GAN, 転移学習、BERT、に共通するのは..

GAN= Generative Adversarial Network (敵対的生成ネットワーク)といわれるタイプのニューラルネットワーク活用アルゴリズムは、教師無し学習と呼ばれることもあります。しかしこれは、内部的に、2者の対戦相手のようなものを生成し、互いに騙し合うかのように少しずつパラメータを変えて競い合うようにして、何かを生成したり真似たりする精度を上げるというアイディアです。ですので、ある範囲でランダムに、というながら、正解データを大量に自動生成し、逐次改良する仕組み、ということもできます。
ヒトの幼児は、たった1つの新種の何かをみただけで、まだ見ぬ同種類のものが同じカテゴリのもの、と見分けることができたりします。深層学習の父の1人ヒントン教授もこの驚異的能力を前に、いまのAIがまだまだだ、と謙虚に語っていました(TV番組では全然違う意味の字幕が表示されてましたが)。確かに、通常の深層学習では、計算量の膨大さは毎秒100兆回の演算など力づくでなんとかするとしても、その速度でトレーニングに何日もかかるような膨大な量の正解ラベルをデータに人手で付与するのが決定的なボトルネックとして立ちはだかっていました。しかも、正解かどうかの判定基準の多くは暗黙知なので、その基準、仕様が書き尽くせません。犬の写真を見ながら「自分には猫に見えたのだ!」と言われて質の低い正解データセットを納品されても、システマティックにrejectできない。すなわち、モラルハザード問題が潜在的に生じます。
メタデータ社が主催し、電通さんや、三菱グループの大手企業からAI開発経験者らを招いて開催したパネル討論で上記を論じました。日経BPさんによる取材記事を御覧ください。ではどうしたらいいか? 論理的には2つに1つです。
(1)少量の正解データでトレーニングできるようにする
(2)大量の正解データを自動生成する
もちろん、これらの組み合わせもあるでしょう。
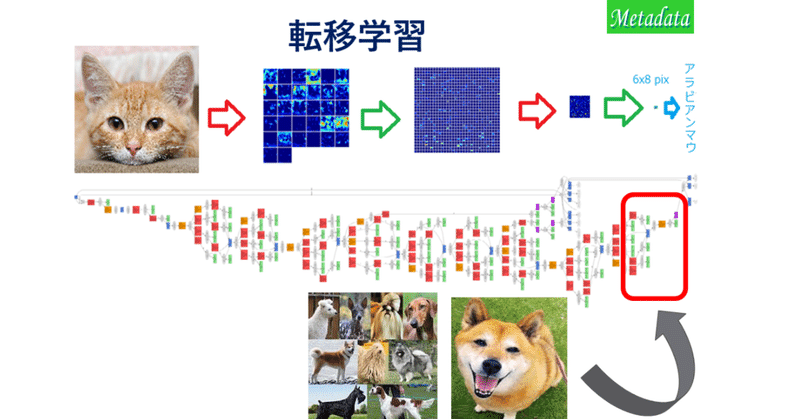
(1)のアイディアの代表で実用になっているのが転移学習。既存の大規模トレーニング済のモデルを流用、転用し、似て非なる課題、少量のデータセットで、出力に近い最後段付近の一部のネットワーク層の重みだけを修正する。これにより、同じ少量のデータだけで学習した場合よりも+10ポイントほど精度が上がることが経験的に知られていきました。私のメタデータ株式会社では、2016年に様々なタスクでこれを体感し、電子部品・基盤の欠陥検出に、イースト菌の電子顕微鏡写真という一見何の関係もない、しかし、見た目が似ていた大規模学習済モデルを流用して、チャレンジに打ち克ったことがありました。
(2)の代表として、GANとBERT (2018年10月に登場した今でも最強クラスの文章読解の仕組み)をあげます。GANは上述の通りですが、BERTは、大学入試の各国語(英語、中国語、日本語)の穴埋め問題や、「こそあど」などの指示語が指す対象、そして、文間のつながりを学習します。その際に」何億文という膨大な正解データが要るので、手動で正解データセットを作るのは事実上不可能。そこで、主語、目的語、述語などが完備したフルセットの文章(構文解析などで解析した結果)を用意します。その後、なるべく(あくまで「なるべく」)人間がやりそうな省略を様々用意し(ここが工夫のしどころ。言語学者、伝統的手法に知悉した計算言語学者の面目躍如です)、元のcompleteな文との対応関係が数10億通り、【自動的に用意】されるわけです。すなわち、正解データセットの自動生成。
このように(1)か(2)かで、ボトルネック打破の本質的手法を分類していくことで、今後ランダムならざる、有益な解決法の探索ができる感じがします。帰納的な学習の方法を探索するのにも、ある程度演繹手法、MECEなロジックが役立つ事実には、少しほっとさせられるものがあります。
この記事が気に入ったらサポートをしてみませんか?