるのと一緒で、作者の意図だけでなく、訳者の解釈が入り、原文と少しずれるということが起きます。これは統計でも同じことが起きます。発表された内容も重要ですが、生データがあれば、それを実際に見て自分で統計処理をするのも一つの方法です。今回は僕の持っているデータを使って統計について書いていこうと思います。
統計って何?
統計とは数値化した調査のことです。テストの平均点や平均年収、平均結婚年齢などどれも統計になります。その数字に様々な処理を加えるのが統計学です。統計学は理系の分野でしか使われていないと思われるかもしれませんが、心理学や政治学とった文系の分野でも使われています。実際、僕も大学の時に使っていました。統計学は思っている以上に幅広い分野で使われています。以前にも統計学を使った内容について書いているので、そちらも読んでいただけると嬉しいです。
統計学は知っていて損をすることはありませんし、飛躍した論理を見抜くことができます。「統計調査は集計する人の都合のいいように結果を作ることができ、我々は騙されている」と言う人がいます。はい、確かにその通りです。数字の処理の仕方で結果をいくらでも変えることはできます。僕もそれをしたことがあります。だから、これを機に統計の勉強をしてみませんか。統計のからくりが分かれば、統計データというものがどういうものかがわかります。
並べられた数字
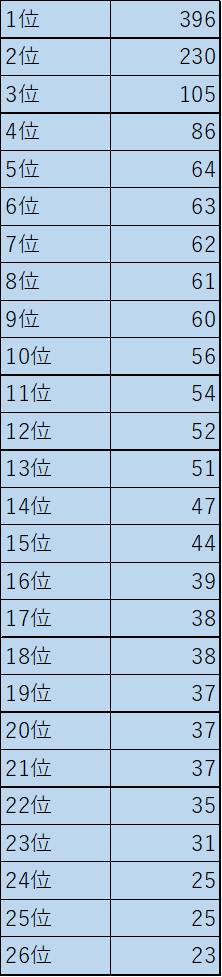
この表はある日の僕のnoteのPV数です。このデータは少し前のデータなので、今は少し変わっています。表の下にあるグラフを見ると左に偏っているのがわかると思います。これの平均値はいくつだと思いますか?
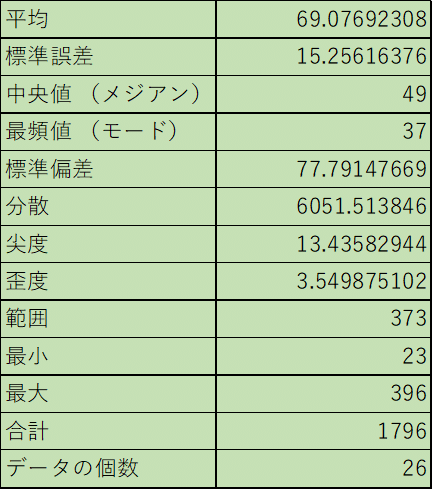
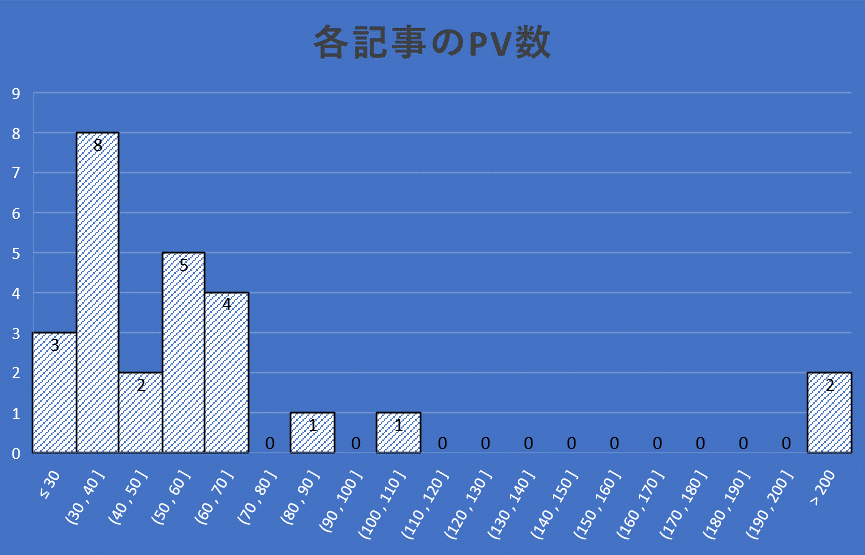
統計情報にも書いているように平均値は69.1です。しかし、平均値を上回っているのは上位4記事だけで、それ以外は平均値を下回っています。これを見られた方は本当に平均値なのかと思われるかもしれませんが、本当に平均値です。では、なぜ、平均値がこんな数字になったかを説明すると、それは上位2記事のPV数がずば抜けて高いからです。つまり、上位2記事が平均を上げているということになります。平均値は一つの目安であって、平均値だけを見ても統計データの全貌を知ることはできません。100と0の平均は50ですが、49と51の平均も50です。このように平均値だけを見ても上と下の値は分かりませんし、ばらつきもわかりません。平均値だけを見て判断することはあまりおすすめできません。
平均値だけを見ても、あまりよくないと言われたら、どこを見ればいいのかと思われるはずです。それが中央値です。中央値は全データの真ん中の値です。今回の場合だと全データ数が26でその半分が13と14の間になるので、先ほど平均値の問題点を書きましたが、13番目と14番目の平均値になります。データの数が27といった奇数であれば、ちょうど真ん中の14番目の値になります。今回の中央値をみると、49です。平均値と20以上の差があります。平均値と中央値の差が大きいとデータに偏りがうかがえます。平均値は全データの合計の中間の値で、中央値は全データの真ん中の値と思ってください。中央値は上限のある数値でも威力を発揮しますが、上限のないデータ集計でその力を存分に発揮します。上限のある数値はテストの点数のように100点が上限でそれ以上がない数値のことです。逆に上限のない数値とは平均年収や今回のようなPV数です。これらのデータの集計をするときには平均値と中央値を合わせて出してみてください。平均値との乖離を見るだけで、データ分布の予想が付きます。
今回のように中央値の方が平均値より低い場合は、平均以下にデータが集中していることがうかがえます。逆も同様です。そのことを数値化しているのが歪度と呼ばれる数値です。平均より右にデータが偏っている場合はマイナスになり、プラスになっている場合は左に偏ります。今回はプラスになっているので、平均より左に偏っていることが数値でも示されています。尖度と呼ばれる値はグラフの急峻度を表しており、どこかの値が突出していると高くなります。グラフが平坦になれば、数字は小さくなります。このように単に並べられた数字ですが、グラフにしたり、統計処理をしたりすると様々なことがわかります。これは数字のトリックです。
因果関係の推定

統計でも因果関係を推定することができます。それは回帰分析という統計手法で、回帰分析はY(従属変数)←X(独立変数)の因果関係を推定する手法です。回帰分析は一次関数のY=aX+bという形になります。Yが結果(従属変数)でXが原因(説明変数)です。XとYだけを使う手法を単回帰分析と言い、Y←X1+X2のようなYに対してXが複数存在する重回帰分析といいます。回帰分析では直線で示すことしかできないでの曲線上になっている場合は示すことができないのが問題点です。回帰分析と並行して、散布図を作成して推定される線形を導くこともできます。回帰分析はXの数を増やすことができ、複数の要素との関係を知ることもできます。相関関係はY↔Xになり、どちらがどちらに影響を与えているかをそこから読むことはできません。因果関係はその矢印の向きがはっきりとしています。
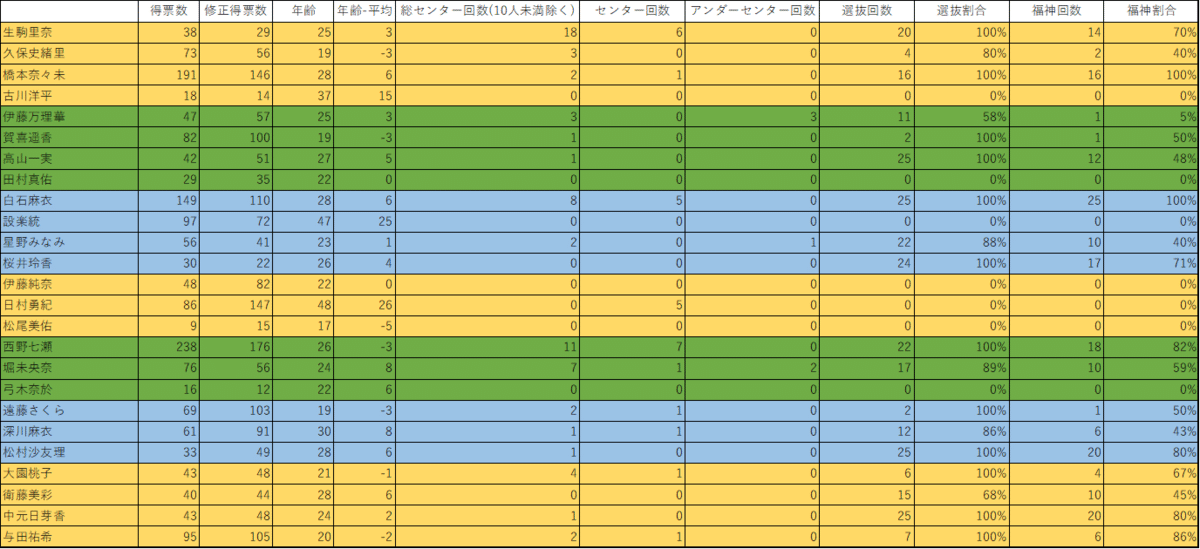
アンケート調査結果
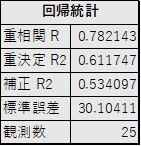
この表は、以前、乃木坂46で人気のあるメンバーについて調べたとき作った表です。表に書かれているデータだけでは情報量が多く、票を見ただけは何が投票要因であるかについてよくわかりません。Yを得票数とし、Xを総センター回数、(表題曲)センター回数、アンダーセンター回数、選抜割合としました。それらのデータを回帰分析したのが灰色の表と青色の表になります。灰色の表は各データと推定された直線のばらつきを示すものになっています。R(相関係数)は-1≦R≦1の間で変化し、1に近ければ近いほど、右肩上がりの直線になり、-1に近ければ近いほど、右肩下がりのグラフになり、0に近ければ直線を引くことができない状態になります。その下のR2と書かれている数字は、Rを二乗したもので、各データと推定直線の差を表しています。この数字が大きければ大きいほど、データとの差が小さくなります。逆にこの数字が小さくなればなるほど、推定直線とデータとの差が大きくなります。この灰色の表からはYと複数のXとの関係は強い相関関係があり、各データとの差が小さいことがわかります。しかし、この時点では複数のXとYに因果関係があるかどうかは分かりません。その因果関係を示すのが下の青色の表になります。

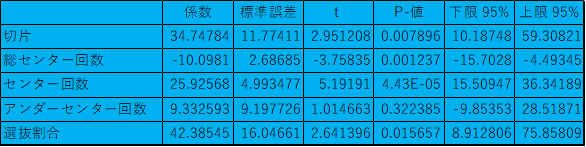
青色の表ではYとXの因果関係を知ることができます。この表では係数とP-値を見れば、因果関係の有無がわかります。係数はY=aX+bのaにあたる部分で、中学で習う一次関数の係数と同じです。bの切片についても同じです。係数が分かれば、その変数がプラスに作用しているのかマイナスに作用しているのかが分かります。総センター回数は得票数にマイナスの影響を与え、それ以外の変数は得票数にプラスの影響を与えていることがわかります。
次にP-値です。P-値はその変数がYに影響を与えている変数であるかどうかを示す値です。基本的にP-値が低ければ、低いほど影響を与えている可能性が高いと言えますがが、その線引きが人によって異なるとまずいので、有意水準というものを設けます。有意水準とは提唱しようとしている説の反対の仮説(帰無仮説)を棄却する水準のことです。一般的には有意水準は5%(0.05)で、その水準を下回れば、統計的有意と言うことができます。20回に1回は提唱しようとしている説が成り立たないことになりますが、20回に1回であれば、頻繁に起こりうる確率でないので5%を有意水準に設けることが多いです。場合によっては、1%水準にする場合もあります。今回の場合の帰無仮説はYと複数のXは無関係であるになり、P-値が高いと帰無仮説の方が強くなってしまいます。今回のケースであれば、Yに影響を与えているXはアンダーセンター回数以外の3変数になります。アンダーセンター回数は0.05を超えているので、因果関係を示す変数ではありません。
相関係数がある変数を回帰分析すると因果関係がなかったということもあります。しかし、その逆はありません。因果関係があるものはしっかりとした相関関係を示します。因果関係をしっかり示すのであれば、相関関係を調べるだけなく、回帰分析を行うとよりよい統計分析になります。最近の社会科学の分野では、回帰分析から実験的手法に変化しています。実験については以前取り上げたこちらに書いています。
最後に

僕が大学生の時に授業で、厚生労働省が家の畳数が広い家庭ほど子どもを産む人数が多いことがわかり、畳の数を増やして子どもをたくさん作りましょうと結論付けた報告書を出していると教わりました。その先生はこのデータは確かに正しいが結論に問題があると言っていました。それはなぜでしょう?実はこの両者に相関関係があるのは確かですが、因果関係がなかったからです。この因果関係は各家庭の所得でした。所得が高ければ、家を広くすることができ、子どもを育てる経済力があるからです。実は当たり前の普通の要因だったのです。このように一見面白そうな調査結果には大きな落とし穴があります。これは政府が国民の所得を上げたくないからだという陰謀論的結論ではなく、この調査の集計をした人が統計学についてあまり詳しくなかったからではないかと思います。世の中に出回っている統計データは集計した人に騙す意図があったというよりも、よくわからずに統計処理をやっていることも考えられます。統計の見方が分かれば、世の中の見方が変わる!とまでは言いませんが、統計学について知っていると、「その結論、本当に合っているの?」といったことや人間の行動を読むことができます。実際にマーケティングの分野では統計学は使われています。身の回りにあるデータを使って、一度統計分析をしてみてください。今考えている新商品の開発にも役立てるかもしれません。もしかすると面白い発見があるかもしれません。
この記事が気に入ったらサポートをしてみませんか?