manga109のキャラ画像加工②

背景
所属研究室で行っている研究の一環として、漫画用のキャラクタ画像データセットを構築する試みを検討している。manga109 という学術用の許可済み漫画画像データセットが存在するが、そのままではキャラクタの画像が切り抜かれていないため加工して使用することにした。これら処理を行うためにpythonの調査を行い実践しまとめていく。
仕様
最終的な処理から逆算して仕様を決めていく。最終的には特定の画像から(xmin, ymin), (xmax, ymax)の座標を切り抜くつもりである。

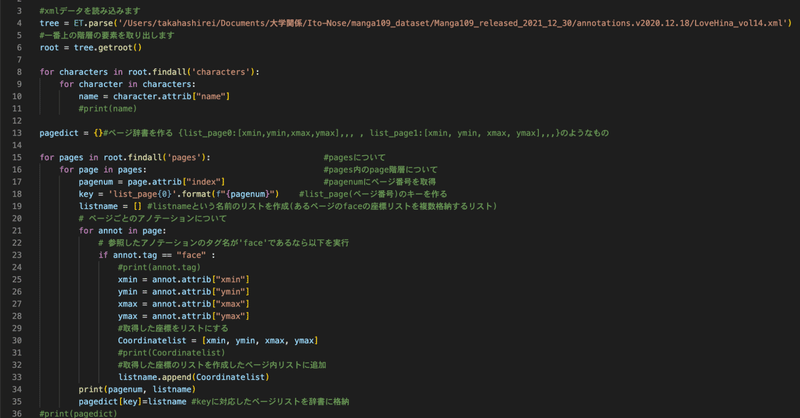
検討した結果、上記のような擬似コードを考えた。manga109のアノテーションには顔と身体の領域座標が含まれているため、それを取得して該当のページから画像を切り出して保存するという流れである。
PILからImageモジュールを読み込んでクロップする方法が見つかったのでこれを採用する。クロップに必要な座標の形式は4数字の列であったので、この形式でxml上の座標を取得できればよい。
ページ情報の取得
先に完成したコードを書いておく。のちのちデータを利用しやすくするために解説の図とは少し異なる(page番号をint型に変換したり、ディクショナリーのキーを単純な数字にしたり)が、本質的には変わっていない。
import xml.etree.ElementTree as ET
tree = ET.parse(xmlのパス)
root = tree.getroot()
for characters in root.findall('characters'):
for character in characters:
name = character.attrib["name"]
#print (name)
pagedict = {}
for pages in root.findall('pages'):
for page in pages:
pagenum = page.attrib["index"]
key = int(pagenum)
listname = []
for annot in page:
if annot.tag == "face" :
#print (annot.tag)
xmin = int(annot.attrib["xmin"])
ymin = int(annot.attrib["ymin"])
xmax = int(annot.attrib["xmax"])
ymax = int(annot.attrib["ymax"])
Coordinatelist = [xmin, ymin, xmax, ymax]
listname.append(Coordinatelist)
#print (pagenum, listname)
pagedict[key]=listname #keyに対応したページリストを辞書に格納 #print (pagedict)
manga109データセットにはページのアノテーションも施してあるため、利用する。アノテーションのページ数(page=数字)と実際の漫画ページの対応を調べたところ、原稿データの画像上のページ番号ではなく、見開きを1ページとしたmanga109のデータ形式に沿ったラベリングであった。よってxmlのアノテーション上のページ番号とそこに含まれる顔と身体の座標を取得すればよい。ページごとの処理になるので、アノテーションの各ページ番号に対してそれに対応するページの画像から画像を切り抜きそのページのフォルダを作成して格納することとする。作品は自分で指定するため、そこまでのパス指定は打ち込みで良いとしてページ番号を変数としてページ番号.jpgを参照せねばならない。

前回まではxml形式のデータから数字などを読み取るために、ひとまず上記のようなプログラムを作成し参照には成功した。しかし、ページの番号や座標を得るには至っていなかった。

最終的に上記のような完成版コードを作成した。今後のためにも一応自分なりに解説しておく。
キャラクタ名の参照

学習時に使用するかはわからないが、その巻に登場するキャラクタ名を一覧表示するプログラムの部分。まずxmlの読み込みには
import xml.etree.Elementtree as ETとモジュールを読みこむ。その後xmlをパースするにはET.parse(xmlファイルのパス)とすればよい。
root = tree.getroot()でxmlの階層の一番上(根本)を取得する。その後は根本からみて最も浅い階層の要素をroot.findall('要素名')で検索し、さらにその要素の中の階層を検索する。要素にはタグとアトリビュートがあるため、要素名.tagあるいは要素名.attribで取得することができる。今回、キャラクタ名は下記のようにnameという名前のアトリビュートをされていたのでcharacter.attrib=["name"]とすればキャラクタ名を参照できる。

ページ番号、face座標の参照

前述の擬似コードに書いたように、辞書型のデータを作成する。ページ番号の取得は上記のキャラ名取得と同様。ページ番号はpagenumという変数に格納し、format関数で変数を含むディクショナリーのキーを作成した。さらに辞書のキーに対応する要素としての「キーのページ内のface座標のリスト(listname)」を作成した。

要素<page>からみて最も浅い階層の全ての要素に対して、tag名がfaceであった場合にアトリビュート内の座標値を取得する。そしてそれをリスト形式でまとめ、作成したリストをlistnameのリストに格納した。すなわちlistnameリストは「4つの座標を持つリスト」のリストとなる。(ややこしい)
今注目しているページ内部の要素全てを参照し終えたら、そのページに対応した名称(list_page数字)をキーとし対応する値をlistname(そのページに存在する全てのface座標のリスト)として辞書を増やす。
まとめ
xmlの仕様の理解に苦労したが、なんとかページの座標データを思うようなデータ形式で抽出することができた。次はこのデータを参照して対応する画像データから画像を切り抜くプログラムを作成し、このプログラムと連動させていく。
この記事が気に入ったらサポートをしてみませんか?