PostgreSQLのDBをパーティション化して、更新処理の改善を行った話

こんにちは、はまです。
ナビタイムジャパンでインフラ環境の管理・構築・運用を担当しています。
DBを運用する上で、データの断片化について考えたことがありますか?
大量のデータを更新する必要があるケースや、データの更新頻度が多いケースでは断片化の考慮は必須です。
今回はPostgreSQLのDBをパーティション化して、更新処理の改善を行った話をご紹介します。
既存の問題点
既存の更新の仕組みには以下のような問題点がありました。
該当のテーブルは世代管理されており、1世代のデータが数百万件にもなる
INSERT/DELETE での更新のため、徐々にデータが断片化してしまう
解消のために VACUUM をする必要があるが、リアルタイムで参照されているため実施も難しい
そのため定期的にメンテナンス時間を確保して DROP/CREATE で再作成を実施していました
DROP/CREATE での再作成は手動 VACUUM (full) でもOKですが、テーブル再作成のほうが早く、かつ綺麗になるためそちらを採用していました
断片化した状態を放置しておくと、更新時(特に削除時)に autovaccum が実行されテーブルロックが発生、サービスからの参照に影響が出るケースもありました
また、メンテナンスの実施に関しても、データ量が多いため一回実施するのに数時間かかることもあり、かなりの負担になっていました。
パーティショニング(パーティション化)とは
パーティショニングとは、論理的には一つの大きなテーブルであるものを、物理的により小さな部品に分割することを指します。
特定のパーティションのみにアクセスするような使い方をしている場合、一つの大きなテーブルにアクセスする場合と比べてパフォーマンスが上がる可能性があります。
また、
一括挿入や削除について、その使い方のパターンをパーティショニングの設計に組み込んでいれば、それをパーティションの追加や削除で実現することが可能です。 個々のパーティションを DROP TABLE で削除する、あるいは ALTER TABLE DETACH PARTITION を実行することにより、一括の操作をするよりも遥かに高速です。 これらのコマンドはまた、一括の DELETE で引き起こされる VACUUM のオーバーヘッドを完全に回避できます。
というようなメリット(こちらがかなり大きい)もあるため、既存の更新処理の改善が見込めると考え、試してみることにしました。
パーティションのイメージ


データ削除時の動き
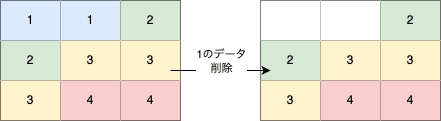
削除(DELETE)を実施すると歯抜けの状態になる → vaccumやテーブルの再作成が必要
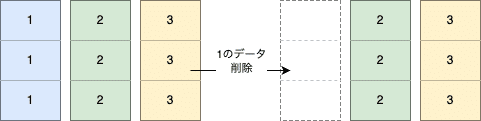
削除はDROPで行う事ができ、断片化の心配も無くなる
具体的な設定
パーティション化の形式はLISTを利用しました
世代は特定の数字のためLIST形式が都合が良い
親テーブルの設定は CREATE TABLE の末尾に PARTITION BY LIST(パーティションの元となるカラム名)を記載することで設定できます
例) CREATE TABLE parent_table ( ... )PARTITION BY LIST( column_name );
データ投入の際は CREATE TABLE child_table PARTITION OF parent_table FOR VALUES IN (パーティション(のLIST、複数指定可)) で世代毎にパーティション(子テーブル)を作成し、その後データをINSERTします
子テーブル名の後ろに世代名など判別し易い名前を入れておくと見た目でわかりやすくなります
データ削除の際は DROP TABLE child_table で不要となった世代のパーティションテーブルを削除します
ALTER TABLE DETACH PARTITION でパーティションをデタッチしてから子テーブルを削除する形でもOKです
パーティション化のメリット
実際にパーティション化することによって、以下のようなメリットが得られました。
メンテナンスコストの減少
世代ごとにパーティション管理することにより、更新方法がパーティションの CREATE/DROP に変更され、データの断片化が発生しなくなった
今まで実施していた定期メンテナンスが不要に
更新時間の減少
データの削除に関しては、DELETE で数百万のレコードを削除すると数分の待ち時間が発生していましたが、 DROP に変更になるため一瞬に
データの追加に関しても、時間の減少が見られました
実際の更新時間推移
検証環境 変更前:60分 → 変更後:10分
本番環境 変更前:60分 → 変更後:5分
検証/本番でDBサーバーのスペックに差分があるため差が出ていますが、どちらも大幅に減少していることがわかります
パーティション化のデメリットとその改善
参照負荷の増加
導入前に既存のデータを利用してパーティション化したもの/しないもので比較の負荷試験をしたところ、パーティション化した方のDBで数パーセントのCPU使用率上昇が見られました
原因を調査してみると、SQLの書き方により実行計画に差分があることがわかりました
既存SQL
select hoge from parent_table where generation = (select max(generation) from generation_management_table);世代管理テーブル(generation_management_table)の最新の世代(max(generation))をサブクエリで取得し、その結果を元に親テーブル(parent_table)を参照する形になっていました。
既存SQLの実行計画
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------
Append (cost=0.25..40982.65 rows=1355680 width=11)
InitPlan 2 (returns $1)
-> Result (cost=0.24..0.25 rows=1 width=4)
InitPlan 1 (returns $0)
-> Limit (cost=0.15..0.24 rows=1 width=4)
-> Index Only Scan Backward using generation_management_pk on generation_management_table (cost=0.15..60.51 rows=706 width=4)
Index Cond: (generation IS NOT NULL)
-> Seq Scan on child_table_1 (cost=0.00..9674.09 rows=384807 width=11)
Filter: (generation = $1)
-> Seq Scan on child_table_2 (cost=0.00..12263.75 rows=485420 width=11)
Filter: (generation = $1)
-> Seq Scan on child_table_3 (cost=0.00..12266.16 rows=485453 width=11)
Filter: (generation = $1)(範囲対象外も含む)全てのパーティションを見に行く挙動になってしまっていたため、負荷が上昇したと考えられます。
変更後のSQL
## 先にアプリケーション側で最新世代を取得しておく
select max(generation) from generation_management_table;
## その後、取得しておいた世代(例:3)を指定して検索する
select hoge from parent_table where generation = 3;サブクエリを利用しない(先に最新の世代を取得しアプリケーション側でキャッシュしておき、その世代を指定して検索する)形に変更
変更後のSQL実行計画
QUERY PLAN
-------------------------------------------------------------------------
Seq Scan on child_table_3 (cost=0.00..12266.16 rows=485453 width=11)
Filter: (generation = 3)
(2 rows)該当のデータが入っているパーティション(child_table_3)のみを見に行く形のため、処理が軽くなり、DBの負荷も既存同等になりました
まとめ
今回はPostgreSQLのパーティション機能を利用して、更新処理を改善した話をしました。
パーティション化は要件次第でかなりのメリットが得られる可能性がありますが、想定外の動作になる可能性もあるため、
事前に負荷試験を行いDB負荷や利用側のアプリケーションのレスポンスタイムが遅くなってないかの確認をしておくことをおすすめします。
最後までお読みいただきありがとうございました!