
Pythonデータ分析(重回帰分析)

現在、SIGNATEの学習サイトを利用してPythonのデータ分析手法を学んでいます。
体調が良い日にPCへ向かい、悪い日は動画やサイトを見ながら勉強しておりカメの歩みのごとき進捗です。
それでも、最初はサッパリ分からなくてスルーしていたものが後日「こういうことか!」と理解できた時の喜びはひとしおです。やっぱり学びは良いです。
1.データの読み込み
SIGNATEの練習問題:自動車の走行距離予測をやってみました。
カラム名から何を表している値なのか分からず躓いたので、Bardに手伝ってもらいながら調べました。
・id → インデックス
・mpg → ガソリン1ガロンあたりの走行距離(目的変数)
・cylinders → シリンダーの数。多いほど排気量が大きくなり、 出力も高くなる
・displacement → 排気量
・horsepower → 馬力
・weight → 重量
・acceleration → 加速度
・model year → 年式
・origin → 起源。1アメリカ,2ヨーロッパ,3日本
・car name → 車名
データ型を見るとhorsepowerが何故かocject型になっていたので数値型に変換しようとするとエラーになりました。’?’が入力されている行があるため、まずはこれを欠損値に変換してデータ型を変換する必要があります。
(エラーからこのことに気づくまで、また時間がかかりました…)
また、cylindersとoriginは分類や種類を区別するためのデータ(質的データ)になると考えobject型に変換してみました。
#horsepower入力値に’?’あり⇒欠損値に変換
tr_df['horsepower'] = tr_df['horsepower'].replace('?', np.nan)
tr_df["horsepower"] = tr_df["horsepower"].astype(float)
tr_df['horsepower'] = tr_df['horsepower'].fillna(tr_df['horsepower'].mean()) #欠損値を平均値で補完
#cylinders,originをobjectに変換
tr_df["origin"] = tr_df["origin"].astype(object)
tr_df['cylinders'] = tr_df['cylinders'].astype(object)2.可視化
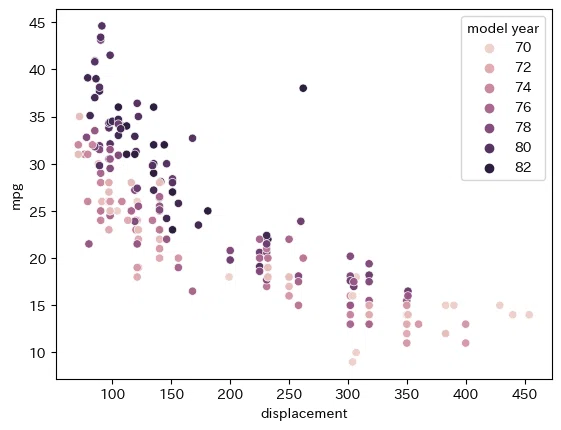
可視化してみると、displacement、horsepower、weightに負の相関がありました。全体的にmodel yearが新しいほど燃費が良いので、年々改善されているようです。


3.対数化とダミー変数化
散布図がやや曲線を描いているので対数化してみました。
対数化とは(Bard回答):
データの値を小さくすることです。例えば、データの値が 100 なら、10の2乗となり、対数化すると 2 になります。対数化を行うことで、データの分布を正規分布に近づけることができます。正規分布は、統計学において非常に重要な分布です。対数化を行うことで、データの分析をより簡単に行うことができます。
#displacement,weight,horsepower対数化
tr_df['displacement_log'] = np.log(tr_df['displacement'])
tr_df['weight_log'] = np.log(tr_df['weight'])
tr_df['horsepower_log'] = np.log(tr_df['horsepower'])cylinders、originをダミー変数化してモデルに学習させます。
ダミー変数化とは(Bard回答):
質的データを量的データに変換し、統計解析を行うことができます。例えば、性別をダミー変数化すると、男性は1、女性は0に変換されます。これにより、性別がデータに与える影響について統計解析を行うことができます。
#モデルの学習
x = tr_df.drop(columns=['mpg','displacement','weight','horsepower','car name'])
#cylinders、originをダミー変数化
x = pd.get_dummies(x)
y = tr_df['mpg']
model = LR()
model.fit(x,y)
# モデルから予測結果を求める
y_pred = model.predict(x)
tr_mse = MSE(y_pred,y)
rmse_train = np.sqrt(tr_mse)
print(rmse_train)学習データのRMSEは2.8470587885880687でした。
RMSEとは:モデルの評価指数で、予測値と実測値の差の絶対値平均から平方根を取ったもので、1点でも大きく予想を外すと値が大きくなる。大きな予測誤差を出さないモデルの評価に適している。0に近いほど良い。
4.提出
学習したモデルを使ってテストデータから予測したmpgデータを提出しました。結果はRMSE:3.0952868でした。
最初何も調整せずに作成したモデルは4.5程だったので、自分の拙い技術でも少し精度を上げられました。
成績トップの方は 0.7135960 なのでまだまだですが、練習とはいえ初コンペが体験できたので良かったです。
今回は特徴量の対数化とダミー変数化をやってみました。
パラメータ調整をすればもっと精度が上がるかもしれませんが、重回帰分析以外の手法も知りたいので先にそちらを勉強してみようと思います。
ただでさえコロナ後遺症で活動できるリソースが減って疲労しやすいので、わからないところを調べる労力をAI(Bard)で軽減しました。
Python初心者としてはエラーが出た時に解決方法を教えてくれるのが非常に助かりました。サイトや動画を見ても初歩的なエラーの解決方法はなかなかわからないもので。。。
アメリカではプロンプトエンジニアなる職もあるそうです。AIを効率よく使用できるスキル取得が、負荷の少ない職を目指す上でも光明が見える気がします。頑張って使いこなすべくこちらの勉強も続けたいと思います。
この記事が気に入ったらサポートをしてみませんか?