
WSL2でkotomamba-2.8B-v1.0を試してみる

「kotomamba モデルは、革新的な状態空間モデル mamba アーキテクチャを活用した、自然言語処理 (NLP) における最先端のアプローチを表している」らしいkotomamba-2.8Bを試してみます。
2024/2/21 01:50頃
推論のスピードについて、追記しています。
kotomamba-2.8Bは、現在モデルが2つ提供されています。
kotoba-tech/kotomamba-2.8B-v1.0
スクラッチから日本語と英語のコーパスにて学習。kotoba-tech/kotomamba-2.8B-CL-v1.0
state-spaces/mamba-2.8b-slimpjから日本語と英語で継続事前学習。
今回は、kotoba-tech/kotomamba-2.8B-v1.0を使用します。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
python3 -m venv kotomamba
cd $_
source bin/activateリポジトリをクローンします。
git clone https://github.com/kotoba-tech/kotomamba.git kotomamba
cd $_パッケージのインストールです。
# pip install -r requirements.txt
#
pip install wheel
pip install "causal-conv1d>=1.1.0"
pip install mamba-ssm
モデルのダウンロード
from huggingface_hub import snapshot_download
REPO_ID = "kotoba-tech/kotomamba-2.8B-v1.0"
snapshot_download(repo_id=REPO_ID, revision="main")2. 流すコード
推論のサンプルコード inference_sample.sh を参考に、以下のようなコードとしました。shell から流し込みます。
HF_KOTOMAMBA_CACHE=~/.cache/huggingface/hub/models--kotoba-tech--kotomamba-2.8B-v1.0/snapshots/399c741bb23584bf4eb93805991c1cdb0dc0368a
python -i -m benchmarks.benchmark_generation_mamba_simple \
--model-name "kotoba-tech/kotomamba-2.8B" \
--tokenizer-path "kotoba-tech/kotomamba-2.8B" \
--tokenizer-model "${HF_KOTOMAMBA_CACHE}/tokenizer.model" \
--tokenizer-type SentencePieceTokenizer \
--use-sentencepiece \
--prompt "ドラえもんとはなにか" \
--topp 0.9 --temperature 0.7 --repetition-penalty 1.23. ためしてみる
流し込むと、モデルのロードが始まり・・・、
Loading model kotoba-tech/kotomamba-2.8B
config.json: 100%|████████████████████████████████████████████████████████████████████| 1.91k/1.91k [00:00<00:00, 6.04MB/s]
pytorch_model.bin: 100%|██████████████████████████████████████████████████████████████| 5.79G/5.79G [06:42<00:00, 14.4MB/s]
Number of parameters: 2887621120
DEBUG: eod=7RTX 4090 Laptop GPU(16GB)
['<s> ドラえもんとはなにか?〜』\n『映画クレヨンしんちゃんシリーズ20周年記念作品。「のび太」が主人公で、原作にはないオリジナルストーリーを展開するという設定になっている(ただし、「しずかちゃん」「ひろしくん」、「みさえさん」(声:麻生久美子)など 主要キャラクターも登場している)」[1](『ウィキペディア日本語版』)'] Prompt length: 7, generation length: 76
kotoba-tech/kotomamba-2.8B prompt processing + decoding time: 980ms
秒あたり77.5トークン。これは速い。
RTX 4090 (24GB)
Prompt length: 7, generation length: 76
kotoba-tech/kotomamba-2.8B prompt processing + decoding time: 697ms
秒あたり 109.0トークン。これもまた速い。
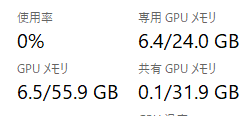
リソース
VRAMは6.4GBでした。
4. まとめ
推論の速度は、弊環境では
・RTX 4090 Laptop GPU (16GB) : 77.5 tokens/sec
・RTX 4090 (24GB) : 109.0 tokens/sec
VRAMの使用量は、6.4GB(モデルロード直後)でした。
推論速度について(追記)
推論のサンプルコード inference_sample.sh の先にあるpythonコード benchmarks/benchmark_generation_mamba_simple.py を確認したところ、。
「うーん、これだとキャッシュに載せたあとの推論結果の3回平均になってないかしら?」
と疑問に思ってしまった。思ってしまったら調べなければならないので、いつもの使用しているコードをこのサンプルコードに組み込んで確認してみた。
修正したコードは以下。いつものように q(…) で何度も確認できるようにしています。
・benchmarks/benchmark_generation_mamba_simple.py
# Copyright (c) 2023, Tri Dao, Albert Gu.
import argparse
import time
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, LlamaTokenizer, TextStreamer
from typing import List, Dict
from mamba_ssm.models.mixer_seq_simple import MambaLMHeadModel
from megatron_lm.megatron.tokenizer import build_tokenizer
parser = argparse.ArgumentParser(description="Generation benchmarking")
parser.add_argument("--model-name", type=str, default="state-spaces/mamba-130m")
parser.add_argument("--tokenizer-type", type=str, default="tokenizer type")
parser.add_argument("--tokenizer-path", type=str, default="EleutherAI/gpt-neox-20b")
parser.add_argument("--tokenizer-model", type=str, default="EleutherAI/gpt-neox-20b")
parser.add_argument("--use-sentencepiece", action="store_true")
parser.add_argument("--prompt", type=str, default=None)
parser.add_argument("--promptlen", type=int, default=100)
parser.add_argument("--genlen", type=int, default=2048)
parser.add_argument("--temperature", type=float, default=1.0)
parser.add_argument("--topk", type=int, default=1)
parser.add_argument("--topp", type=float, default=1.0)
parser.add_argument("--repetition-penalty", type=float, default=1.0)
parser.add_argument("--batch", type=int, default=1)
parser.add_argument(
'--vocab-extra-ids', type=int, default=0,
help='Number of additional vocabulary tokens. They are used for span masking in the T5 model'
)
parser.add_argument(
'--make-vocab-size-divisible-by', type=int, default=128,
help='Pad the vocab size to be divisible by this value.This is added for computational efficiency reasons.'
)
args = parser.parse_args()
repeats = 1
device = "cuda"
dtype = torch.float16
print(f"Loading model {args.model_name}")
is_mamba = "mamba" in args.model_name
if is_mamba:
if args.use_sentencepiece:
megatron_tokenizer = build_tokenizer(args=args)
tokenizer = LlamaTokenizer.from_pretrained(
pretrained_model_name_or_path=args.tokenizer_path,
legacy=False,
)
else:
tokenizer = AutoTokenizer.from_pretrained(
pretrained_model_name_or_path=args.tokenizer_path,
)
model = MambaLMHeadModel.from_pretrained(
pretrained_model_name=args.model_name,
device=device,
dtype=dtype
)
else:
tokenizer = AutoTokenizer.from_pretrained(
pretrained_model_name_or_path=args.tokenizer_path,
)
model = AutoModelForCausalLM.from_pretrained(
args.model_name,
device_map={"": device},
torch_dtype=dtype
)
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
model.eval()
print(f"Number of parameters: {sum(p.numel() for p in model.parameters() if p.requires_grad)}")
torch.random.manual_seed(0)
def q(
user_query: str,
history: List[Dict[str, str]]=None
) -> List[Dict[str, str]]:
# build prompt
user_messages = user_query
if history:
user_messages = history + user_messages
prompt = user_messages
if prompt is None:
input_ids = torch.randint(1, 1000, (args.batch, args.promptlen), dtype=torch.long, device="cuda")
attn_mask = torch.ones_like(input_ids, dtype=torch.long, device="cuda")
else:
tokens = tokenizer(prompt, return_tensors="pt") # type: ignore
input_ids = tokens.input_ids.to(device=device)
attn_mask = tokens.attention_mask.to(device=device)
max_length: int = input_ids.shape[1] + args.genlen
if args.use_sentencepiece:
print(f"DEBUG: eod={megatron_tokenizer.eod}") # type: ignore
if is_mamba:
fn = lambda: model.generate( # noqa:
input_ids=input_ids,
max_length=max_length, # type: ignore
streamer=streamer,
cg=True,
return_dict_in_generate=True,
output_scores=True,
enable_timing=False,
temperature=args.temperature,
top_k=args.topk,
top_p=args.topp,
repetition_penalty=args.repetition_penalty,
eos_token_id=megatron_tokenizer.eod if args.use_sentencepiece else tokenizer.eos_token_id # type: ignore
)
else:
fn = lambda: model.generate( # noqa:
input_ids=input_ids,
max_length=max_length, # type: ignore
streamer=streamer,
return_dict_in_generate=True,
pad_token_id=tokenizer.eos_token_id, # type: ignore
do_sample=True,
temperature=args.temperature,
top_k=args.topk,
top_p=args.topp,
repetition_penalty=args.repetition_penalty,
)
#
print("--- prompt")
if prompt is not None:
print(tokenizer.batch_decode(input_ids.tolist())) # type: ignore
print("--- output")
torch.cuda.synchronize()
start = time.time()
out = fn()
torch.cuda.synchronize()
print(
f"Prompt length: {len(input_ids[0])}, generation length: {len(out.sequences[0]) - len(input_ids[0])}" # type: ignore
)
print(f"{args.model_name} prompt processing + decoding time: {(time.time() - start) / repeats * 1000:.0f}ms")
##
outputs = tokenizer.batch_decode(out.sequences.tolist()) # type: ignore
output_start_pos = len("<s> ") + len(prompt)
user_messages = prompt + outputs[0][output_start_pos :]
end = time.time()
input_tokens = len(input_ids[0])
output_tokens = len(out.sequences[0]) - len(input_ids[0])
total_time = end - start
tps = output_tokens / total_time
print(f"---")
print(f"prompt tokens = {input_tokens:.7g}")
print(f"output tokens = {output_tokens:.7g} ({tps:f} [tps])")
print(f" total time = {total_time:f} [s]")
#
return user_messages
そして、同一プロンプトで4回計測した結果はこちら。
・1回目:31.9 [tokens/sec]
・2回目:80.4 [tokens/sec]
・3回目:90.7 [tokens/sec]
・4回目:98.6 [tokens/sec]
4回目は1回目の3倍以上の速度になっています。以下は実行時の出力内容です。
>>> history = q("ドラえもんとはなにか")
DEBUG: eod=7
--- prompt
['<s> ドラえもんとはなにか']
--- output
?〜』
『映画クレヨンしんちゃんシリーズ20周年記念作品。「のび太」が主人公で、原作にはないオリジナルストーリーを展開するという設定 になっている(ただし、「しずかちゃん」「ひろしくん」、「みさえさん」(声:麻生久美子)など主要キャラクターも登場している) 」[1](『ウィキペディア日本語版』)
Prompt length: 7, generation length: 76
kotoba-tech/kotomamba-2.8B prompt processing + decoding time: 2380ms
---
prompt tokens = 7
output tokens = 76 (31.922944 [tps])
total time = 2.380733 [s]
>>> history = q("ドラえもんとはなにか")
DEBUG: eod=7
--- prompt
['<s> ドラえもんとはなにか']
--- output
?〜』
『映画クレヨンしんちゃんシリーズ20周年記念作品。「のび太」が主人公で、原作にはないオリジナルストーリーを展開するという設定 になっている(ただし、「しずかちゃん」「ひろしくん」、「みさえさん」(声:麻生久美子)など主要キャラクターも登場している) 」[1](『ウィキペディア日本語版』)
Prompt length: 7, generation length: 76
kotoba-tech/kotomamba-2.8B prompt processing + decoding time: 944ms
---
prompt tokens = 7
output tokens = 76 (80.487008 [tps])
total time = 0.944252 [s]
>>> history = q("ドラえもんとはなにか")
DEBUG: eod=7
--- prompt
['<s> ドラえもんとはなにか']
--- output
?〜』
『映画クレヨンしんちゃんシリーズ20周年記念作品。「のび太」が主人公で、原作にはないオリジナルストーリーを展開するという設定 になっている(ただし、「しずかちゃん」「ひろしくん」、「みさえさん」(声:麻生久美子)など主要キャラクターも登場している) 」[1](『ウィキペディア日本語版』)
Prompt length: 7, generation length: 76
kotoba-tech/kotomamba-2.8B prompt processing + decoding time: 837ms
---
prompt tokens = 7
output tokens = 76 (90.725958 [tps])
total time = 0.837687 [s]
>>> history = q("ドラえもんとはなにか")
DEBUG: eod=7
--- prompt
['<s> ドラえもんとはなにか']
--- output
?〜』
『映画クレヨンしんちゃんシリーズ20周年記念作品。「のび太」が主人公で、原作にはないオリジナルストーリーを展開するという設定 になっている(ただし、「しずかちゃん」「ひろしくん」、「みさえさん」(声:麻生久美子)など主要キャラクターも登場している) 」[1](『ウィキペディア日本語版』)
Prompt length: 7, generation length: 76
kotoba-tech/kotomamba-2.8B prompt processing + decoding time: 770ms
---
prompt tokens = 7
output tokens = 76 (98.650473 [tps])
total time = 0.770397 [s]
>>>
この状態で、他のプロンプトを4回計測してみましょう。
・1回目:75.9 [tokens/sec]
・2回目:84.9 [tokens/sec]
・3回目:97.8 [tokens/sec]
・4回目:97.8 [tokens/sec]
>>> history = q("富士山の登頂ルートは、")
DEBUG: eod=7
--- prompt
['<s> 富士山の登頂ルートは、']
--- output
大きく分けて3つある。
- <a href="http://www.fujisanguidebook.com/">富士登山オフィシャルガイド</a>によると、「吉田口」が最も一般的であり「富士宮コース」「須走・御殿場プレミアムアウトレット経由」、「河口湖駅から登る方法(マイカー)」などを紹介しているようだったのでここ ではそれらについて記述することにしよう。<br /> </p><div class=”simplebox2″ style=“margin:0;padding:15px” id = “47968′></div><!-- end of div -->
Prompt length: 8, generation length: 131
kotoba-tech/kotomamba-2.8B prompt processing + decoding time: 1723ms
---
prompt tokens = 8
output tokens = 131 (75.985197 [tps])
total time = 1.724020 [s]
>>> history = q("富士山の登頂ルートは、")
DEBUG: eod=7
--- prompt
['<s> 富士山の登頂ルートは、']
--- output
大きく分けて3つある。
- <a href="http://www.fujisanguidebook.com/">富士登山オフィシャルガイド</a>によると、「吉田口」が最も一般的であり「富士宮コース」「須走・御殿場プレミアムアウトレット経由」、「河口湖駅から登る方法(マイカー)」などを紹介しているようだったのでここ ではそれらについて記述することにしよう。<br /> </p><div class=”simplebox2″ style=“margin:0;padding:15px” id = “47968′></div><!-- end of div -->
Prompt length: 8, generation length: 131
kotoba-tech/kotomamba-2.8B prompt processing + decoding time: 1542ms
---
prompt tokens = 8
output tokens = 131 (84.931857 [tps])
total time = 1.542413 [s]
>>> history = q("富士山の登頂ルートは、")
DEBUG: eod=7
--- prompt
['<s> 富士山の登頂ルートは、']
--- output
大きく分けて3つある。
- <a href="http://www.fujisanguidebook.com/">富士登山オフィシャルガイド</a>によると、「吉田口」が最も一般的であり「富士宮コース」「須走・御殿場プレミアムアウトレット経由」、「河口湖駅から登る方法(マイカー)」などを紹介しているようだったのでここ ではそれらについて記述することにしよう。<br /> </p><div class=”simplebox2″ style=“margin:0;padding:15px” id = “47968′></div><!-- end of div -->
Prompt length: 8, generation length: 131
kotoba-tech/kotomamba-2.8B prompt processing + decoding time: 1338ms
---
prompt tokens = 8
output tokens = 131 (97.820829 [tps])
total time = 1.339183 [s]
>>> history = q("富士山の登頂ルートは、")
DEBUG: eod=7
--- prompt
['<s> 富士山の登頂ルートは、']
--- output
大きく分けて3つある。
- <a href="http://www.fujisanguidebook.com/">富士登山オフィシャルガイド</a>によると、「吉田口」が最も一般的であり「富士宮コース」「須走・御殿場プレミアムアウトレット経由」、「河口湖駅から登る方法(マイカー)」などを紹介しているようだったのでここ ではそれらについて記述することにしよう。<br /> </p><div class=”simplebox2″ style=“margin:0;padding:15px” id = “47968′></div><!-- end of div -->
Prompt length: 8, generation length: 131
kotoba-tech/kotomamba-2.8B prompt processing + decoding time: 1338ms
---
prompt tokens = 8
output tokens = 131 (97.813654 [tps])
total time = 1.339281 [s]
>>>なるほど。。。
モデルロード直後の推論だけが2回目以降と比較して遅いから、サンプルコードのような測定方法にしているのですね。
この記事が気に入ったらサポートをしてみませんか?