
超簡単!---ChatGPTを活用したWebスクレイピング術

Webスクレイピングは、
Webサイトから自動的にデータを収集する技術です。
Webスクレイピングをするには、
Webサイトのソースコードを解析する必要があり、
Pythonだけでなく、
HTMLやJavaScriptの知識も必要で、
なかなか大変な時代もありました。
しかし、今やChatGPTの登場により、
このプロセスが格段に簡単になりました。
この記事では、ChatGPTを活用して
超簡単にWebスクレイピングを行う方法を紹介します。
◾️Webスクレイピングの基本的な流れ
まずは、Webスクレイピングの基本的な流れを確認しましょう。
ChatGPTを使うと、以下の2と3のプロセスが簡単になります。
1.目的のサイトの選定:
まずはスクレイピングしたいWebサイトのURLを確認します。
2.Webサイトの構造分析:
開発者ツールを使ってHTMLの構造を調査し、必要なデータがどのHTML要素に含まれているかを特定します。
3.Pythonコードの記述:
Webページを取得し、取得したHTMLデータを解析して、必要なデータを抽出するPythonコードを記述します。
4.コードの実行とデータの抽出:
書かれたコードを実行して、必要なデータを抽出し、それを保存または利用します。
◾️ChatGPTを使用したスクレイピングの流れ
ここからは、実際のWebページを例に
スクレイピングの一連の流れを紹介していきます。
例として、
IR BANK(https://irbank.net/)という株価情報サイトから、
JR西日本(証券コード9021)の
2022年3月31日と2023年3月31日の
PBR(株価純資産倍率)を取得してみましょう。
以下の赤囲みの部分を取得します。
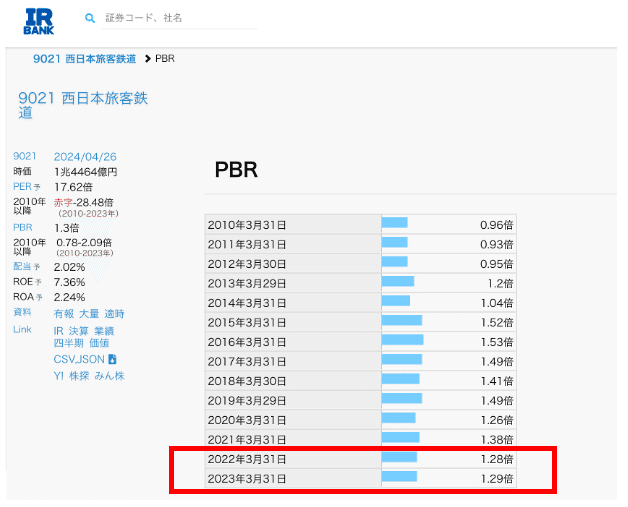
1.目的サイトの選定
以下が目的サイトになります
このURLは、https://irbank.net/9021/pbrとなっていて、
よく見ると、9021の部分は証券コードが入っていることが分かります。
2.ChatGPTに問いかける
ChatGPTに以下のプロンプトを入力します。
URLとページ構造(ソースコード)を渡します。
ソースコードはデベロッパーツールから取得します。
その方法については、後から説明します。(一旦、先に進みます)
以下のURLをスクレイピングして、2022年3月31日と2023年3月31日のPBRを取得するためのPythonコードを教えてください。
"""URL""" ←URLを入力します
https://irbank.net/9021/pb
"""URLのページ構造""" ←この部分は後で説明します
<body>
<header>
<div class="ch">
<div id="cd-logo">
<a title="IR BANK - 企業分析・銘柄発掘" href="/"> <img src="https://f.irbank.net/logo/irbank.png" width="48" height="48" alt="IR BANK"> </a> </div> <form method="GET" action="/search"> <input type="text" value="" name="query" placeholder="証券コード、社名" required> <button type="submit"> <i class="fas fa-search"></i> </button> </form> <nav class="cmn">
(略)
3.コードの生成
ChatGPTがPythonのスクレイピングコードを提供します。
ChatGPTの回答:
指定されたウェブページから特定の日付のPBRを抽出するためのPythonスクレイピングコードは以下のようになります。
このコードでは、requestsとbeautifulsoup4ライブラリを使用してHTMLページを取得し、解析します。
指定した日付のPBR値を取得するために、タグとクラスを正確に指定する必要があります。
import requests
from bs4 import BeautifulSoup
# 対象のURL
url = 'https://irbank.net/9021/pbr'
# requestsを使用してウェブページを取得
response = requests.get(url)
response.raise_for_status() # ステータスコードが200以外の場合はエラーを発生させる
# BeautifulSoupオブジェクトを作成し、HTMLを解析
soup = BeautifulSoup(response.text, 'html.parser')
# PBRのデータが含まれる部分を特定
pbr_data = soup.find_all('dl', class_='gdl inline mgr')
# 指定された日付のPBR値を検索し、出力
dates = ['2022年3月31日', '2023年3月31日']
pbr_values = {}
for pbr in pbr_data:
dt_list = pbr.find_all('dt')
dd_list = pbr.find_all('dd')
for dt, dd in zip(dt_list, dd_list):
if dt.text.strip() in dates:
pbr_values[dt.text.strip()] = dd.find('span', class_='text').text.strip()
print(pbr_values)
このコードは、指定されたURLからPBRのデータを抽出し、2022年3月31日と2023年3月31日のPBR値をディクショナリ形式で出力します。このスクリプトを実行する前に、requestsとbeautifulsoup4ライブラリがインストールされていることを確認してください。
4.コードの実行とデータの抽出
提供されたコードを実行し、必要なデータを抽出します。
GoogleColaboratoryに上記のコードをコピペすると簡単に実行できます。
先ほどのコードの出力結果

◾️URLのページ構造(ソースコード)の取得
URLのページ構造を
ChatGPTのプロンプトに貼り付ける必要があるのですが、
その方法について説明します。
GoogleChromeを使っている前提です。
まず、右上の3点ボタンをクリックし、
その他ツール→デベロッパーツールを開きます。

画面下にデベロッパーツールが現れます。
次に、ソースを選択します。
→ソースコードが表示されます。
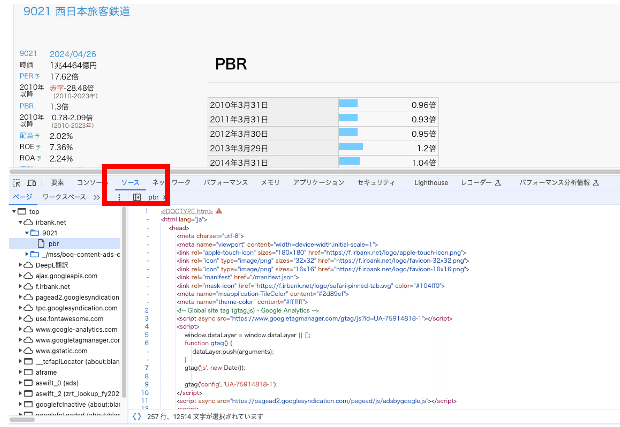
このソースコードをコピーして、ChatGPTのプロンプトに貼り付けます。
<body>と書かれている箇所以下をコピーしましょう。
ただし、ソースコードの量が多いと、
ChatGPTが受け付けてくれません。(エラーが出ます)
この場合は、取得したい部分が書かれているソースコードを見つけ出して、
貼り付けてください。
さいごに
ChatGPTを使用することで、
HTMLの知識がなくても、
簡単にWebスクレイピングを行うことができます。
この力を利用して、
データ収集の効率を上げる方法をぜひ試してみてください。
この記事が気に入ったらサポートをしてみませんか?