
Stable Baselines入門 / 学習の監視

1. 学習の監視
学習の監視には、ログで確認(verbose=1)する他に、「Tensorboard」による学習の監視と、「コールバック」による学習の監視があります。
2. Tensorboardによる学習の監視
「Tensorboard」による学習の監視を行うには、エージェントの生成時の引数に、「tensorboard_log」を指定してください。指定したフォルダにTensorboardのログが出力されます。
import gym
import os
from stable_baselines.common.policies import MlpPolicy
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines import PPO2
# ログフォルダの生成
log_dir = './logs/'
os.makedirs(log_dir, exist_ok=True)
# 環境の生成
env = gym.make('CartPole-v1')
env = DummyVecEnv([lambda: env])
# エージェントの生成
agent = PPO2(MlpPolicy, env, verbose=1, tensorboard_log=log_dir)
# エージェントの学習
agent.learn(total_timesteps=10000)
# テスト
state = env.reset()
for i in range(200):
env.render()
action, _ = agent.predict(state)
state, reward, done, info = env.step(action)Tensorboardのログを見るには、次のコマンドを入力します。
$ tensorboard --logdir=./logs/Webブラウザで「http://localhost:6006」を開くことにより、リアルタイムに平均エピソード報酬を観察することができます。
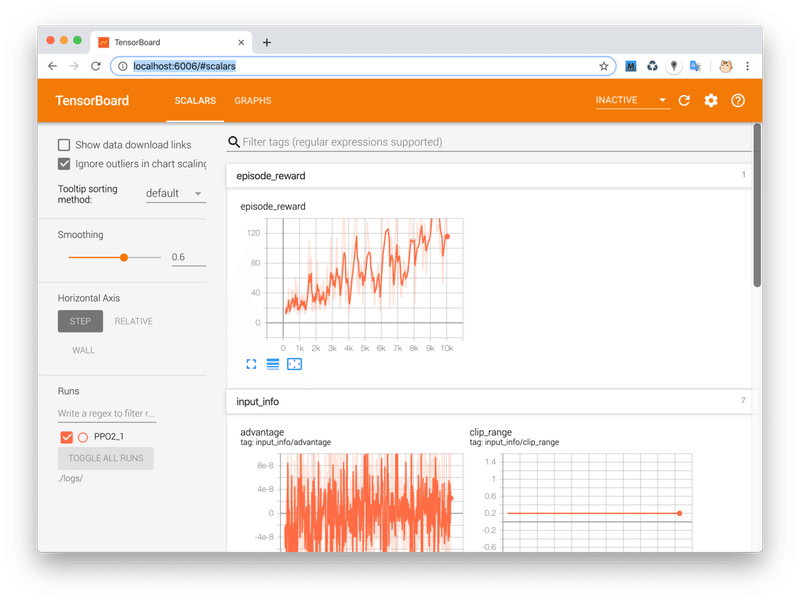
3. コールバックによる学習の監視
エージェント内で呼び出されるカスタムコールバック関数を定義することで、学習を監視することもできます。これによって、Tensorboardのリアルタイムなカスタムグラフを作成したり、ベストエージェントを保存したりすることができます。
以下のコードでは、コールバックを使って、100ステップ毎に過去100件の平均報酬を計算し、ベスト平均報酬を越えていたらエージェントを保存しています。
import gym
import os
import numpy as np
import datetime
import pytz
from stable_baselines.bench import Monitor
from stable_baselines.common.policies import MlpPolicy
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines import PPO2
from stable_baselines.results_plotter import load_results, ts2xy
# グローバル変数
best_mean_reward = -np.inf # ベスト平均報酬
nupdates = 0 # 更新数
# 更新毎に呼ばれるコールバック
def callback(_locals, _globals):
global nupdates
global best_mean_reward
# print('callback:', nupdates)
# 10更新毎
if (nupdates + 1) % 100 == 0:
# 平均エピソード長、平均報酬の取得
x, y = ts2xy(load_results(log_dir), 'timesteps')
if len(x) > 0:
# 最近10件の平均報酬
mean_reward = np.mean(y[-100:])
# 平均報酬がベスト報酬以上の時はエージェントを保存
update_model = mean_reward > best_mean_reward
if update_model:
best_mean_reward = mean_reward
_locals['self'].save(log_dir + 'best_model.pkl')
# ログ
print("time: {}, nupdates: {}, mean: {:.2f}, best_mean: {:.2f}, model_update: {}".format(
datetime.datetime.now(pytz.timezone('Asia/Tokyo')),
nupdates, mean_reward, best_mean_reward, update_model))
nupdates += 1
return True
# ログフォルダの生成
log_dir = './logs/'
os.makedirs(log_dir, exist_ok=True)
# 環境の生成
env = gym.make('LunarLanderContinuous-v2')
env = Monitor(env, log_dir, allow_early_resets=True)
env = DummyVecEnv([lambda: env])
# エージェントの生成
agent = PPO2(MlpPolicy, env, verbose=0)
# エージェントの訓練
agent.learn(total_timesteps=100000, callback=callback)◎Monitor
Monitorを追加することで、logフォルダにmonitor.csvが出力します。
ep_reward_mean(平均報酬)、ep_len_mean(平均エピソード長)、timestamp(経過時間)の3つのカラムを持つCSVになります。
以下のコードでこのCSVを読み込んで、xに「平均エピソード長」の配列、yに「平均報酬」の配列を読み込むことができます。
x, y = ts2xy(load_results(log_dir), 'timesteps')今回は、この情報を元に、エージェントを保存するかどうかを決めています。
◎コールバックの定義
コールバックはローカル変数の辞書「_locals」とグローバル変数の辞書「_globals」を引数として持ちます。
今回の場合の_localsと_globalsは次の通りです。
・_locals
['loss_name', 'loss_val', 'explained_var', 'fps', 't_now', 'loss_vals', 'slices', 'end', 'timestep', 'start', 'epoch_num', 'inds', 'update_fac', 'mb_loss_vals', 'true_reward', 'ep_infos', 'states', 'neglogpacs', 'values', 'actions', 'masks', 'returns', 'obs', 'cliprange_vf_now', 'cliprange_now', 'lr_now', 'frac', 't_start', 'batch_size', 'update', 'n_updates', 't_first_start', 'ep_info_buf', 'runner', 'writer', 'new_tb_log', 'cliprange_vf', 'reset_num_timesteps', 'tb_log_name', 'log_interval', 'seed', 'callback', 'total_timesteps', 'self', 'mbinds']・_globals
['__name__', '__doc__', '__package__', '__loader__', '__spec__', '__file__', '__cached__', '__builtins__', 'time', 'sys', 'multiprocessing', 'deque', 'gym', 'np', 'tf', 'logger', 'explained_variance', 'ActorCriticRLModel', 'tf_util', 'SetVerbosity', 'TensorboardWriter', 'AbstractEnvRunner', 'ActorCriticPolicy', 'RecurrentActorCriticPolicy', 'total_episode_reward_logger', 'PPO2', 'Runner', 'get_schedule_fn', 'swap_and_flatten', 'constfn', 'safe_mean']戻り値がFalseの時は、学習を即時に停止します。
◎コールバックの指定方法
コールバックを指定するには、エージェントのlearn()のcallbackに指定します。
実行すると、以下のようなログが出力されます。
time: 2019-08-15 14:20:13.275050+09:00, nupdates: 99, mean: -167.00, best_mean: -167.00, model_update: True
time: 2019-08-15 14:20:23.901742+09:00, nupdates: 199, mean: -147.75, best_mean: -147.75, model_update: True
time: 2019-08-15 14:20:38.196934+09:00, nupdates: 299, mean: -181.04, best_mean: -147.75, model_update: False
time: 2019-08-15 14:20:55.990822+09:00, nupdates: 399, mean: -201.40, best_mean: -147.75, model_update: False
time: 2019-08-15 14:21:19.808027+09:00, nupdates: 499, mean: -185.94, best_mean: -147.75, model_update: False
time: 2019-08-15 14:21:44.683322+09:00, nupdates: 599, mean: -179.53, best_mean: -147.75, model_update: False
time: 2019-08-15 14:22:09.124388+09:00, nupdates: 699, mean: -159.41, best_mean: -147.75, model_update: False4. monitor.csvをグラフで表示
「monitor.csv」をグラフで表示するコードは次の通りです。
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# monitor.csvの読み込み
df = pd.read_csv('monitor.csv', names=['r', 'l','t'])
df = df.drop(range(2))
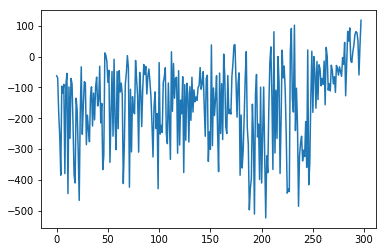
# 平均報酬のグラフの表示
x = range(len(df['r']))
y = df['r'].astype(float)
plt.plot(x, y)
plt.show()
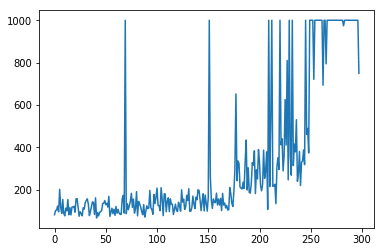
# エピソード長のグラフの表示
x = range(len(df['l']))
y = df['l'].astype(float)
plt.plot(x, y)
plt.show()
この記事が気に入ったらサポートをしてみませんか?