スタートアップのためのディープラーニング

一般社団法人ウェブ解析士協会の江尻会長に連れていってもらい、ラスベガスのMARKETING ANALYTICS SUMMITに参加しています。これは西海岸でも非常に大きなマーケティングのカンファレンスになります。今回の記事では、MARKETING ANALYTICS SUMMITの中でのDecision Engines IncのKunling Gengさんの講演を書き起こしていきます。書き起こしだけではなく、日本語翻訳をするのにこの記事ではチャレンジしていきます。
--------以下、書き起こし--------
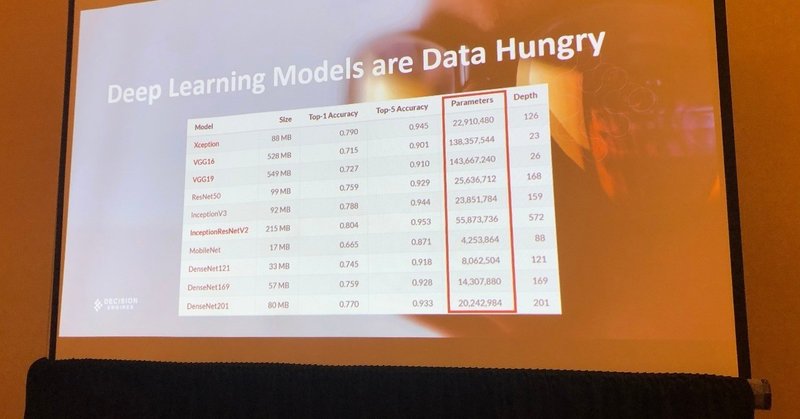
ディープラーニングモデルは、データ飢餓状態にあります。
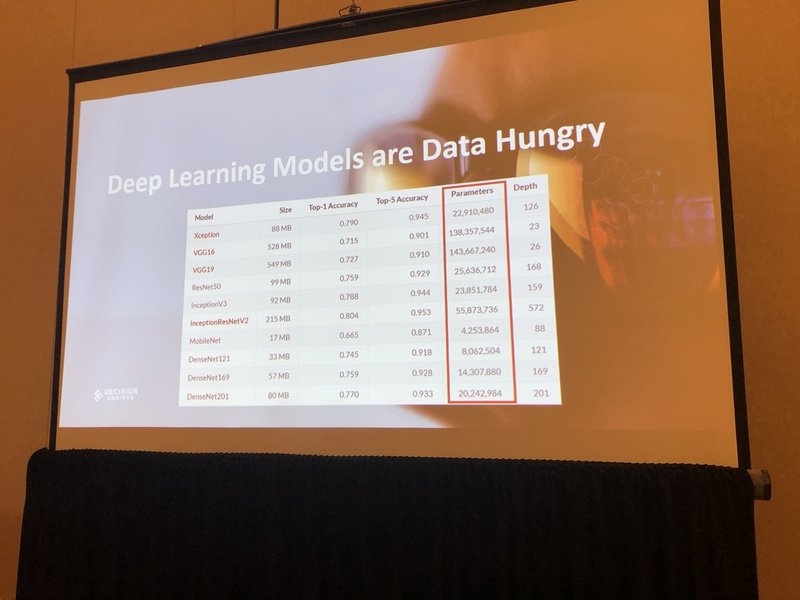
ここに挙げたのは比較的有名なディープラーニングのモデルですが、これらはデータを大量に求めています。
・MVPを数ヶ月で作りたい
・データ数の量は十分ではない
そんなスタートアップのためのやり方を紹介します。
まずはData Augmentationという方法があります。これはデータ拡張という意味です。スクラッチで集めるよりも、早くデータを作ることができます。次のやり方が Active learning。重要なデータのみに人間がラベルをつけて学習データに取り込んでいきます。
A complex end-to-end modelsはトン以上のパラメーターがあり、データハングリーです。そのため、Computer Visionを使い、natural language processingを使った上で、Rule Based processing をやり、heuristic algorithmで生成していきます。
伝統的なマシンラーニングは、ディープラーニングと比較すると、日が経てば経つほど正確ではなくなっていきます。
ここからは文字認識のテクノロジーを見ていきます。実は実際の世界はとてもぐちゃぐちゃです。PCのフォントと違い、ゴミが入っていたりします。この時、まずは、
1)データとラベルを整える
2)綺麗な状態のものと、実際に起きた文字を比較します。
3)モデルの進化とプロモーション
という順番で実装していきます。では、リーンAIの戦略とは、すでにあるディープラーニングのライブラリを活用していく、ということになると思います。ありがとうございました。
サポートされた費用は、また別のカンファレンス参加費などに当てようと思います。