圧縮率による著者推定法のニンジャスレイヤーへの応用(ニンジャ学会誌894号掲載)

※本稿はニンジャ学会誌894号掲載の論文を、投稿規定に基づき半年以上の経過後に公開したものです
Applications of Authorship Attribution Using Data Compression Program for “Ninja Slayer”
NJRecalls開発チーム @NJRecalls *
ニンジャスレイヤーの著者としては、ブラッドレー・ボンド及びフィリップ・N・モーゼズの二名とする見解が公式のものである。これを日本語に翻訳及びTwitter連載する「翻訳チーム」についても、ボンド担当ユニットとモーゼズ担当ユニットがあると公式アカウントによる回答1)が為されており、Twitterクライアントの使い分けからも同様の示唆がされている2)。しかしながら作品全体としては共著とされ、各エピソードをどちらが主体となり執筆しているのかについては、原作者からのコメントで判明する場合を除いては基本的に公式に示されることはない。本研究では圧縮プログラムによる著者推定法3)をニンジャスレイヤーへ応用し、純粋に各エピソードの文章のみを用いて主観的判断抜きにどちらが主たる著者となっているか(あるいはどちらの担当翻訳ユニットが翻訳を行ったか)の判定を行えるような手段を提案するものである。
*: https://twitter.com/njrecalls
Keyword: 著者推定
背景
ニンジャスレイヤーの著者について、公式にはブラッドレー・ボンド及びフィリップ・N・モーゼズの共著とされており、実際の執筆においてはどちらかが主となる場合、共同して執筆していく場合などがあることが述べられている4)。しかしながら、この両名の実在性に関しては、英語圏での情報がほとんどなく、ニンジャスレイヤーという作品がある程度メジャーになった後も、公式の場に出ることが極めて稀であり、不確かであると言わざるをえない。彼らの作品を日本語に翻訳して公開しているという翻訳チームについても、Twitterにおける公式アナウンスは極めて胡乱なもの5)であり、タイピストが複数存在していること6)、海外の翻訳チームも存在していること7)、犬などの動物やエルフなどの空想存在までもが所属している8)ように述べられており、信憑性が薄い。従って彼らの実態に関しては、アナウンスよりも活動そのものから推し量る方が妥当であろう。
翻訳チームの活動は、第一にTwitterにおいてニンジャスレイヤーの各エピソードを翻訳、公開していくことである。この際にTwitter投稿に用いられているクライアントに二種類の傾向があり、iPhone用のクライアントを用いるユニットとSaezuriを用いるユニットが存在すること、この2ユニットがボンド、モーゼズをそれぞれ担当しているであろうことが先行研究2)によって示唆され、これは翻訳チームのアナウンスによる裏付けもなされていることからほぼ確実とみてよいであろう。また、物理書籍発行に当たっては翻訳チームに所属しているとされる二名、「杉ライカ」「本兌有」がクレジットされており9)、公の場にも(サイバーサングラスやメンポなどを着けているため確実ではないが)姿を現している。先の2チーム制と合わせて考えると、ほぼこの2名が翻訳チームの実態であり、それぞれボンドとモーゼズを担当して連載を行っているとみてよいであろう。
しかしながら、これらはいずれも状況証拠であり、実際に文章を記述している存在が一体何名いるのか、文体からそれを推し量ることができるのかについては、読者の主観的な感覚によるものであった。
小説等の文字列情報から、文や単語の長さ、各単語の出現率などの統計的情報を抽出し比較する計量文体学という分野がある。コンピュータの発達に伴い、統計解析の手法は高度化し、扱う対象も従来の小説に加えてインターネット上のマイクロブログなどに広がりを見せている。その一種として、一風変わってはいるが簡便な存在が圧縮プログラムを応用したものである3)。圧縮プログラムを文字列情報に適用する際には、繰り返し出現する文字列に何らかの記号を割り当てて置き換えていくことにより全体の長さを縮小する辞書式圧縮、出現するバイト列の頻度に応じて高頻度であれば短く、定頻度であれば長いバイト列を割り当てるハフマン符号などを用いる。この圧縮プログラムを例えば2つの小説を連結したものに適用した時に、2つの小説に共通する単語や文字列が多ければ多いほど、単独で圧縮した際よりも連結して圧縮した際の圧縮率が向上することになる(図1.)。

図1. 圧縮プログラムの原理と連結圧縮した際の圧縮率向上
テキストAには「イヤーッ!」が複数回出現しているため、これを短い文字列に置き換えることでテキストA’ではAの66.6%まで圧縮することができる。テキストBとB’に関しても同様に83.3%まで圧縮することができる。
ここで、テキストAとテキストBを連結してから圧縮すると、双方に登場している文字列をさらにまとめて置き換えることができるため、圧縮率は55.9%にまで向上する。
本論文ではこのような先行研究の手法を準用し、かつ、著者が判明している文章を対照に使用することが困難なニンジャスレイヤーというシリーズの事情に適用するため、クラスタリング手法を用いてエピソード間の関係を推測する方法を提案する。結果として本手法を用いた解析を幾つか提示し、今後の可能性についても述べたい。
方法
圧縮率による著者推定の先行研究に則り、圧縮改善係数を以下のように定義した。
圧縮改善係数 = (A’/A + B’/B) - ((AB)’+(BA)’)/AB
ここで、A, Bはそれぞれ文字列A, Bのサイズ、A’, B’はそれぞれを単独で圧縮した後のサイズ、ABは文字列A,Bを連結したサイズ、(AB)’, (BA)’は文字列A, Bの順で連結してから圧縮した後のサイズ、B, Aの順で連結してから圧縮した後のサイズを表す。
圧縮プログラムにはgzipを使用した。先行研究によればbzipで最も良好な結果が出ているため、さらなる精度改善の余地はあるが、個々のエピソード間比較というよりもクラスタリング手法を使用しているため、さほどの影響はないものと考える。
前述した圧縮改善係数は、例えばABの値とCDの値を直接比較できる性質のものではなく、あくまで(AB)’>(AC)’であった時にCよりもBの方がAに似ていると推測されるものである。クラスタリングを行うため、ある文字列に結合して得た複数の圧縮改善係数((AB)’, (AC)’, (AD)’…)のうち、最低値を0(最も似ていない)、最高値を1(最も似ている)として相対値化した。
圧縮改善係数の計算とクラスタリング用データの生成には本研究のため新たに開発したソフトウェアを使用した10)。この際、同一エピソード同士を連結して圧縮した場合は圧縮改善係数を算出せず、クラスタリング用データでは1(最も似ている)を使用している。
クラスタリング解析にはRを使用し、クラスタリング手法としてはウォード法を使用した。階層的手法の中では分類感度が高いとされており、著者及び翻訳者の人数が不明なニンジャスレイヤーシリーズに適していると考えたからである。
データ元にはテキスト化が容易なTwitter連載版を主に使用し、文字列からノンブル、タイトルコールやアイキャッチ、空白文字の除去を行った。対照として使用したアーサー・コナン・ドイルの作品に関しては青空文庫のテキストを使用した。
結果
1.第二部16エピソードのクラスタリング
圧縮改善係数による著者推定法は、原理上その文字列にある程度の長さを必要とするものと考えられ、実際に先行研究でも30000文字という文字列長を使用している。本研究でもまずは先行研究に習い、30000文字に近付くようにセクションの多いエピソードを対象とすることとした。なおかつ、著者とエピソードの対応がすでに明らかになっているものとして、物理書籍第二部最終巻の巻末に掲載されている原著者のインタビューを基に、16エピソードを選出した(リストは図2.を参照)。
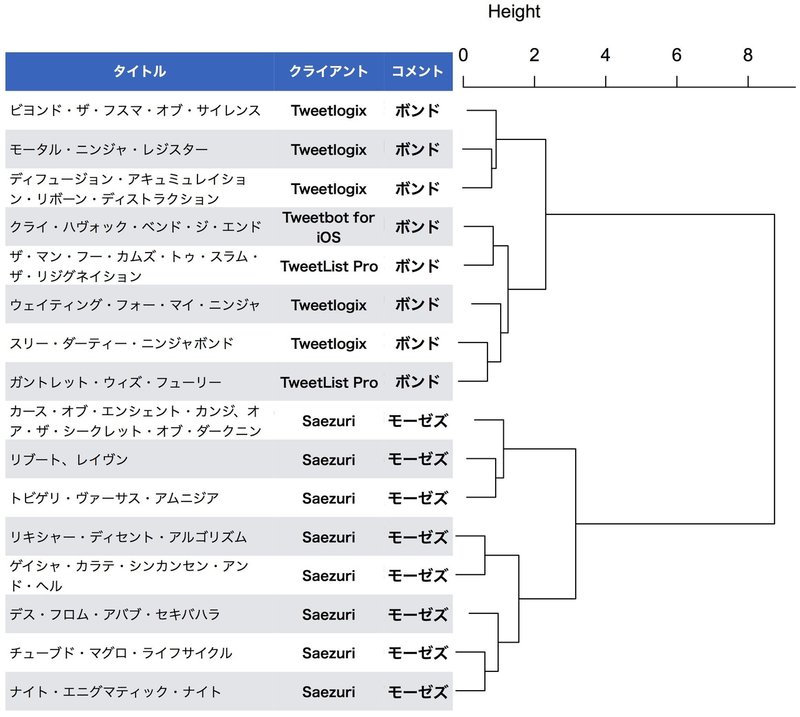
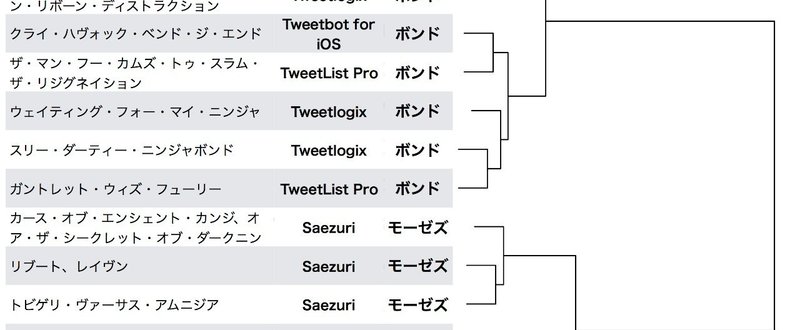
図2. 第二部16エピソードを使用した圧縮改善係数によるクラスタリング結果と原作者コメント、連載時Twitterクライアントの対応
図の右側は対象とした16エピソードの相互圧縮改善係数によるクラスタリング結果、左表にはエピソードタイトル、連載時のTwitterクライアント、第二部物理書籍最終巻の原作者コメント担当を付記している。
図2.を一見して分かるように、本手法により16エピソードは明確な2種のクラスターに分けられた。かつ、その2種はTwitter連載時のクライアント及び第二部最終巻巻末コメントの原作者と一致しており、本手法により、純粋な文字列情報から二人の原作者を担当する二つの翻訳ユニットを区別できることが示された。
2.翻訳ユニットの区別に必要な文字数
一般的な計量文体学、また本論文で採用した圧縮改善係数を用いた手法においても、原理上元となる文字列が十分な長さを持つことが必要となる。一つの基準として先行研究では30000文字という文字数を提示しているが、ニンジャスレイヤーという作品は短編も多く、そのような手法を適用するのに十分な文字数がない場合が予想される。また、本論文の手法は複数の圧縮改善係数を用いてクラスタリングによって結果を出すために、最低限どの程度の文字数が必要であるかは未知であった。このため、結果1と同様の手法を用いながら段階的に使用する文字数を減少させていき、二つの翻訳ユニットを区別するのに必要な文字数を明らかにすることを試みた。

右表ではさらに文字数を段階的に減少させていった場合に、クラスタリング結果がどの程度影響を受けるかを示した。5000文字まで減少させても各ユニットは別々の明瞭なクラスターを形成するが、2500文字まで減少した場合区別できなくなった。
結果を表1.に示す。文字数を5000文字まで減少させても二つの翻訳ユニットは別々な明瞭なクラスターを形成したことから、最低限5000文字程度の文字列があれば、二つの翻訳ユニットの訳文を区別できるであろうことが推測される。
3.無関係な文字列の判定
それでは、ニンジャスレイヤーと全く関係のない文字列を対象に加えた場合はこれらを区別できるのであろうか?この点を確かめるため、著作権の切れた文学作品を主に収載している青空文庫より、アーサー・コナン・ドイルのシャーロック・ホームズシリーズの6作品8データを加えてクラスタリングを行った。8データとなっているのは、同一作品で異なる訳者の場合を含めているためである(この点も比較対象として興味深い)。
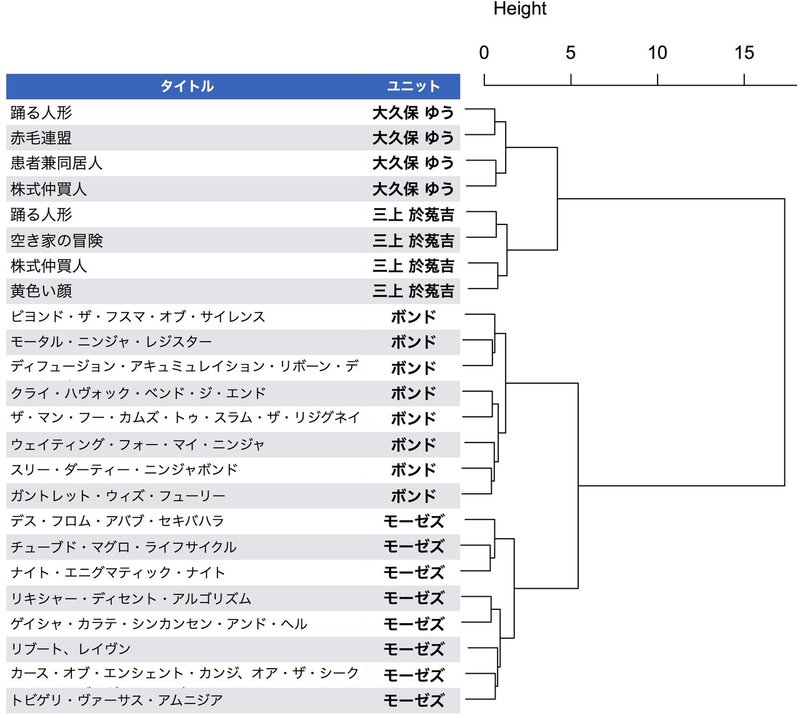
図3. 第二部及びシャーロック・ホームズシリーズエピソードを加えたクラスタリング
図2の16エピソードにシャーロック・ホームズシリーズ6エピソード(8データ)を加えたクラスタリングの結果。各エピソードには翻訳者あるいは翻訳ユニットを付記した。
結果を図3に示した。ニンジャスレイヤーの2翻訳ユニットは、シャーロック・ホームズシリーズとはさらに異なったクラスターに分類されていることがわかる。一方で、シャーロック・ホームズシリーズの翻訳者二名も二つのクラスターに分かれている。青空文庫の大久保 ゆう訳シャーロック・ホームズシリーズは三上 於菟吉訳の改訳であるが、本手法が翻訳者による文体の差異を識別できていることの傍証となりうるであろう。いずれにせよ、この結果よりニンジャスレイヤーとは何の関係もない文学作品であれば、二つの翻訳ユニットよりもさらに離れたクラスターとして分類できることが示された。
4.第一部/第三部エピソードの著者(担当翻訳ユニット)判定
第二部の16エピソードが二つの翻訳ユニットに由来すると思われる二つの明瞭なクラスターに分けられることは既に示した。ここで、第一部や第三部といった訳出時期の異なるエピソードでは、翻訳技術の向上や、原作自体のアトモスフィア、登場人物という要素の変動により、クラスタリング結果に影響が出ることが予想される。この点を検証するため、第一部/第三部よりそれぞれ十分な長さを持つ4エピソードを選び出し、先の第二部16エピソードと共にクラスタリングを行った。
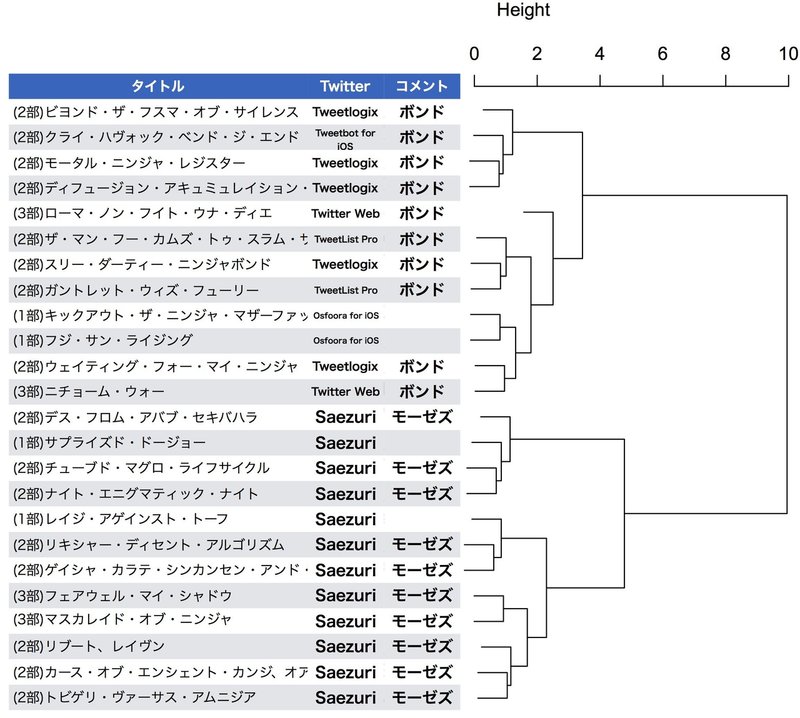
図4. 第二部、第一部、第三部エピソードのクラスタリング
図2の16エピソードに第一部4エピソード、第三部4エピソードを加えたクラスタリング。連載時のTwitterクライアント及び、コメントしている原作者を付記した。
結果を図4に示した。前述したような難点が予想されながら、第一部/第三部のエピソードを加えても二つの翻訳ユニットを区別できることがわかる。興味深い点としては、原作者ボンドにより極めて詳細な戦闘描写が試みられたとされているローマ・ノン・フイト・ウナ・ディエが、ボンド側クラスターでも特異な位置に分類されていることがある。
5.翻訳チームオリジナル/二次創作作品の著者推定
これまで示してきたように、本手法により文字列のみを入力としてニンジャスレイヤーの二人の原作者、ボンドとモーゼズそれぞれを担当している翻訳ユニットを精度よく推定できる。それでは、ニンジャスレイヤーの独特の文体を離れた、翻訳チームオリジナル作品においても二つの翻訳ユニットのどちらが著者であるか推定できるであろうか?
これを検証するため、翻訳チームがTwitterで気まぐれに連載した作品の中から、検証に耐えうるある程度の長さを持つ作品として「スチームパワード」「ペイルホース死す!」「タイムシフターケイン」「忍者スレイヤー(エイプリルフール版を除く)」を選出し、図2の第二部16エピソードと合わせてクラスタリングした。
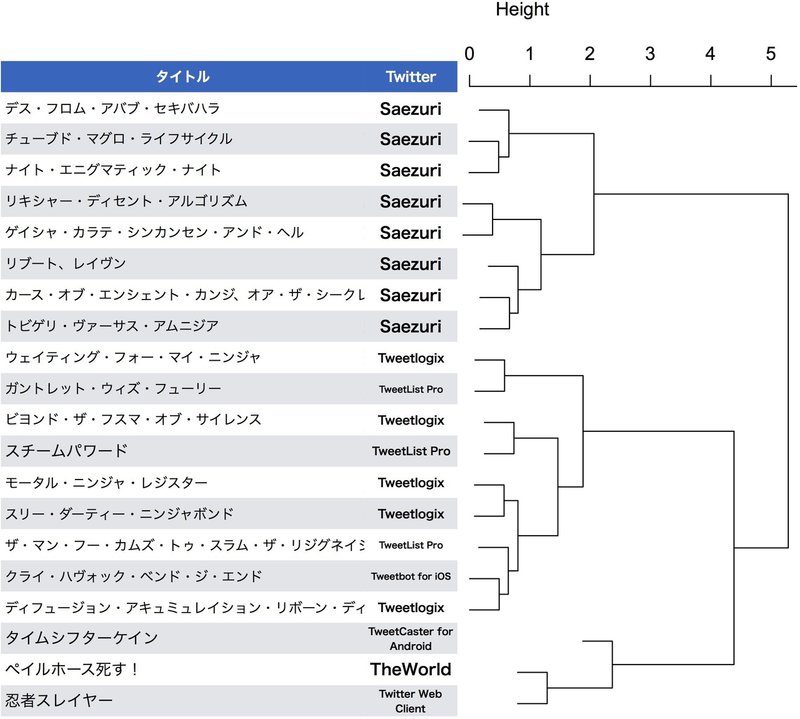
図5. 第二部、翻訳チームオリジナル作品のクラスタリング
図2の16エピソードに翻訳チームオリジナル/二次創作作品を加えたクラスタリング。連載時のTwitterクライアントを付記した。
結果を図5に示した。「スチームパワード」以外は文体が異なるためかかなり離れてはいるが、ボンド担当ユニットに比較的近いことが示唆され、連載時のTwitterクライアントとも整合性がある。
考察と今後の展望
本論文では、圧縮プログラムとクラスタリングを用いて、単純ではあるが主観を持ち込むことなく文体の類似をグループとして可視化できる手法を開発し、かつその手法が正体不明のニンジャスレイヤー翻訳チームに存在するボンド担当ユニット/モーゼズ担当ユニットを区別できることを示した。一方で、図5の結果に見られるように、意図的な文体の違いをも看破する段階までには、まだまだ課題が残ると言えるであろう。圧縮アルゴリズムの変更、圧縮改善係数の算出方法やクラスタリング方法の変更等により手法を改善できれば、より短編やブログの記事などにも応用が可能かもしれない。形態素解析、頻度分析などを通じた研究も待たれるところであり、本論文がそのきっかけになれば幸いである。
参考文献
1)マディソンおばあちゃんの質問回答より. https://twitter.com/dhtls/status/201197673880096768
2)http://www15.atpages.jp/vespiking/njslyr/teams.html
3)安形, 輝:”圧縮プログラムを応用した著者推定”. Library and information science No.54 (2005. ) ,p.1- 18
4)ねとらぼ:”「ニンジャスレイヤー」原作者ブラッドレー・ボンド&フィリップ・N・モーゼズにインタビュー”. http://nlab.itmedia.co.jp/nl/articles/1408/02/news003.html
5)ニンジャスレイヤー翻訳チームからのお知らせまとめ. http://togetter.com/li/259166
6) https://twitter.com/NJSLYR/status/198439263015153664
7) https://twitter.com/NJSLYR/status/586436450897367040
8) https://twitter.com/NJSLYR/status/552116983446003714
9)ブラッドレー・ボンド, フィリップ・N・モーゼズ(訳:本兌有, 杉ライカ): “ニンジャスレイヤー ネオサイタマ炎上#1”. エンターブレイン. 2012
10) http://njrecalls.hatenablog.com/entry/2016/06/30/211308
この記事が気に入ったらサポートをしてみませんか?