
「Alexaエージェント、通信を開いて!」(OpenCV×VUI)

はじめに
この記事は OpenCV Advent Calendar 2018 の 18日目の記事です。
視覚情報を扱うOpenCVと聴覚情報を扱うスマートスピーカーを合わせて何かつくろう
私はここ数年仕事ではOpenCVなどで画像を扱ったりしていますが、プライベートではVUIを満喫しています。
昨年は 万年アドベントカレンダーを実装した(OpenCV+Deep Neural Network+RoBoHoN) という「OpenCV×ロボット」をしたのですが、今年は「OpenCV×スマートスピーカー」をすることにしました。
視覚情報を聴覚へ(情報量と「要約」)
定量的な情報量としては、
視覚 >>>>(越えられない壁)> 聴覚
なので視覚情報を音声で伝えると、伝達される情報量は圧倒的に減りますが
情報の要約
が必要なケースでは、俄然、メリットがでてきます。

メリットが出るケースの一例
(「この領域に”あの男”がいるのか/いないのか」の2値の情報が重要なケース)
”必要な情報について、情報の送り手と受け手が『前提』を共有している”ケースでメリットが出そうです。
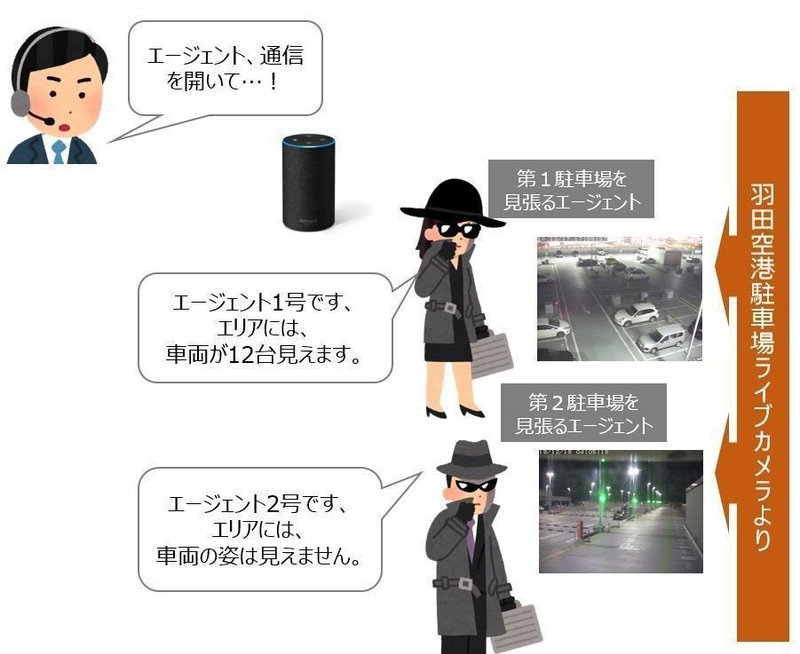
前提『羽田空港駐車場の混雑具合が知りたい』
先日、都営バスの中でこんなステッカーをみかけました。(「羽田空港の駐車場は繁忙期に大変混雑します、数時間待ちもあるから気をつけて」の趣旨)

なるほど!と思いました。
(アドベントカレンダー投稿予定日当日が終わりそうな時間帯にこれを書いており(実装は終わってます…!)気が急くあまり、論旨が飛んで恐縮ですが)そこで、今回つくるものの前提を「羽田空港駐車場の混雑具合が知りたい」と置いて、このようなイメージのものを実装しました。
(スパイ映画の要素を混ぜ込んでいるのは、個人的趣味の「声に出して読みたい日本語」のひとつを実装したものです)
実装は、こんなかんじです(OpenCVのロゴをやっと出せました!)
OpenCV dnnライブラリを利用して、TensorFlow 等の DeepLearning プラットフォームなし、OpenCV のみで YOLOv3 での object detection をしています。
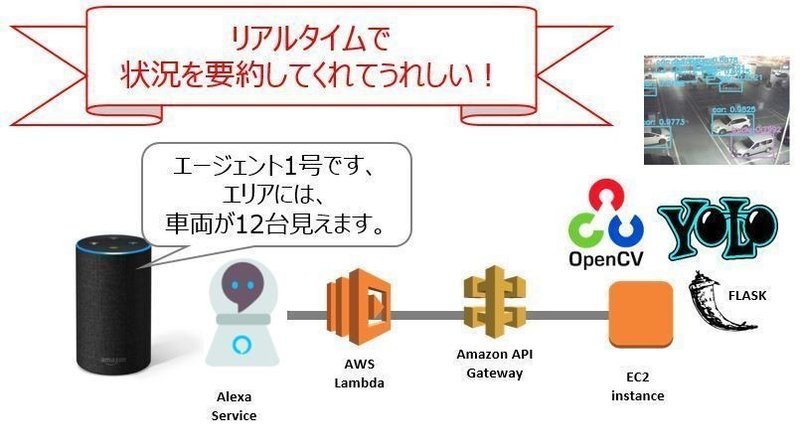
ライブカメラの映像はこちらのものを参照しており、二次利用は不可かとおもいます…。そのため、AWS公式審査に出してのAlexaスキルリリースには進めません。
プロトタイプとしてざっと実装し、動作させた動画がこちらです。
動画における要約情報の元画像はこちら(ゼロ時前で車がいない(不覚))

早朝や日中の状況は下記。

参考情報
実装の手順概要は下記です。
1.認識用環境つくる
・ubuntu16.04, t2xlarge(vcpu4, mem16GB)
2.モデル選ぶ
・同一元画像に対して、左がYOLOv3、右がMobileNetSSDで認識処理実行した時の結果(今回のライブカメラ画像において、右は精度的に利用が難しい様子が判る)

・OpenCVv4になって、dnnライブリの公式ドキュメントやリソースがより拡充してうれしいです!
https://github.com/opencv/opencv/tree/master/samples/dnn
https://github.com/opencv/opencv_extra/blob/master/testdata/dnn/download_models.py
3.FlaskでAPI化する
・Lambdaに載らず(50MB制限)、プロトタイプの構成部品が増えて残念
・認識結果返却APIにするためにFlaskをつかう
4.Alexa応答用のLambda関数をつくる
・嬉々として、男女エージェントにしたり、(エージェントが物陰に潜んでいる脳内設定による)ささやき声にしたり、SoundEffectを選んだりする
5.Alexa対話モデルの作成
・スキル起動コマンド定型句「~を開いて」由来で、プロトタイプのタイトルと呼び出し名を”エージェント通信”にする(エージェント、通信を開いて!)
まとめ
視覚的状況を聴覚メッセージに要約するソリューションは、たとえば
・「店頭状況の要約による適切な品出し+機会ロス防止」や
・「駅前の放置自転車の状況を要約しアラート」など、
”あったらいいな”のユースケースが色々考えられるかな、と思いました!
(今回の実装に関する直接的な感想としては、007のエンジニア”Q”のような気分を味わえたので大変満足です)