
HER : 失敗から学ぶ強化学習アルゴリズム

以下の記事が面白かったので、ざっくり訳してみました。
・Ingredients for Robotics Research
1. はじめに
OpenAIでは、8つの「Robotics環境」と、「HER」(Hindsight Experience Replay)のベースライン実装をリリースしました。過去1年間の研究用に開発されましたものになります。これらの環境を使用して、実際のロボットで動作するモデルを訓練しました。
2. Robotics環境
このリリースには、「MuJoCo」を使用するOpenAI Gym用の8つの「Robotics環境」が付属しています。
環境は次のとおりです。
◎FetchReach-v0
エンドエフェクタを目標位置まで動かすタスクです。

◎FetchSlide-v0
エンドエフェクタでパックを打って、目標位置まで動かすタスクです。

◎FetchPush-v0
エンドエフェクタでボックスを押して、目標位置まで動かすタスクです。

◎FetchPickAndPlace-v0
グリッパーでボックスを掴み、目標位置まで動かすタスクです。

◎HandReach-v0
各指先を、目標位置まで動かすタスクです。

◎HandManipulateBlock-v0
ブロックを回転させて、目標の位置と向きまで動かすタスクです。

◎HandManipulateEgg-v0
卵を回転させて、目標の位置と向きまで動かすタスクです。

◎HandManipulatePen-v0
ペンを回転させて、目標の位置と向きまで動かすタスクです。

すべての新しいタスクには、「目標」の概念があります。デフォルトでは、すべての環境で、目的の目標がまだ達成されていない場合は「-1」、達成された場合は「0」(許容範囲内)の「まばらな報酬」が適用されます。これは、Gymの連続制御問題の「Walker2d-v2」で使用されていた整形報酬とは対照的です。
また、環境ごとに報酬が高いバリアントも含まれています。ただし、ロボットアプリケーションではまばらな報酬がより現実的であると考えており、代わりにまばらな報酬バリアントを使用することをお勧めします。
3. HER : Hindsight Experience Replay
失敗から学ぶ強化学習アルゴリズム「HER」(Hindsight Experience Replay)をリリースしました。私たちの結果hあ、「HER」がわずかな報酬から、新しい「Robotics環境」のほとんどで方策を学習できることを示しています。以下に、「HER」のパフォーマンスをさらに向上させる可能性のある、将来の方向性を示します。
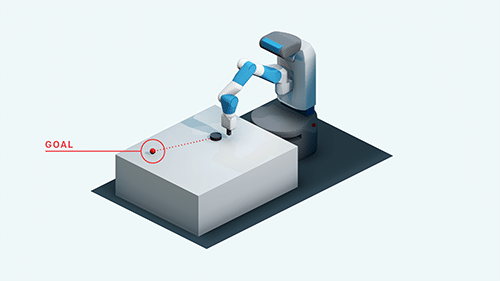
「HER」の機能を理解するために、「FetchSlide」のタスクを見てみましょう。これは、エンドエフェクタでパックを打って、目標位置まで動かすタスクです。
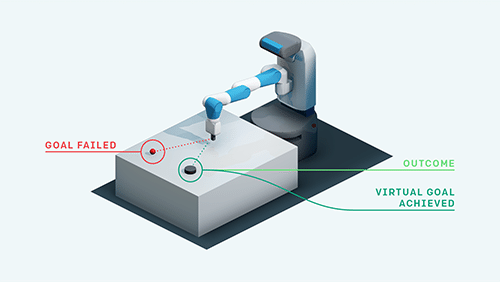
最初の試みで成功することは、ほとんどないでしょう。非常に幸運でない限り、次のいくつかの試みも成功しない可能性があります。典型的な強化学習アルゴリズムは、学習シグナルを含まない一定の報酬(この場合は-1)を取得するだけなので、この経験からは何も学習しません。
「HER」の重要な洞察は、人間が直感的に行うことです。特定の目標を達成していない場合でも、少なくとも別の目標を達成しています。この置換を行うことにより、強化学習アルゴリズムは何らかの目標を達成したとして、学習シグナルを取得します。達成するつもりがなかったとしても、このプロセスを繰り返すと、最終的には、本当に達成したい目標を含む、任意の目標を達成する方法を学ぶことになります。
このアプローチにより、報酬がまばらで実際に目標を達成できなかったとしても、パックを打って目的位置まで動かすタスクを学ぶことができます。エピソードが終了した後、後知恵(Hindsight)で選択された目標で経験を再生するため、この技術を「Hindsight Experience Replay」と呼びます。したがって、「HER」はオフポリシーRLアルゴリズムと組み合わせることができます。たとえば、「DDPG」と組み合わせることができ、その場合は「DDPG + HER」と表記します。
4. 結果
「HER」は、報酬がまばらな環境でうまく機能することがわかりました。
新しいタスクで「DDPG + HER」と「vanilla DDPG」を比較します。この比較には、各環境の「まばらな報酬」(sparese rward)と「密な報酬」(dense reward)のバージョンが含まれます。
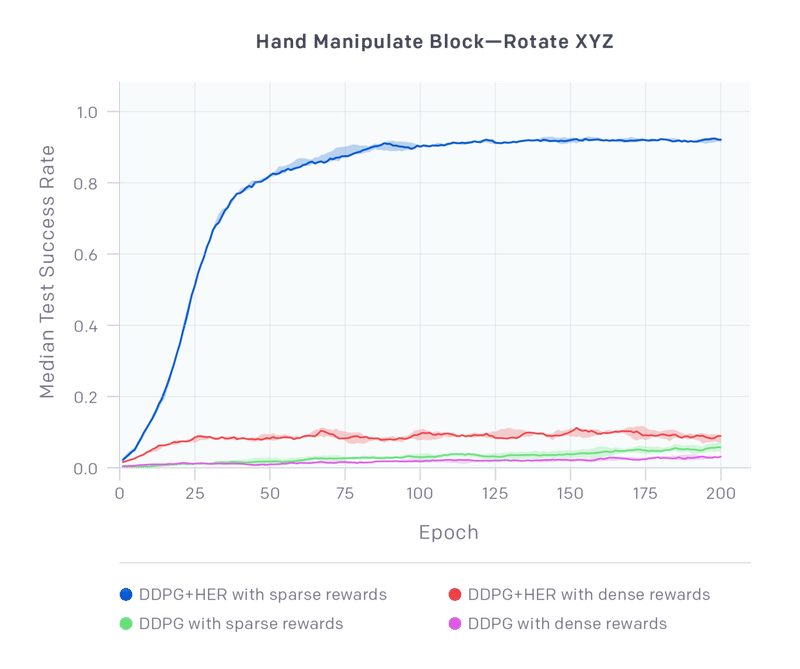
まばらな報酬を持つ「DDPG + HER」は、他のすべての構成よりも大幅に優れており、まばらな報酬のみからこの困難なタスクで成功する報酬を学習することができます。興味深いことに、密な報酬の「DDPG + HER」は学習できますが、パフォーマンスは低下します。「vanilla DDPG」はどちらも学習できていません。この傾向は、ほとんどの環境で一般的に当てはまることがわかっており、添付のテクニカルレポートに完全な結果が含まれています。
この記事が気に入ったらサポートをしてみませんか?