
scikit-learnで無料で使えるデータセットである「ボストンの住宅価格データ」を元に解析をしてみよう。

データ解析やってみたい、と思っても、「そもそもデータが手元にないぞ・・・」という問題が起きることってありますよね。これ、データ解析をするためには死活問題だったりします。そこでscikit-learnという便利なPythonのオープンソース機械学習ライブラリを使うと、いろんな分析をすることができます。実はscikit-learnの中にいい感じのデータがすでに入っているんですね。
では、実際にPythonを叩きながら、そのデータを見てみましょう。
import pandas as pd
from sklearn.datasets import load_boston
bsdata = load_boston()
df = pd.DataFrame(bsdata.data, columns=bsdata.feature_names)
#住宅価格のデータを追加する
df['Price'] = bsdata.target
#データを見てみる
dfこうやると、こんな感じのデータをみることができます。・
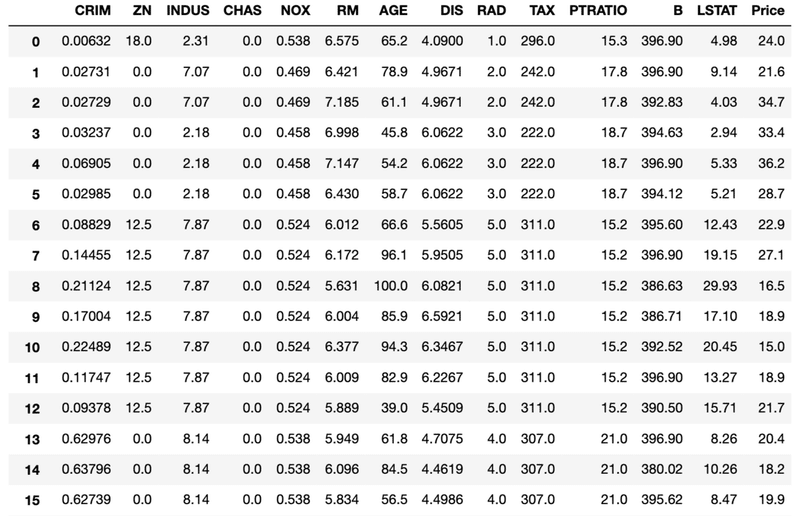
それぞれの列にCRIM、ZN、INDUS、などの英語が書いてあるのがわかります。これがどういう値なのか、気になりますよね。その際は以下のように書いてあげましょう。
print(bsdata.DESCR)そうすると、以下のように出力されます。
.. _boston_dataset:
Boston house prices dataset
---------------------------
**Data Set Characteristics:**
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
:Creator: Harrison, D. and Rubinfeld, D.L.
This is a copy of UCI ML housing dataset.
https://archive.ics.uci.edu/ml/machine-learning-databases/housing/
This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.
The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic
prices and the demand for clean air', J. Environ. Economics & Management,
vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics
...', Wiley, 1980. N.B. Various transformations are used in the table on
pages 244-261 of the latter.
The Boston house-price data has been used in many machine learning papers that address regression
problems.
.. topic:: References
- Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261.
- Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.こんな風にデータの中身の説明をみることができます。英語のままだと直感的ではないかもしれないので、一度翻訳をしてみましょう。以下がそれぞれの言葉の意味合いになります。
CRIM 人口 1 人当たりの犯罪の発生数
ZN 25,000 平方フィート以上の住居区画の占める割合
INDUS 小売業以外の商業が占める面積の割合
CHAS チャールズ川によるダミー変数 (1: 川の周辺, 0: それ以外)
NOX 窒素酸化物の濃度(自動車やボイラー、工場、家庭暖房などで発生する)
RM 住居の平均部屋数
AGE 1940 年より前に建てられた物件の割合
DIS 5つのボストン市の雇用施設からの距離
RAD 環状高速道路へのアクセスしやすさ
TAX $10,000 ドルあたりの不動産税率の総計
PTRATIO 町毎の児童と教師の比率
B 町毎の黒人 (Bk) の比率を次の式で表したもの。 1000(Bk – 0.63)^2
LSTAT 給与の低い職業に従事する人口の割合 (%)
MEDV 所有者が占有している家屋の$ 1000単位の中央値
では、実際に書いてみましょう。以下のように書くと、LSTATとPriceの関係を図示することができます。
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.jointplot('LSTAT', 'Price', data=df)sns.jointplotは、seaborn.jointplotといって、
LSTATをX軸におき、PriceをY軸においてヒストグラムつきの散布図を書くことができます。
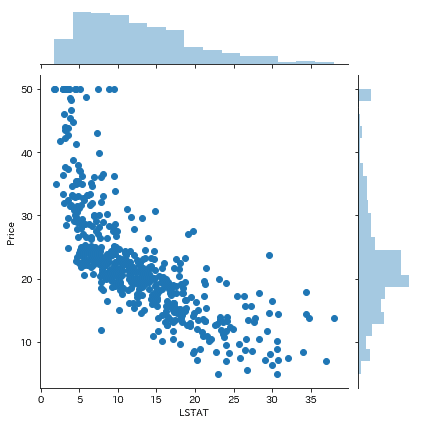
LSTATは給与の低い職業に従事する人口の割合 (%)ですので、給与の低い職業に従事する人口の割合が増えれば増えるほど、住宅価格は下がりそうだなあ、という目星をつけることができます。
では、犯罪率との関係はどうでしょうか。
sns.jointplot('CRIM', 'Price', data=df)これを書くと以下のようになります。
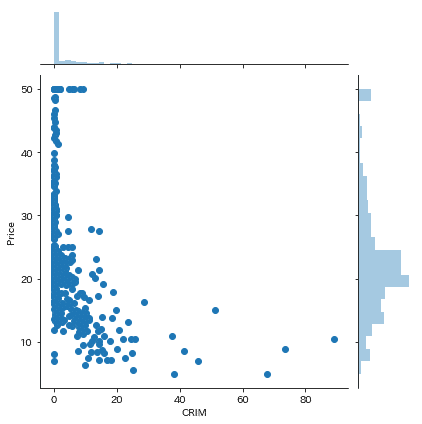
sns.jointplot('CRIM', 'Price', df, kind="reg")ただ、上のだとなんとなく負の相関がありそうなのですが、ちょっと自信がない感じがしますよね。これ、線を書くことでめちゃくちゃわかりやすくなります。そんな時、kind="reg"が威力を発揮します。これを書くだけで線形回帰線が追加されます。やってみましょう。
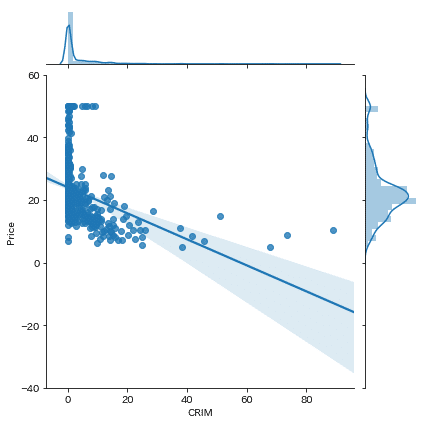
犯罪率が高まれば、住宅価格は下がっている傾向が見えてきました。これは納得感がありますよね。
こんな風にscikit-learnのデータを使って、seaborn.jointplotメソッドで図示してあげると、色々なデータ同士の関係性を表や図を使って把握することが簡単にできるようになります。便利・・・!
さらに、以下のように書いてみましょう。
# 目的変数と説明変数を一つのデータフレームにまとめる
df = pd.DataFrame(bsdata.data, columns=bsdata.feature_names)
df['PRICE'] = bsdata.target
# 相関を計算
corr = df.corr()
# データフレームに色をつける
corr.style.format("{:.2}").background_gradient(cmap=plt.get_cmap('coolwarm'), axis=1)そうすると、以下のような相関係数行列を記述することができます。カラフルで、めっちゃわかりやすい。
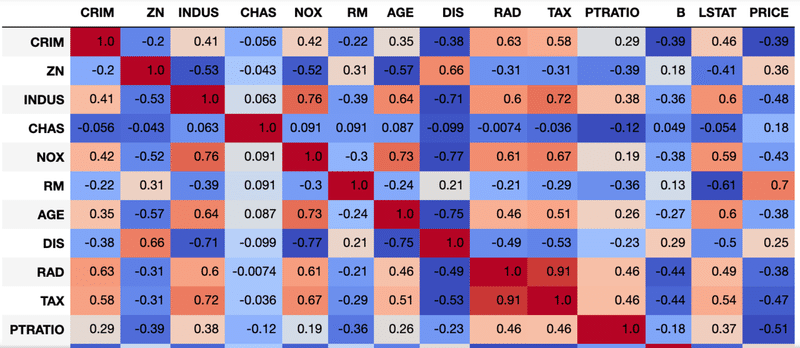
例えば、PRICEの列をみると、RMのところが0.7と書いてあり、RMとPRICEについては相関がありそうです。RMとは、住居の平均部屋数なので、これも部屋が多ければ家賃が高いのは納得感がありますね。
サポートされた費用は、また別のカンファレンス参加費などに当てようと思います。