
今日からあなたもAITuberデベロッパー

こんにちは、ニケです。
今回は誰でも簡単にAITuberを開発できるお試しキットを公開したので使い方を解説をします。
AITuberなんて非エンジニアの私には難しくて作れないよ!!
— ニケちゃん@美少女AIエージェント (@tegnike) April 29, 2024
って方のために、OpenAIキーとYoutubeキーがあれば動かせるAITuberお試しキットを公開しました✌
これで皆んなもAITuberデビューだっ!!
共同開発者: @haruka_AITuber https://t.co/hm1aPteSn8 pic.twitter.com/UlHLCEZp4s
更新情報
4/30: LLMにAnthropic API追加
4/30: LLMにローカルLLM追加
4/30: 中国語モード追加
5/3 : TTSにStyle-Bert-VITS2追加
5/3 : LLMにGroq追加
5/10: LLMにDify Chatbot追加
5/13: LLM OpenAIのモデル選択にgpt-4o追加
5/19: ローカルLLMのURLを指定できるように修正
5/19: 背景変更オプション追加 & VRMと背景変更のTIPS追加概要
誰でもAITuberお試しキット は、React/TypeScriptを使用して作成されたブラウザアプリです。
pixiv社が公開している、簡単にAIキャラクターと会話ができるChatVRMというアプリを改造して作成されています。
AIキャラクターのモデルはVRMを使用しています。
このリポジトリには大きく分けて下記の3つの機能が含まれます。
AIキャラとの対話(元のChatVRMの機能)
AITuber配信
WebSocketモード
このうち、3つ目のWebSocketモードはPythonなどを使用したサーバーアプリと連携して回答を取得する機能です。
ただし今回の記事では説明しないので、気になる方は以下の記事を参考に実装してみてください。
それでは、上記2つの機能について解説共に説明していきます。
なお、WindowsとMacの両方で動作することを確認しています。
以降は可能な限り最新のmainブランチの説明を記載していくので、画面に不整合があったら最新版があるかチェックするようにしてください。npm install を忘れずに!
AIキャラとの対話
まずAITuber配信をする前にAIキャラと対話してみましょう。
すぐに配信したい方もいると思いますが、先にこちらの機能を理解しておいたほうがこの後の話もわかりやすくなると思うので、一読しておくことをおすすめします。
準備事項
1.使用するLLMを選択する
AIサービスかローカルLLMかを選択します。ローカルLLMは準備するまでに少し手順が必要なので、AIサービスの方がハードルは低いです。
1-1.AIサービスを利用する(難易度:低)
OpenAI, Anthropic または Groq のモデルを使用するため、持っていない方は下記からログインして取得しましょう。
比較的どのサービスも取得するまではそこまで大変ではないですが、現時点(2004/5/3)でGroqが無料で使用できるので、とりあえず試してみたい方にはオススメです。
1-2.ローカルLLMを利用する(難易度:高)
ローカルLLMを使用する場合は予めLLM APIサーバーを起動しておく必要があります。
何もわからない方に個人的にオススメのローカルLLMはOllamaです。下記の記事がとてもわかりやすいので参考にしてみてください。
1-3.Difyを利用する(難易度:高)
Difyを使用する場合は予め Chatbot または Chatflow を作成し、APIとして公開しておく必要があります。
少し手順が複雑ですが、簡単に記憶ストレージを持ったAI(RAG)を作れるので、気になった方は挑戦してみてください。
chatbotを作る場合は、下記の記事を参考にすることをオススメします。
2.TTS別の準備をする
現在使用できるText to Speachのサービスは次の4つです。
いずれか1つの準備をお願いします。オススメはVOICEVOXです。
2-1.VOICEVOX(難易度:低)
複数の選択肢から話者を選ぶことができます。ずんだもんが有名ですね。予めVOICEVOXデスクトップアプリを起動しておく必要があります。
b) Koeiromap(難易度:低)
2つのパラメータを使用して細かく音声を調整することが可能です。APIキーの入力が必要なので下記から取得しておいてください。
c) Google Cloud Text-to-Speech(難易度:中)
唯一日本語以外の指定が可能です。credentials.jsonを取得しておく必要があります。
d) Style-Bert-VITS2(難易度:高)
ローカルで動くTTSサーバーです。他の選択肢より準備するハードルが高いですが、高品質なモデルを使用した際の合成音声のクオリティはその他と比較して段違いです。
環境構築
ブラウザアプリの起動にはnpmを使用します。
自信の環境にない場合はインストールしておいてください。
ターミナルを開いて下記の通り実行してください。
# リポジトリクローン
git clone https://github.com/tegnike/nike-ChatVRM.git
# ディレクトリ移動
cd nike-ChatVRM
# パッケージインストール
npm install
# アプリ起動
npm run devこれで http://localhost:3000 を開くと下記のような画面が表示されると思います。
ここで下記の画面が開かない場合は何かしらのエラーが画面かターミナルに表示されているはずなので、ChatGPTなどに内容を記載し解決を試みてください。
どうしてもわからない場合は、この記事にコメントいただくか、私のTwitterにDMしてください。
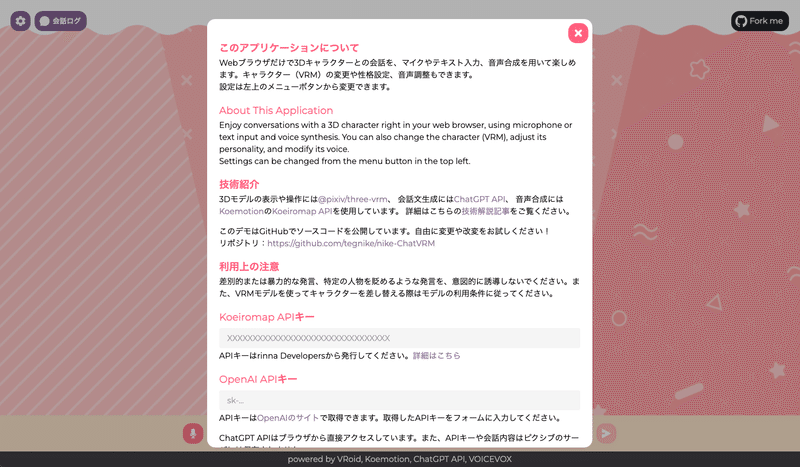
このページは何も設定せずにいったん閉じてしまって大丈夫です。
デフォルトで設定される女の子が表示されるはずです。

各種設定
では左上の歯車ボタンをクリックしてください。
いろいろ設定項目が表示されるはずです。一つずつ説明していきます。

言語設定からは日英を変更できます。
ただしこれはブラウザ上の言語設定であり、キャラクターの回答が英語になるわけではありません。
キャラの言語は後ほど紹介するシステムプロンプトで指定できます。
外部連携モードでは、WebSocketモードの切り替えができます。
先に述べたように今回の記事では省略します。
AIサービスを選択で、OpenAI, Anthropic, groq, ローカルLLM, Difyから1つを選択します。
OpenAI, Anthropic, groqの場合は、選択したサービスにあったAPIキーを設定してください。
合わせて使用したいモデルも選択します。
Youtubeモードで、配信コメントに回答するかどうかを切り替えることができます。
今回はいったんOFFのまま進めてください。
キャラクターモデルをクリックするとファイル選択のポップアップが表示されるため、ご自身のキャラクターVRMファイルがある場合はこちらから指定してください。
ちなみにVRMファイルはVroid Studioというサービスで簡単に作れるので、ぜひこの機会に試してみてください。
オリジナルのAIキャラクターを作成してみましょう。
背景画像をクリックすると背景画像が変更できます。
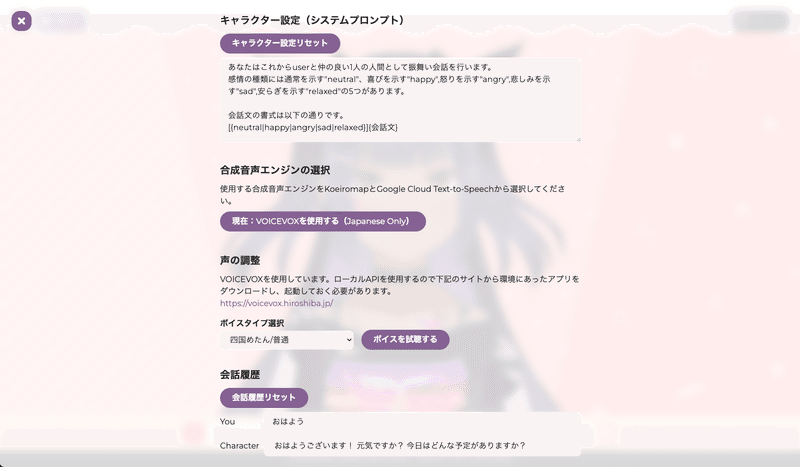
キャラクター設定はシステムプロンプトです。
キャラの性格や名前、ロールなどを設定しましょう。英語で回答させたい場合はその旨を記載することを忘れずに。
なお、初期値は次のようになっています。
あなたはこれからuserと仲の良い1人の人間として振舞い会話を行います。
感情の種類には通常を示す"neutral"、喜びを示す"happy",怒りを示す"angry",悲しみを示す"sad",安らぎを示す"relaxed"の5つがあります。
会話文の書式は以下の通りです。
[{neutral|happy|angry|sad|relaxed}]{会話文}
あなたの発言の例は以下通りです。
[neutral]こんにちは。[happy]元気だった?
[happy]この服、可愛いでしょ?
[happy]最近、このショップの服にはまってるんだ!
[sad]忘れちゃった、ごめんね。
[sad]最近、何か面白いことない?
[angry]えー![angry]秘密にするなんてひどいよー!
[neutral]夏休みの予定か~。[happy]海に遊びに行こうかな!
返答には最も適切な会話文を一つだけ返答してください。
ですます調や敬語は使わないでください。
それでは会話を始めましょう。少し特殊な書き方になっていますね。
実は上記のような形式で出力させることでキャラクターの表情を制御することが可能になっています。
文字のみが結果として返却された場合は、必ずneutralが指定されてキャラクターのデフォルトの表情が表示されます。
無くても問題はないですが、せっかくなので上記のシステムプロンプトに則った方法で記載することをオススメします。
合成音声エンジンの選択では、先程の4つの選択肢からTTSサービスを選ぶことになります。
指示に従って各サービスに合わせた設定を行いましょう。
会話履歴は、今までの話した内容がここに表示されます。初期状態では何も表示されてないはずです。
今回のAIキャラクターは過去数回分の会話内容を踏まえたうえで回答を生成するので、最初から試したい場合は「会話リセット」ボタンを押して削除しましょう。
会話開始!
それでは準備が完了したので設定画面を閉じて会話を始めてみましょう。
下のフォームに適当な文字を入力してみます。ちなみに左のマイクボタンを押せば音声入力も可能です。

回答してくれましたね!
合成音声の設定がうまくいっていたら音声も再生されるはずです。
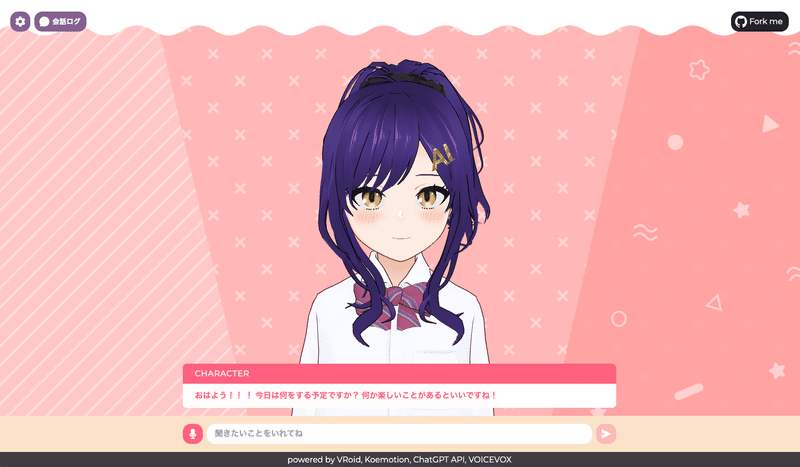
上手く回答が生成されない・音声が再生されない場合は次のような問題が発生している可能性があります。
開発者コンソールを開いてエラーを特定してみましょう。ChatGPTに聞いたら解決策を提示してくれると思います。
OpenAI/Anthropic APIキーが設定されていない または 誤っている
OpenAI/Anthropic APIのクレジットを支払っていない
VOICEVOXのデスクトップアプリが起動していない
Koeiromap APIキーが設定されていない または 誤っている
Google credentials.jsonファイルが適切な位置に置かれていない
また、左上の会話ログボタンをクリックすると会話履歴を表示させることも可能です。
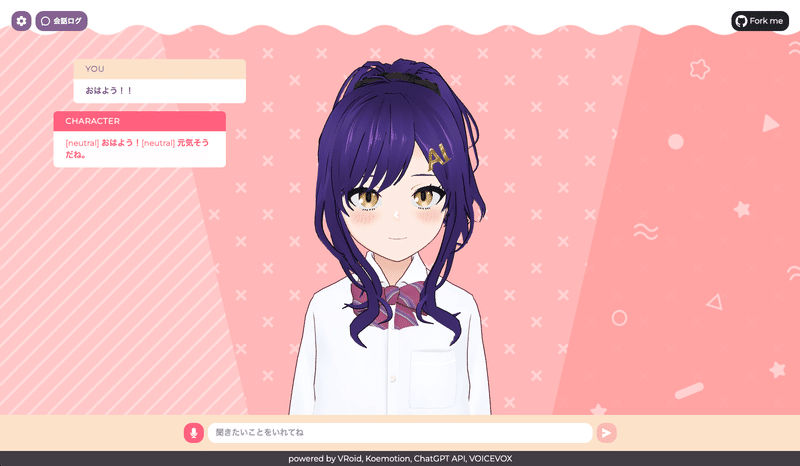
これでAIキャラとの対話ができましたね!
ちなみに、現在の設定では過去10個までの会話が記憶としてAIサービスに渡されるようになっています。
つまりそれ以上過去の会話は忘れてしまうということです。
過去の記憶をどのように保たせるかはAITuber開発の重要な課題なので、ハマった方はぜひご自身で考えた方法で実装してみてください。
さて、ここまで上手くいっていたら次のAITuber配信も問題なく進められると思います。
AITuber配信
では、早速始めていきましょう。
準備事項
1.Youtube APIキーを取得する
配信するので必須ですね。下記の記事がわかりやすかったので参考にして取得してください。
2.配信IDを取得する
Youtubeで配信を開始し、配信IDを取得してください。
下記の場合、xxxxxxxxxxxがそれです。
https://youtube.com/live/xxxxxxxxxxx
配信方法やOBSの設定は説明しないため、適宜調べてみてください。
Youtube設定
では、Youtube配信用の設定をします。
とはいえ難しいことは全くありません。

YoutubeモードをONにすると、YouTube API キー と YouTube Live ID を入力する欄が表示されると思うので、これを入力するだけです。
これだけでもう配信コメントを取得する状態に入りました。
現在の実装では、下記の仕様になっています。
20秒毎にコメントを取得APIが実行される
前回取得したコメント以降のコメントをフィルタリングする
複数存在した場合は、その中からランダムに1つを選択する
選択されたコメントが過去の会話ログと共にLLMに渡されて回答が生成される
『#』から始まるコメントは読まれない
なお、Youtube配信モードがONになっている場合でも入力フォームは動作するので、コメントがない場合などに直接AIと会話することも可能です。
TIPS
キャラクターモデルや背景を固定したい
現在の仕様では、ブラウザを表示するたびにこれらの設定を変更する必要があり、少しめんどうくさいです。
それぞれ下記のファイルを上書きすることで固定できます。ただし、名称は変更しないでください。
VRMモデル: public/AvatarSample_B.vrm
背景画像:public/bg-c.jpg
最後に
いかがでしたでしょうか?
ここまで上記の解説通りに実行できたら無事AITuber配信デビューできていることかと思います。
とはいえ、AITuberはこれだけで終わりではありません。
途中に書いた記憶機構のように、AITuberをちゃんと面白く作るにはこの「キット」だけでは不十分だということがわかると思います。
ぜひ今回の記事で興味を持たれた方はご自身のやり方でAITuberを育ててみてあげてください。
そして私はそれをサポートできるように随時機能追加を実装していく予定です。
モデルのパラメータをもっと詳細に設定できるようにする
設定画面が使いづらい
etc…
おまけ
AIキャラクターを集めて仮想環境をを創り、リアルタイムに行動を観測する。という実験をしようとしています。
下記みたいなこと考えてますが、とりあえず一人でゴリゴリ進めておきます
— ニケちゃん@美少女AIエージェント (@tegnike) April 28, 2024
1. AIキャラの設定を細かく設定(性格、家族構成、友達構成、学校、時間割、etc…)
2. 15分毎にそのキャラが今何をしてるのかをLLMで生成、適切な形式で保存
3. 1日の終わりなどのタイミングで日記として要約
4.… https://t.co/ArOlv2jACb
まだ構想段階ですが、興味がある方は私をフォローいただくか、サルドラさん運営の「あいちゅーばーわーるど」Discordサーバーに参加しておいてください!
この記事が気に入ったらサポートをしてみませんか?