manga109のキャラ画像加工④

背景
所属研究室で行っている研究の一環として、漫画用のキャラクタ画像データセットを構築する試みを検討している。manga109 という学術用の許可済み漫画画像データセットが存在するが、そのままではキャラクタの画像が切り抜かれていないため加工して使用することにした。これら処理を行うためにpythonの調査を行い実践しまとめていく。
前回まで
前回までで、各ページごとに存在する顔フォルダに対して画像を抽出することができた。
今回の目標
今回は、切り取った画像のサイズの確認を行う。
画像サイズの確認
Stable Diffusionの学習に用いる画像は512✖️512以上の解像度が望ましい。そこで顔や身体を切り取った際の解像度(ピクセル)をみてみる。
高さ=xmax-xmin, 幅=ymax - yminをそれぞれ求めれば良い。
import manga109_xmlread_body
import manga109_xmlread_face
import os
from PIL import Image
pagedict_face = manga109_xmlread_face.pagedict #変数の引き継ぎ、これで辞書が使える。
pagedict_body = manga109_xmlread_body.pagedict
pagesum = len(pagedict_face) #pagesumにpagedictの要素数を格納
os.mkdir('size_less_images')
#ページ数分だけ以下の処理を繰り返す
for num in range(pagesum):
Coordinatelist_face = pagedict_face[num] #pagedict辞書のnumキーに対応する要素(座標リスト)を格納
Coordinatelen_face = len(Coordinatelist_face) #キーのページにおけるface座標の個数を取得
Coordinatelist_body = pagedict_body[num]
Coordinatelen_body = len(Coordinatelist_body)
imagename = '/Users/takahashirei/Documents/大学関係/Ito-Nose/manga109_dataset/Manga109_released_2021_12_30/images/LoveHina_vol14/{0}.jpg'.format(f"{num:03}")
im = Image.open(imagename) #キーに対応する名称の画像を開く
# 座標の個数だけ以下を繰り返す
for facenum in range(Coordinatelen_face):
face = Coordinatelist_face[facenum] #座標リストのfacenum番目の座標をfaceに格納
#faceの座標の値を取得
xmin = face[0]
ymin = face[1]
xmax = face[2]
ymax = face[3]
width = xmax - xmin
hight = ymax - ymin
if width < 512 or hight < 512 :
facefilename = 'face_{0}_{1}_{2}_{3}_{4}.jpg'.format(num, xmin, ymin, xmax, ymax) # 切り抜いた後の顔の画像はface_ページ番号_座標.jpgの名称で保存する
savepass = 'size_less_images/'+ facefilename # ディレクトリ名と先ほど作成したファイル名をつなげ、保存用のパスとする。
im_crop = im.crop((xmin, ymin, xmax, ymax)) #画像のクロップ im_crop.save(savepass, quality=95) #画像の保存
for bodynum in range(Coordinatelen_body):
body = Coordinatelist_body[bodynum] #座標リストのfacenum番目の座標をfaceに格納
#faceの座標の値を取得
xmin = body[0]
ymin = body[1]
xmax = body[2]
ymax = body[3]
width = xmax - xmin
hight = ymax - ymin
if width < 512 or hight < 512 :
bodyfilename = 'body_{0}_{1}_{2}_{3}_{4}.jpg'.format(num, xmin, ymin, xmax, ymax) # 切り抜いた後の顔の画像はface_ページ番号_座標.jpgの名称で保存する
savepass = 'size_less_images/'+ bodyfilename # ディレクトリ名と先ほど作成したファイル名をつなげ、保存用のパスとする。
im_crop = im.crop((xmin, ymin, xmax, ymax)) #画像のクロップ im_crop.save(savepass, quality=95) #画像の保存
前回までのコードの流用なので解説は省く。今回は高さ、幅のどちらか一方でも512より小さい場合、その画像を作成したディレクトリに保存することにした。(サイズの足りない画像はそんなに多く無いと予想したため。)また顔と体のフォルダは分けていない。
最終的に、顔画像、身体画像、サイズ不足画像の枚数を比較したいため、下記のプログラムも作成した。ChatGPTに聞いたらすぐ書いてくれてエラーも無かった。
import os
def count_files_in_directory(directory):
total_files = 0
for root, dirs, files in os.walk(directory):
total_files += len(files)
return total_files
# 特定のディレクトリのパスを指定してください
target_directory = './cut_body_pages'
bodynum = count_files_in_directory(target_directory)
print(f'Total number of body files in {target_directory}: {bodynum}')
target_directory = './cut_face_pages'
facenum = count_files_in_directory(target_directory)
print(f'Total number of face files in {target_directory}: {facenum}')
imagesum = bodynum + facenum
print(imagesum)
target_directory = './size_less_images'
sizelessnum = count_files_in_directory(target_directory)
print(f'Total number of sizeless files in {target_directory}: {sizelessnum}')
実行したところ、
Total number of body files in ./cut_body_pages: 2178
Total number of face files in ./cut_face_pages: 1551
合計3729
Total number of sizeless files in ./size_less_images: 3720
となった。すなわち全体で3729枚の顔、身体画像データが存在するにもかかわらず、幅もしくは高が512に達している画像はたった9枚!これは想像していたよりはるかに少ない。
ともかく、画像データは3500枚以上あったため追加学習に要する画像の量としては十分であることがわかった。一旦このままの解像度で学習をし、生成結果を見てから解像度にどういった加工を施すべきかを検討することとする。
さて、せっかくなので解像度の分布を知りたい。(pythonの勉強にもなるので)すなわち画像サイズで階級を設け、存在するデータの数の分布を調べることにする。
import manga109_xmlread_body
import manga109_xmlread_face
import os
pagedict_face = manga109_xmlread_face.pagedict #変数の引き継ぎ、これで辞書が使える。
pagedict_body = manga109_xmlread_body.pagedict
pagesum = len(pagedict_face) #pagesumにpagedictの要素数を格納
FaceMaxSize = 0
BodyMaxSize = 0
#ページ数分だけ以下の処理を繰り返す
for num in range(pagesum):
Coordinatelist_face = pagedict_face[num] #pagedict辞書のnumキーに対応する要素(座標リスト)を格納
Coordinatelen_face = len(Coordinatelist_face) #キーのページにおけるface座標の個数を取得
Coordinatelist_body = pagedict_body[num]
Coordinatelen_body = len(Coordinatelist_body)
# 座標の個数だけ以下を繰り返す
for facenum in range(Coordinatelen_face):
face = Coordinatelist_face[facenum] #座標リストのfacenum番目の座標をfaceに格納
#faceの座標の値を取得
xmin = face[0]
ymin = face[1]
xmax = face[2]
ymax = face[3]
width = xmax - xmin
hight = ymax - ymin
size_face = width*hight
if size_face > FaceMaxSize:
FaceMaxSize = size_face
for bodynum in range(Coordinatelen_body):
body = Coordinatelist_body[bodynum] #座標リストのfacenum番目の座標をfaceに格納
#faceの座標の値を取得
xmin = body[0]
ymin = body[1]
xmax = body[2]
ymax = body[3]
width = xmax - xmin
hight = ymax - ymin
size_body = width*hight
if size_body > BodyMaxSize:
BodyMaxSize = size_body
print(f'FaceMaxSize:{FaceMaxSize}', f'BodyMaxSize:{BodyMaxSize}')
まず、顔、身体の画像のうち最大の値はそれぞれどうなるかを調べるため以上のプログラムを作成した。結果は
FaceMaxSize:120396. BodyMaxSize:852271
とわかったため、横軸の最大値がそれぞれ上記の値に対応する。上記のコードに少し手を加え、
bodysizelist = [] #身体画像サイズを格納するリスト
bodysizelist.append(size_body) #身体画像サイズのリストに値を追加を導入する。こうすることでデータとして扱いやすくする。顔についても同様のデータを作成する。


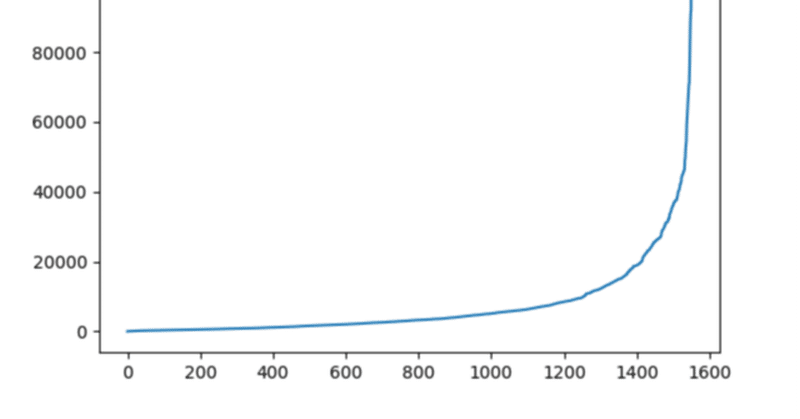
ほとんどの画像は250000画素以下であることがわかった。これは学習結果にかなり影響を及ぼすかもしれない。
まとめ
今回、顔画像と身体画像のサイズ分布を知ることができた。次はこれらの画像にアノテーションを自動で付与する手法について学びたい。具体的にはモノクロ画像にdeepdanbooruを作用させてテキストデータを作成する方法を検証する。
この記事が気に入ったらサポートをしてみませんか?