SaaSのOCRサービスを使った切符の読み取り、はじめの一歩

こんにちは、猫はすべてを解決するです。ナビタイムジャパンでAIによる業務支援やAI開発を担当しています。
新幹線のきっぷを自動で読み取ってその列車を利用する経路検索ができたら嬉しいというサービスアイディアがあったため、SaaSのOCRサービスで切符という特殊なフォーマットの文字がどれだけ読み取れるか試してみました。
その過程で見つけたコツなども紹介できればと思います。

Azure Form Recognizer とは
今回試したのは、Microsoft Azure の From Recognizer です。
Form Recognizer – 自動データ処理システム | Microsoft Azure
社内でもPDFの読み取り運用などで導入実績があるサービスで、今回は切符という特殊なフォーマットをどの程度読み取れるか試してみました。
PDFの読み取りにつきましては、以前の記事もご覧ください。
Readモードで文字の認識精度を確認
まずは、Document analysis の Read モードでどれくらい文字を認識するか試しました。

掠れた印字、特徴的なフォント、漢字/ひらがな/カタカナ/英数字/記号が混合していますが、認識できていることがわかります。
反面、「新鳥栖」の「新」と「鳥栖」が別々のパラグラフとして認識されてしまったり、「→」と「鹿児島中央」が同じパラグラフと認識されています。
カスタムモデルを試す
次に、各要素をラベリングして扱いやすくするために、カスタムモデルを試しました。
カスタム ドキュメント モデル - Form Recognizer - Azure Applied AI Services | Microsoft Learn
カスタムモデルは現在、下記2つの種類を選んで作成することができます。
テンプレートモデル
ニューラルモデル
カスタム ニューラル モデルは英語でのみトレーニングされており、他の言語のドキュメントではモデルのパフォーマンスが低下します。
とあったため、ニューラルモデルは日本語ではラベリングの精度が出るか分かりませんでした。
しかし両方試した結果、最終的にはニューラルモデルの方が精度が良かったため、本稿ではニューラルモデルの結果についてお話しします。
①データセット8枚
ニューラルモデルの学習データは、最少5枚から学習できます。
手元に利用できる写真が9枚あったため、簡易的ではありますが8枚を学習データにし、残りの1枚で確認を行ってみます。

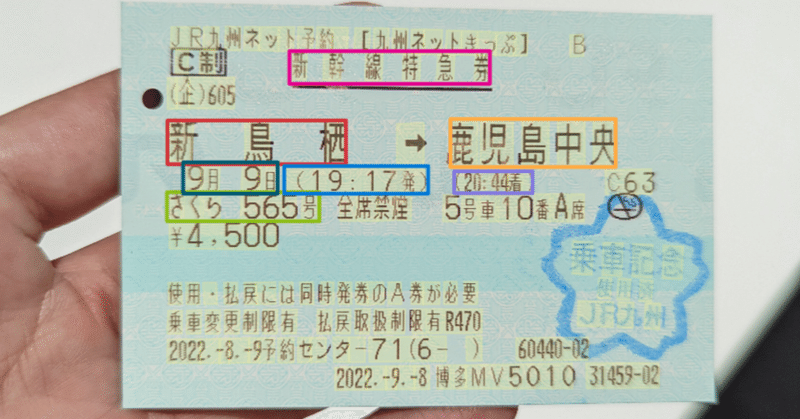
切符名が出発地と認識されています。
②データセット8枚(改良版)
次に、切符名にもラベルをつけてから再度学習させて、試してみました。
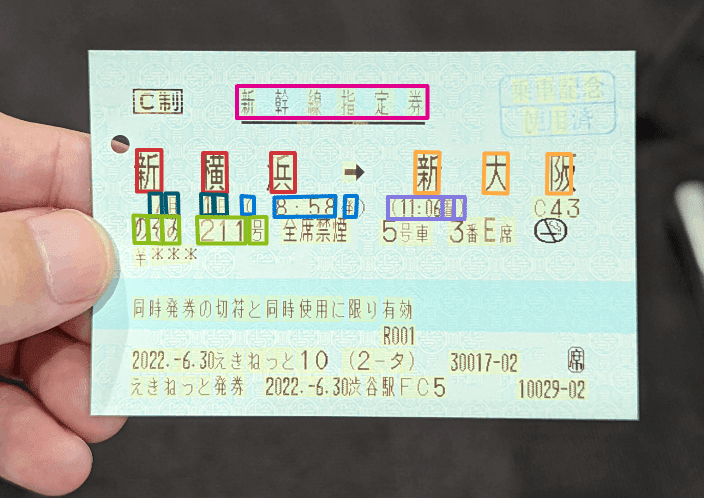
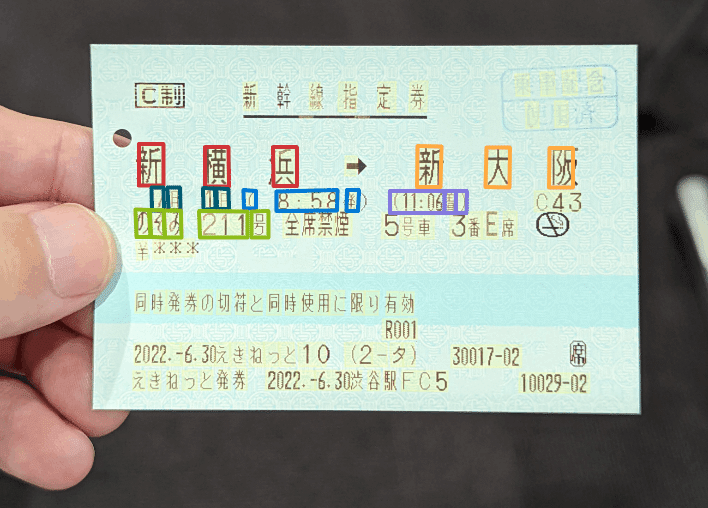
切符名が認識され、出発地を正しく認識できました。
ですが、今度は目的地が期待と違う文字を拾っています。
③データセット24枚
流石にデータセットが少なすぎたため、後日24枚まで学習データを増やした結果がこちらになります。
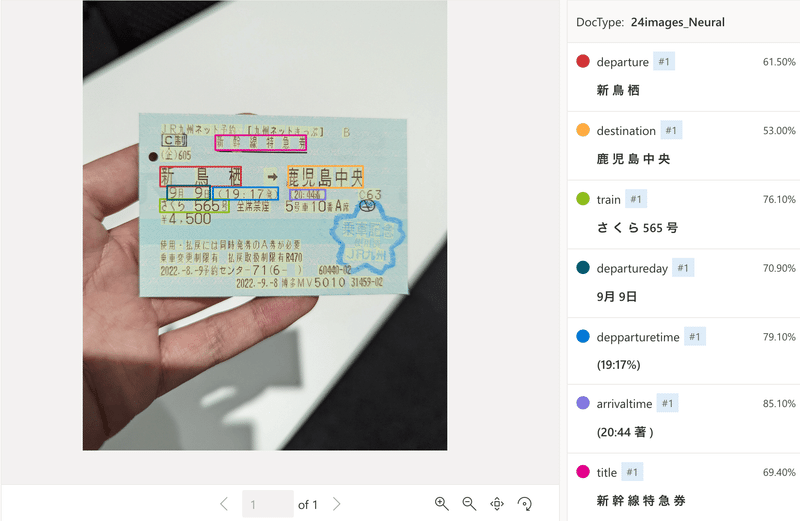
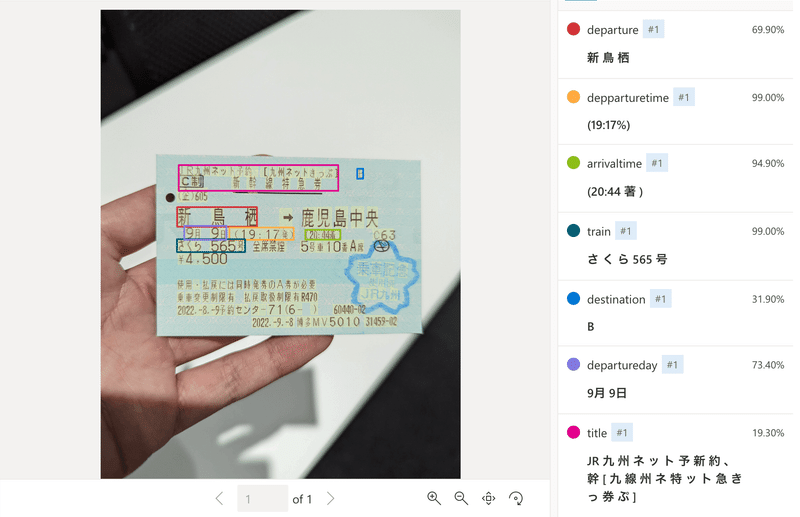
24枚まで学習データを増やしたところ、期待通りの要素が拾えるようになりました。
出発時刻や到着時刻の文字が一部間違っている問題が残りますが、学習データを増やせばラベリングの精度は顕著に上がることがわかりました。
まとめ
掠れた印字、特徴的なフォント、漢字/ひらがな/カタカナ/英数字/記号が混合など切符独特のフォーマットを、ある程度の精度で読み取ることができました。
Azure Form Recognizer のニューラルモデルは英語でのみトレーニングされていますが、日本語でもラベリングは可能でした。
少ない学習データでもラベリングすることはできましたが、データセットが1桁など少なすぎると、今回のケースではラベリング精度はイマイチでした。
データ量を増やせばラベリング精度を上げることができます。
SaaSを利用すると細かいカスタマイズは難しいですが、案件によっては需要を満たすことができます。精度確認のハードルも低いため、まずは試してみる、を簡単にできる点が大きなメリットです。
今回は採用を見送りましたが、今後も選択肢の1つとして検討を進めていきます。