
PyTorch MobileのiOS版 HelloWorldを試す

1. PyTorch Mobile
「PyTorch 1.3」では、実験的リリースですが、iOSとAndroidをサポートするようになりました。特徴は次の通りです。
・MLをモバイルアプリケーションに組み込むために必要な一般的な前処理および統合タスクをカバーするAPIを提供。
・QNNPACK quantized kernel librariesとARM CPUのサポート。
・モバイルアプリケーションに必要なオペレータに応じて、ビルドレベルの最適化と選択的なコンパイルを行う。
・モバイルのCPUとGPUのパフォーマンスとサポート範囲の改善。
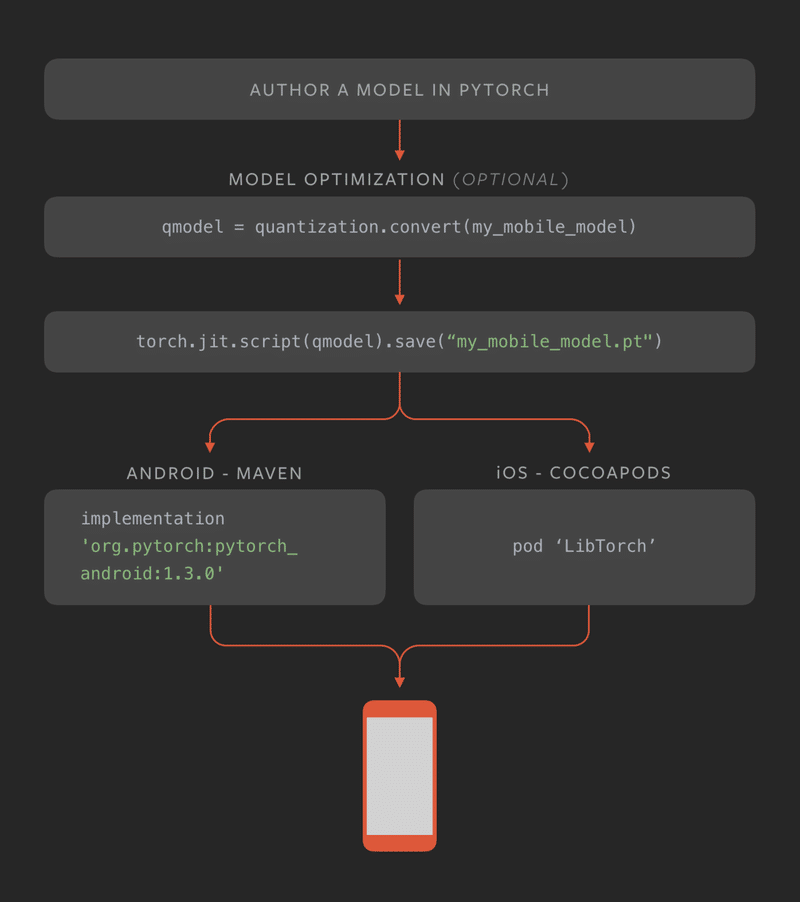
2. HelloWorld
iOSで「PyTorch C++ライブラリ」を使用するシンプルな画像分類アプリケーション「HelloWorld」が提供されています。コードはSwiftで記述されており、Objective-Cをブリッジとして使用しています。
今回はこれを実行してみます。
3. モデルの準備
事前訓練された画像分類モデルである「Resnet18」を使用します。これは、「TorchVision」にパッケージ化されています。
(1)Anacondaなどの仮想環境で次のコマンドを実行し、「TorchVision」をインストール。
$ pip install torchvision(2)HelloWorldをダウンロードしてHelloWorldフォルダに移動し、「trace_model.py」を実行。
モバイルで実行できるTorchScriptモデル「model.pt」が生成されます。
$ python trace_model.py(3)Xcodeプロジェクト(HelloWorld/HelloWorld)の「HelloWorld/model」にコピー。
4. PyTorch C++ライブラリのインストール
「PyTorch C++ライブラリ」(LibTorch)は、CocoaPodsでインストールできます。Xcodeプロジェクト(HelloWorld/HelloWorld)のルートに移動し、以下のコマンドを入力してください。
$ pod install5. HelloWorldの実行
「HelloWorld.xcworkspace」を開き、アプリを実行してください。画面に予測結果とともにオオカミの写真が表示されます。

6. コードの説明
コードをステップごとに説明します。
◎画像の読み込み
はじめに、画像の読み込みを行います。
let image = UIImage(named: "image.jpg")!
imageView.image = image
let resizedImage = image.resized(to: CGSize(width: 224, height: 224))
guard var pixelBuffer = resizedImage.normalized() else {
return
}バンドルから画像を読み込み、224x224にリサイズ後、normalized()カテゴリメソッドを呼び出して、ピクセルバッファを正規化しています。
◎正規化
normalized()カテゴリメソッドを詳しく見てみます。
var normalizedBuffer: [Float32] = [Float32](repeating: 0, count: w * h * 3)
// normalize the pixel buffer
// see https://pytorch.org/hub/pytorch_vision_resnet/ for more detail
for i in 0 ..< w * h {
normalizedBuffer[i] = (Float32(rawBytes[i * 4 + 0]) / 255.0 - 0.485) / 0.229 // R
normalizedBuffer[w * h + i] = (Float32(rawBytes[i * 4 + 1]) / 255.0 - 0.456) / 0.224 // G
normalizedBuffer[w * h * 2 + i] = (Float32(rawBytes[i * 4 + 2]) / 255.0 - 0.406) / 0.225 // B
}入力データのシェイプが(3 x H x W)で、3チャンネルRGB画像になります。HとWは224であると予測されます。画像は[0、1]の範囲に正規化するために、mean=[0.485, 0.456, 0.406]、std=[0.229, 0.224, 0.225]を使用しています。
◎学習済みTorchScriptモデルの読み込み
次に、学習済みTorchScriptモデルを読み込みます。
private lazy var module: TorchModule = {
if let filePath = Bundle.main.path(forResource: "model", ofType: "pt"),
let module = TorchModule(fileAtPath: filePath) {
return module
} else {
fatalError("Can't find the model file!")
}
}()「TorchModuleクラス」は「torch::jit::script::Module」のObjective-Cラッパーになります。SwiftはC++と直接通信できないため、Objective-Cラッパーが必要になります。
torch::jit::script::Module module = torch::jit::load(filePath.UTF8String);
◎推論の実行
次に、推論を実行して結果を取得します。
guard let outputs = module.predict(image: UnsafeMutableRawPointer(&pixelBuffer)) else {
return
}predictメソッドはObjective-Cラッパーです。内部では、C++の関数を呼び出しています。
at::Tensor tensor = torch::from_blob(imageBuffer, {1, 3, 224, 224}, at::kFloat);
torch::autograd::AutoGradMode guard(false);
at::AutoNonVariableTypeMode non_var_type_mode(true);
auto outputTensor = _impl.forward({tensor}).toTensor();
float* floatBuffer = outputTensor.data_ptr<float>();C++の関数「torch::from_blob」は、ピクセルバッファから入力テンソルを作成します。テンソルのシェイプは{1,3,224,224}であり、上記で説明したように「NxCxWxH」を表すことに注意してください。
torch::autograd::AutoGradMode guard(false);
at::AutoNonVariableTypeMode non_var_type_mode(true);上記2行は、PyTorchエンジンに推論のみを行うよう指示しています。これは、デフォルトでは、PyTorchにはautogradationと呼ばれる自動微分を行うためです。訓練を行わない時は、自動微分モードを無効にすることができます。
最後に、forward関数を呼び出して出力テンソルを取得し、それをFloat Bufferに変換します。
auto outputTensor = _impl.forward({tensor}).toTensor();
float* floatBuffer = outputTensor.data_ptr<float>();◎結果の収集
出力テンソルは、シェイプ1x1000の1次元float配列です。各値は、画像からラベルが予測される信頼度になります。以下のコードは配列をソートし、上位3件の結果を取得します。
let zippedResults = zip(labels.indices, outputs)
let sortedResults = zippedResults.sorted { $0.1.floatValue > $1.1.floatValue }.prefix(3)7. APIリファレンス
現在iOSでは、Pytorch C++ front-end APIを直接使用します。将来的には、Swift/Objective-C APIラッパーのPyTorchへの提供も予定されてます。C++のAPIの詳細はAPIリファレンスを参照してください。
この記事が気に入ったらサポートをしてみませんか?