
【Excel】もう元データを崩してデータ分析しなくていい★UNIQUE関数・SORT関数

こんにちは、HARUです!
店舗や施設の来店者や売上実績を確認するために、リピーターと新規顧客を分けてターゲティングしたり、購入金額や購入単価順に並び変えて分析したりすることがあります。
たとえば以下のようなマスターデータがあったとして、いずれかの店舗を複数回利用しているリピーターと1度きりしか来店していない新規顧客を1つずつピックアップするのは大変です。
また購入金額等で並び変えるにしても、せっかく蓄積した表のデータ順序を崩すのはできれば避けたいですよね。
そこでこの記事では、重複データのすみ分けや元データを崩さない並び替えを実現する「UNIQUE関数」「SORT関数」をご紹介します。
いずれの関数もMicrosoft365またはExcel2021で使える関数です。
以前の記事で取り上げた「スピル」動作に触れておくことでより理解が深まりますので、まずそちらをご覧いただくことをおススメします!
↓スピルの挙動と活用術はこちら↓
UNIQUE関数はスピルやFILTER関数の記事でも少し触れていますが、今回で徹底解説していきますので、ぜひ最後までご一読ください!
UNIQUE関数
uniqueは「一意」「唯一」「個性的」を意味する英語です。
デフォルトの仕様では、重複しているデータは1つに絞り、ダブりなく取得できます。
新規顧客と複数回来店しているリピーターが混在する元データから、対象の氏名を取り出していきます。

UNIQUE関数の基本動作
▶すべてのデータを重複なく取得
新規・リピーター関係なく、1度でも商品を購入している氏名をダブりなく表示します。
①UNIQUE関数を挿入する。
②第1引数「配列」に氏名の範囲を参照する。

UNIQUE関数の必須引数はこれだけです。
これにより、すべての氏名をダブりなくスピルで取り出せます。

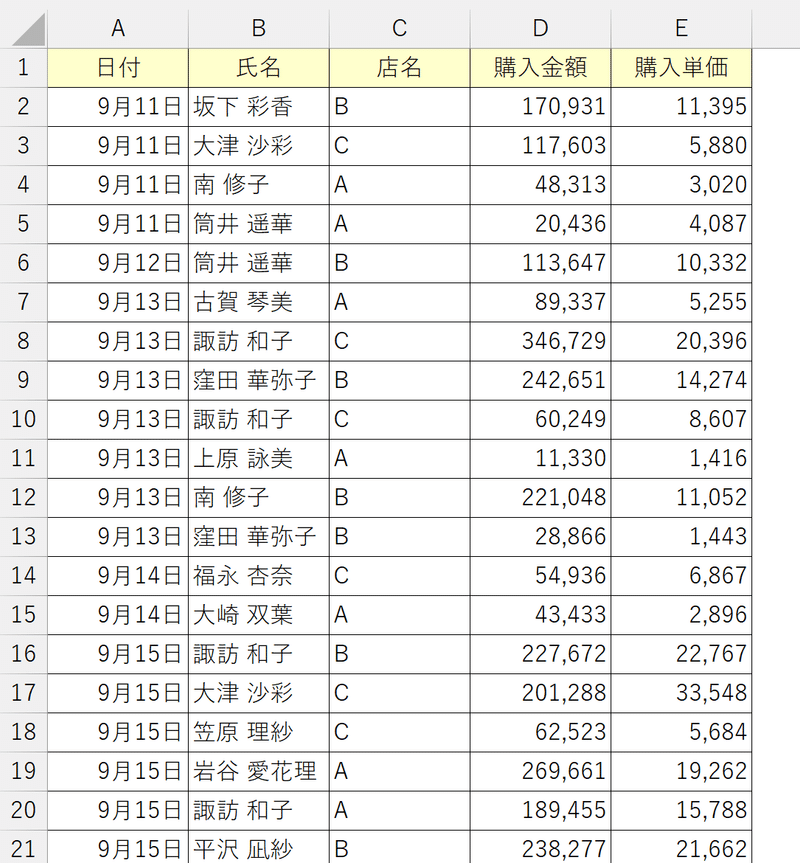
なお、UNIQUE関数の第2引数「列の比較」は、横に並んだデータを重複なく取得するときに使います。
下図はUNIQUE関数の第2引数を設定せずに参照した状態です。
すべてのデータがそのまま表示されます。

ここで「列の比較」をTRUE(一意の列を返す)にすると、UNIQUE関数が横方向(列単位)で機能します。

実務では縦方向(行単位)に蓄積されたデータを扱うことが多いため、第2引数は基本的にスルーでOKです。
参考までにおさえておきましょう。
▶1件だけ存在するデータの取得
過去に来店記録がなく、初めて商品を購入した新規顧客を表示します。
①UNIQUE関数を挿入し、第1引数「配列」に氏名の範囲を参照する。
②第2引数「列の単位」はスキップする
③第3引数「回数指定」に、TRUE(1回だけ出現するアイテムを返す)にする。

これにより、対象範囲に一度だけ登場した氏名を取得できます。

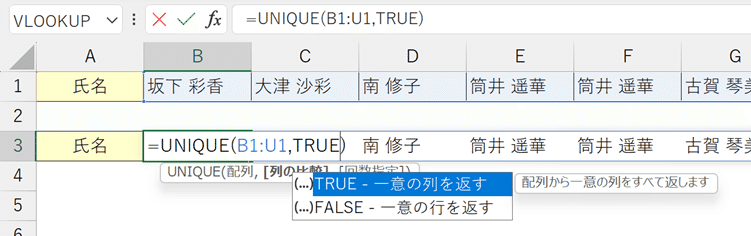
▶複数件存在するデータの取得
すでに2回以上購入記録があるリピーターを表示します。
①表の欄外にCOUNTIF関数を挿入し、その時点の過去購入回数を数える。
これにより、商品を複数回購入しているデータには2以上の値が返される。

COUNTIF関数で重複データをナンバリングするテクニックは、VLOOKUP関数の記事で詳細をご紹介しています。
↓VLOOKUP関数の徹底解説はこちら↓
②FILTER関数を挿入し、第1引数「配列」に氏名の範囲を参照する。
③第2引数「含む」に氏名の登場回数をカウントした①の範囲を参照し、その値が1を超えているか(複数回購入しているか)を判定する。

これにより、リピーターの氏名が取得できる。
ただし3回以上購入履歴のあるデータはリピートした数だけ氏名が表示されるため、最後にこれをUNIQUE関数で絞っていく。

④UNIQUE関数でFILTER関数をネストする。
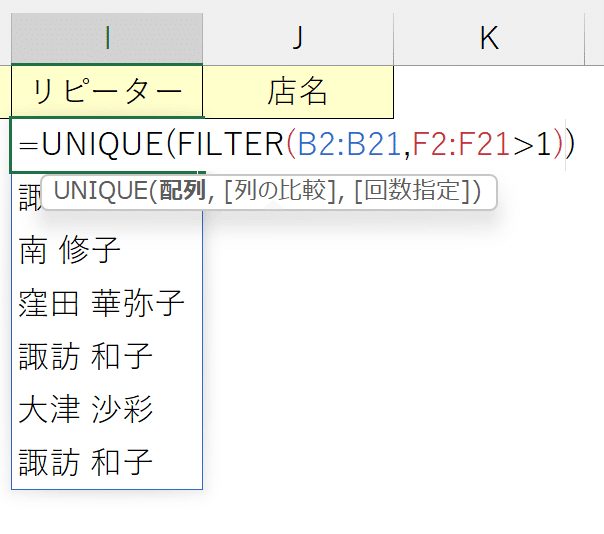
これにより、対象範囲に複数回登場した氏名を取得できます。

ちなみに、UNIQUE関数の第1引数「配列」も複数列にまたがって指示できます。
(下図は元データにおいて氏名と店名の範囲を参照した状態)
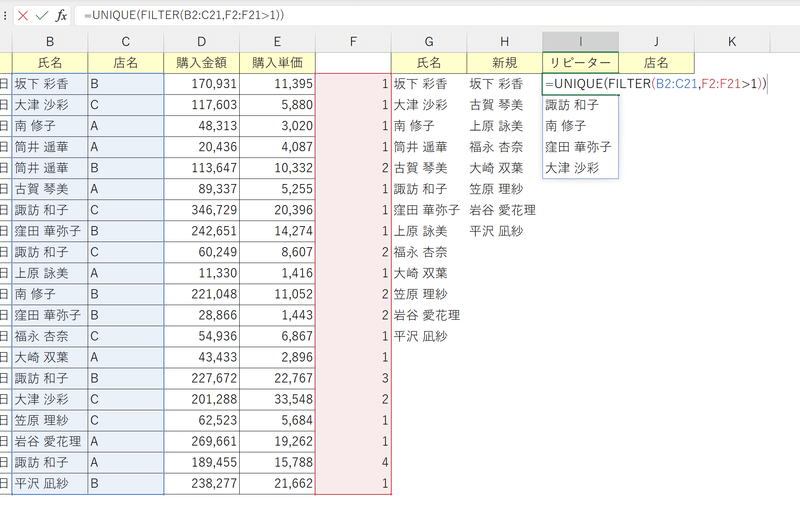
この場合は氏名単体でなく、氏名と店名の組み合わせとしてユニークな値が返されます。
たとえばこの中に諏訪さんは3回登場していますが、諏訪さんと店舗C、諏訪さんと店舗B、諏訪さんと店舗Aの組み合わせはそれぞれが一意のため、以下のように表示されるのです。
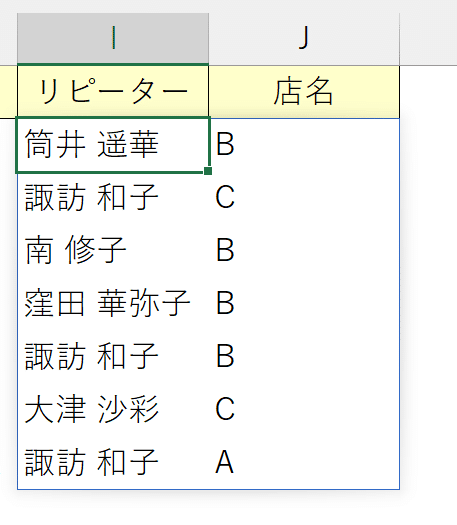
UNIQUE関数の活用例
▶ドロップダウンリストに
スピルやFILTER関数でも触れた通り、重複データがある場合に1件ずつ残してくれるUNIQUE関数はドロップダウンリストとの相性が良いです。
①UNIQUE関数で店名の範囲を参照する。
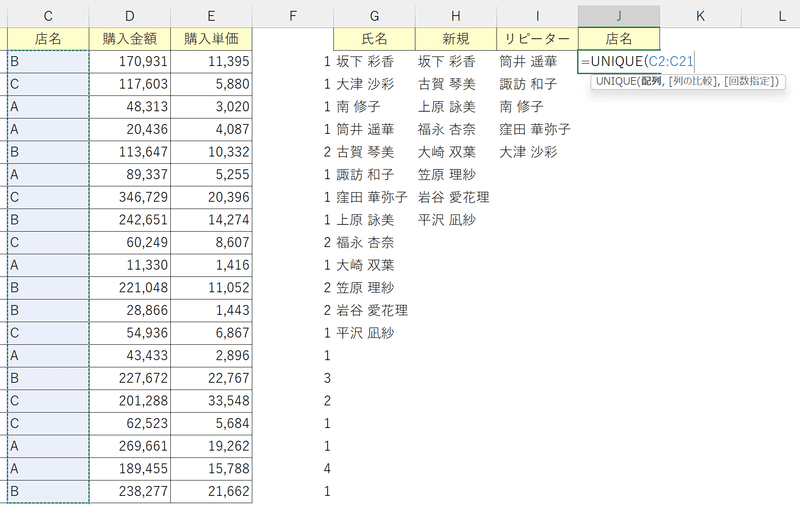
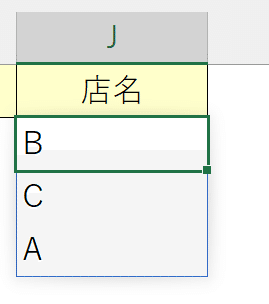
②「データの入力規則」を呼び出し、入力値の種類から「リスト」を選択する。
③元の値に、UNIQUE関数を挿入したセル番地とスピル演算子を付与する、

これにより、モレなくダブりなく取得したリストから店名を選択できます。

▶マトリクス表にしてデータ分析
UNIQUE関数で取得した重複のないデータを見出しとすることで、縦に日付、横に向け先を並べるなど、マトリクス表でのデータ分析を効率的に行えます。


なお、先ほど生成したドロップダウンリスト(アルファベット)の順番が気になるときは、次に解説するSORT関数を使いましょう。
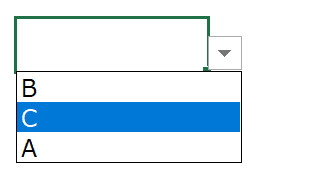
店名を取得したUNIQUE関数をSORT関数の第1引数「配列」に入れ込みます。
(それ以外の引数は省略化可能です)
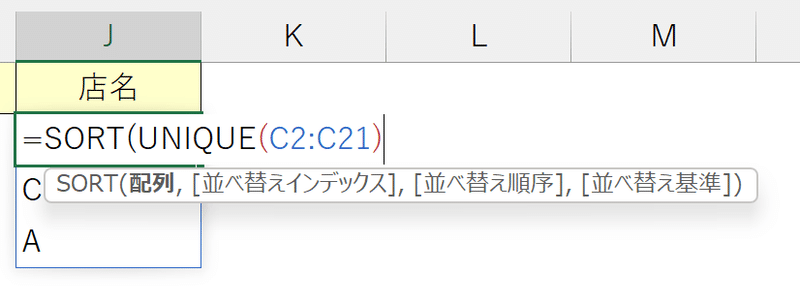
これにより、元のスピル範囲とリストのアルファベット順序が揃います。

それではここから、このSORT関数を演習します。
SORT関数(SORTBY関数)
sortは「種類」「分別」「並べ替え」を意味する英語です。
Excelでは値やアルファベットなどの順序だった体系を決められた順に並び替える役割を持ちます。
SORT関数の基本動作
下図はUNIQUE関数でサンプルとした表のサマリデータです。
これを年齢や金額に応じて並べ替えます。

まずはシンプルに年齢の若い順に並び変えます。
①SORT関数を挿入し、第1引数「配列」に元データの範囲を参照する。
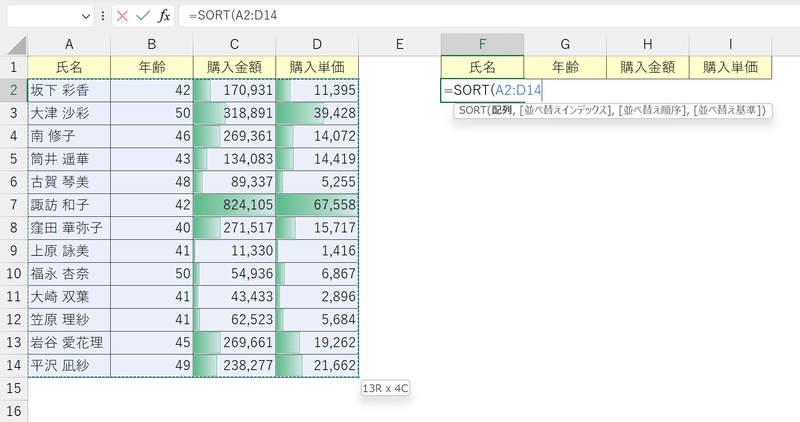
②第2引数「並べ替えインデックス」に、第1引数「配列」内のどの列にあるデータで並び変えるかを値で指示する。
今回は年齢でソートするため、左から"2"列目を入力する。
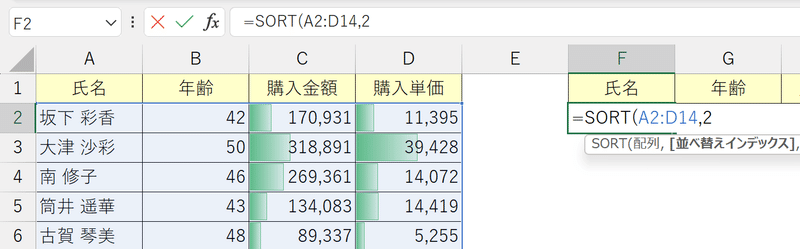
③第3引数「並べ替え順序」にどの方向から並べ替えるかを指示する。
今回は年齢の若い順にソートするため、値が小さい方から大きい方へ並ぶ"(1)昇順"を入力する。

④第4引数「並べ替え基準」は、UNIQUE関数の第2引数「列の単位」で横方向(列単位)にユニークデータを取得したのと同じだ。
今回のように縦方向(行単位)でデータが蓄積されている表を並び替えるときは無視する。

これにより、年齢の若い順にデータが入れ替わります。
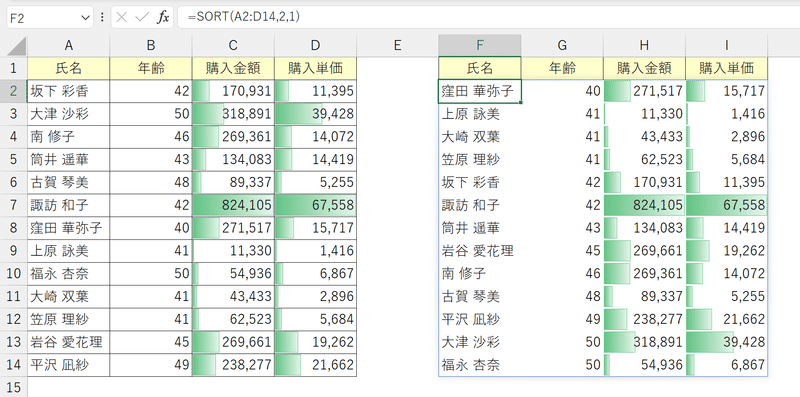
※今回はあらかじめH列・I列にC列・D列と同じ値の表示形式と条件付き書式(データバー)を設定しておきましたが、実際に動的配列数式でデータを取得するときは、書式を再設定する必要があります。
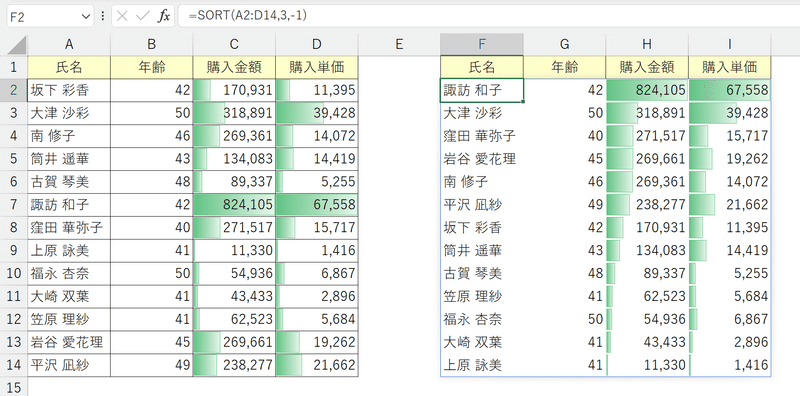
ためしに第2引数「並べ替えインデックス」を"3"列目とし、第3引数「並べ替え順序」を"(-1)降順"にすると、購入金額が大きい順に並び替えられます。
複数条件で並び替え(SORTBY関数)
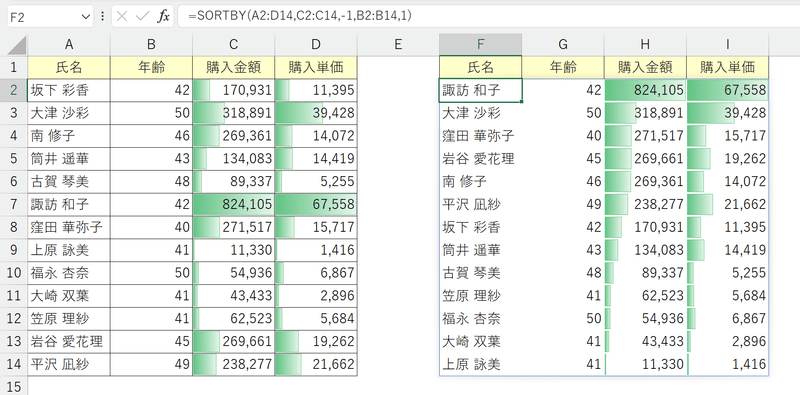
年齢を若い順に並べ、購入金額を大きい順に並べるなど複数条件でソートするときはSORTBY関数を使います。
①SORTBY関数を挿入し、第1引数「配列」に元データの範囲を参照する。

②第2引数「基準配列1」に年齢の範囲を参照し、第3引数「並べ替え順序1」を昇順にする。

③第4引数「基準配列2」に購入金額の範囲を参照し、第5引数「並べ替え順序2」を降順にする。

これにより年齢が若い順にソートされ、同じ年齢の場合は購入金額が大きい順に並びます。

第5引数「並べ替え順序2」を昇順にすると、同じ年齢の場合に購入金額の小さい順に並びます。

SORT関数で行う単一条件での並び替えもSORTBY関数でできるので、はなからSORTBY関数だけを使うのもおすすめです。
なお、SORTBY関数で指示した複数条件は、関数の中に記述した順に優先的に処理されます。
今回は「年齢が若いこと」→「購入金額が大きいこと」の順に入力(参照)しましたが、「購入金額が大きいこと」→「年齢が若いこと」の順に記述すると購入金額順にソートすることが優先されます。
ちなみに、SORT関数やSORTBY関数は日本語の並び替えには対応していません。
(下図はふりがなが認識された氏名を基準にソートした状態)
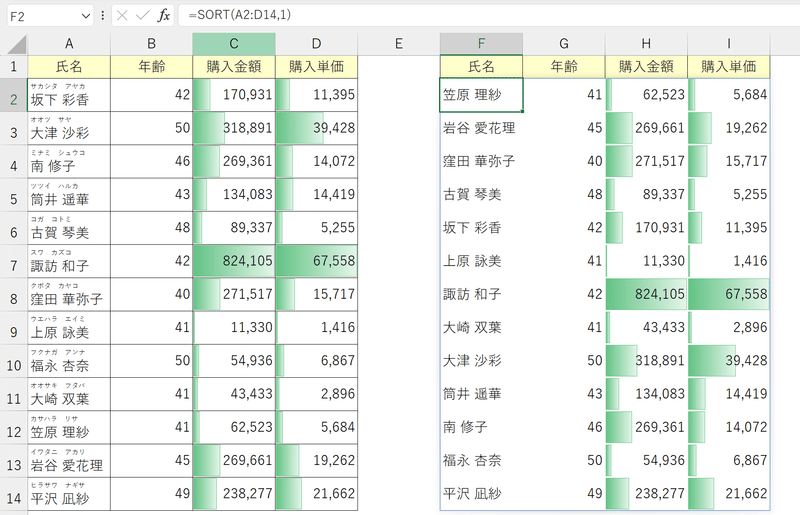
本来は、岩谷(イワタニ)さん、上原(ウエハラ)さん、大崎(オオサキ)さん……の順に並んでほしいところですが、まちまちになっています。
値やアルファベットを並び替えるときに活用していきましょう。
いかがでしたか?
今回はUNIQUE関数とSORT関数(SORTBY関数)をご紹介しました。
元のマスターデータを崩さずに表の欄外や別シートで様々な分析ができるので非常に便利ですよね!
日々の作業効率を格段に上げてくれるアイテムですので、積極的に実践していきましょう!
↓↓Excel操作をとにかく高速化したい方へ↓↓
この記事が気に入ったらサポートをしてみませんか?