「天気の子」興行収入127憶円を408万ツイートで予測・説明する。1/3

自己紹介
マーケティングにおけるデータ活用の支援を行っている小川と申します。昨年、「Excelでできるデータドリブン・マーケティング」という書籍を出版しました。
5~6年前からマーケティングの戦略を決めるのに役立つデータ分析に注力しています。現場のマーケターや経営者に統計など分析の基礎知識が浸透していないため、分析が実行に結びつかなかったり、間違えた因果関係の把握による意思決定がされたりしています。
「マーケティングサイエンスをもっと身近にしたい」と考え、企業支援の傍ら、執筆を行っています。マーケティングの生産性を上げるための分析法を多くの方に浸透させたいと思っています。
そのために書いた拙書の宣伝活動にもなっています。
身近なトピックを使って分析し、多くのかたに分析に興味を持ってもらうためのコラムを書いています。先日は日テレの「あなたの番です」のツイート全数を分析し、考察と思われるツイートから誰が一番疑われていたか?など分析しました。
今回のテーマは大ヒットしている「天気の子」です。9月15日で興行収入は127憶円を超えたそうです。
このヒットを解き明かす分析の例を紹介します。
ソーシャルリスニング×時系列データ解析
ブログやツイッターなど、ネット上から得られる消費者から示唆を導くことをソーシャルリスニングと言います。そうしたデータから映画などのエンターテインメントのヒットを予測または説明する方法が先行研究などで模索されてきました。
例えば、下記の文献(ヒット現象の数理モデル(石井2015))では、
「テルマエ・ロマエ」のTwitter書込み数を数理モデルで解析した例や「神様のカルテ」と「アオハライド」の封切り4日前のブログ書込み数から、封切り5日以降を予測計算したものと、封切り2か月後のブログ書込み数から予測した値を比較した例などが紹介されています。

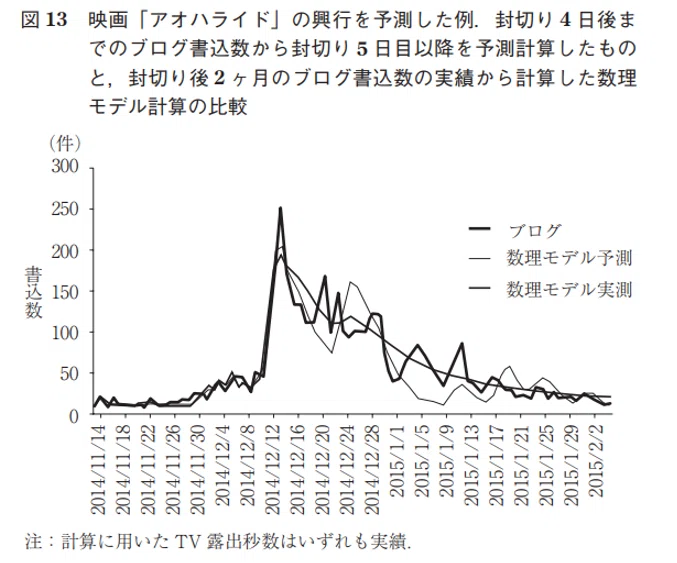
※出典元 ヒット現象の数理モデル(石井2015)
これから紹介するのは、Excelでできる時系列データ解析です。
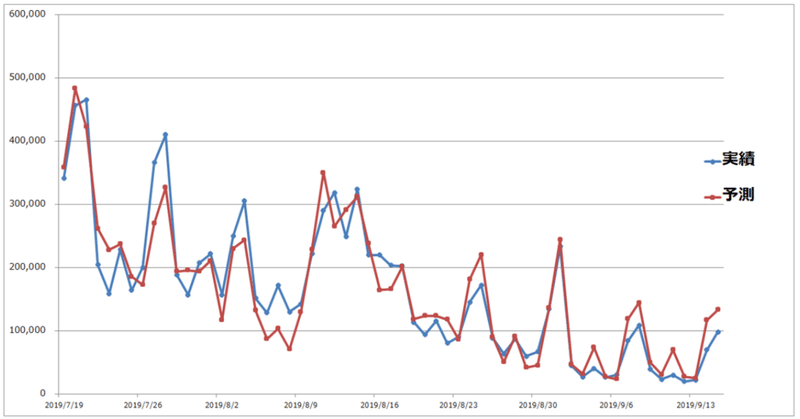
公開開始の7月19日から、興収127億円となった9月15日までの期間で「天気の子」の単語を含む408万超のツイートを抽出し、そのデータを活用しチケット販売数を予測・説明します。
2万字を超えそうなので3回に分けることにしました。なお、映画のネタバレはありません。
1回目:ツイート数を用いた時系列データ解析によって127憶円の興収の変動を予測・説明する。
2回目:因果関係の把握に重要な知識を紹介し、戦略意思決定のミスリードを減らす。
3回目:TVCMなど、マーケティング施策予算配分最適化の「極意」を共有する。
ツイート数を用いて、「天気の子」の販売数を予測・説明
天気の子のヒットにツイートが及ぼした影響を解明していきましょう。
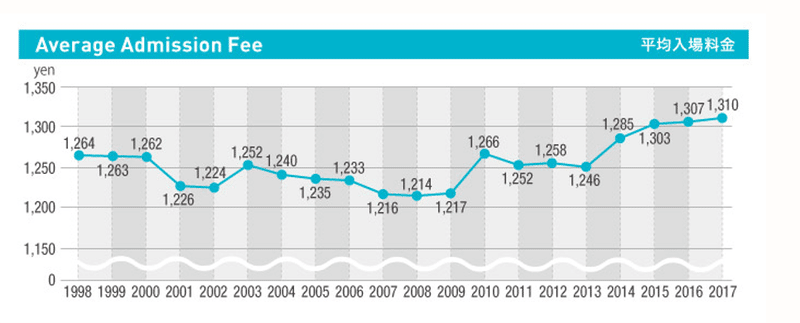
まずは、映画チケット販売数データを成型します。今回の分析では、以下の「興行収入を見守りたい」サイトの公開データを参照しました。各シネコンサイトの映画チケット販売数を収集しているそうです。取得方法はこちらのページに記載があります。全数ではなく標本データです。
2019年7月19日から9月18日までの「デイリー合算ランキング」の販売数を参照しました。
累計販売数は約593万でした。これに平均入場料金1,310円を掛け合わせた合計金額が約77.6憶円でした。127憶円と乖離があったため、補正係数1.634589を各値に掛け合わせ補正した値となる「販売数(補正)」を分析用データとして使用します。
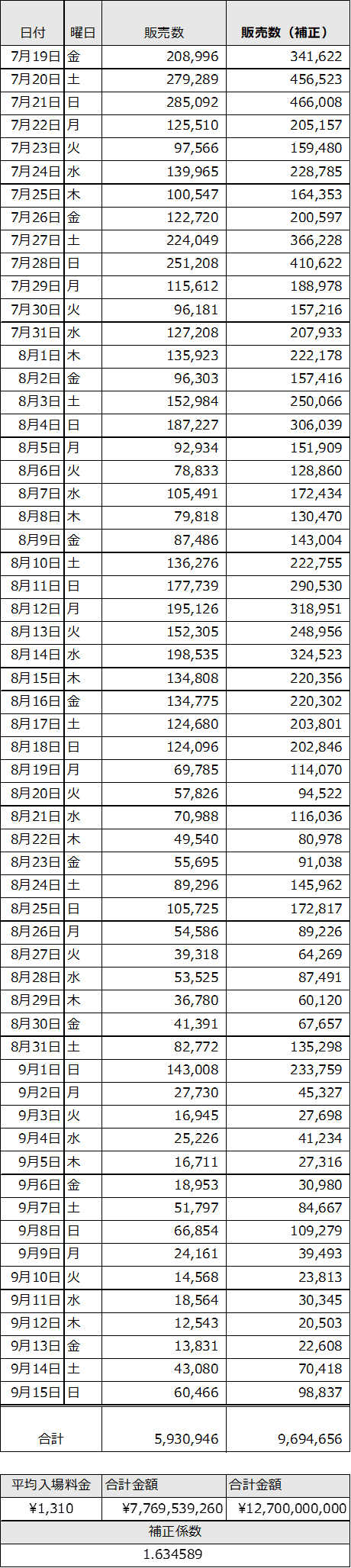
映画の平均入場料金は、日本映画製作者連盟(映連)サイトで公開されている統計情報のグラフ(以下、2017年の値)を参照しました。
ツイートデータは電通グループのCCI社が提供するコミュニケーションエクスプローラー(以下「CE」)を用いて集計します。特定の単語を含むツイートやユーザー指定などで、2007年まで遡って日本のツイートの全数抽出や言語解析などが行えるツールです。1週間のお試し利用ができます。
CEを用いて「天気の子」の単語を含むツイートを集計したところ、408万強のツイートがありました。
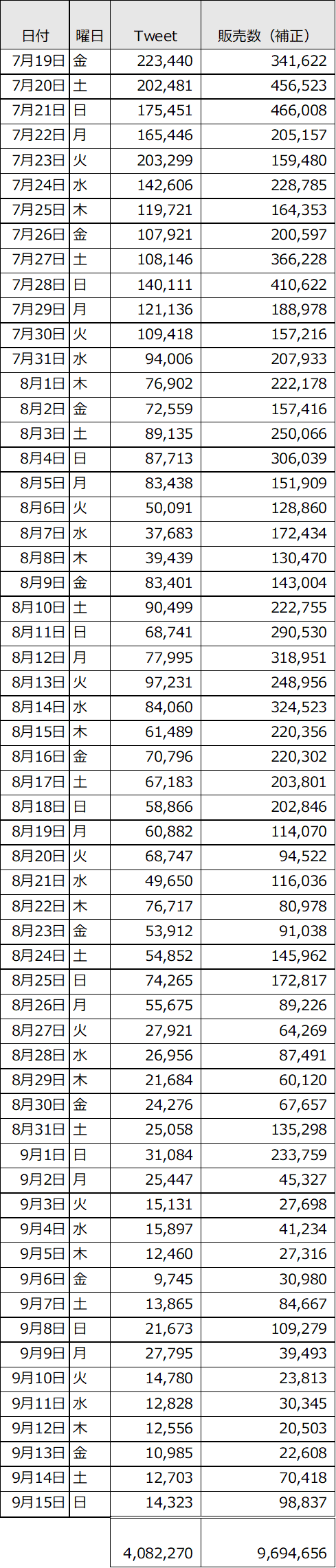
2軸の折れ線グラフにしました。販売数は土日や祝日(お盆など)で急上昇する周期を描きながら緩やかな右肩下がりで少しずつ減少しています。2か月近く販売数を維持しています。対してツイート数は同様のトレンド(右肩下がり)で緩やかに減少していますが、土日や祝日の急上昇はありません。
ツイート数を使って販売数を予測・説明するために回帰分析という、統計解析ではオーソドックスな手法を使います。
方程式を導く回帰分析
回帰分析とは、Y=aX+b という方程式を導き、説明変数Xによって、目的変数Yの変動をどれくらい説明できるのか?Xが1増えるとYがいくつ増えるか?などを把握できる手法です。Excelでできます。Xを複数用いることもできます。
天気の子のツイートが1増えると映画館の販売数がいくつ増えるのか?その関係を把握するための方程式を作っていきたいと思います。
Y=aX+bのaを係数、bを切片と言います。
まず、目的変数「販売数(補正)」、説明変数「Tweet数」で回帰分析を実行した結果を紹介します。
以後「(補正)」の記載は省略します。また、下記はExcelで回帰分析を実行した結果から数値の小数点以下の表示やセル着色などの書式設定を一部加工したものです。
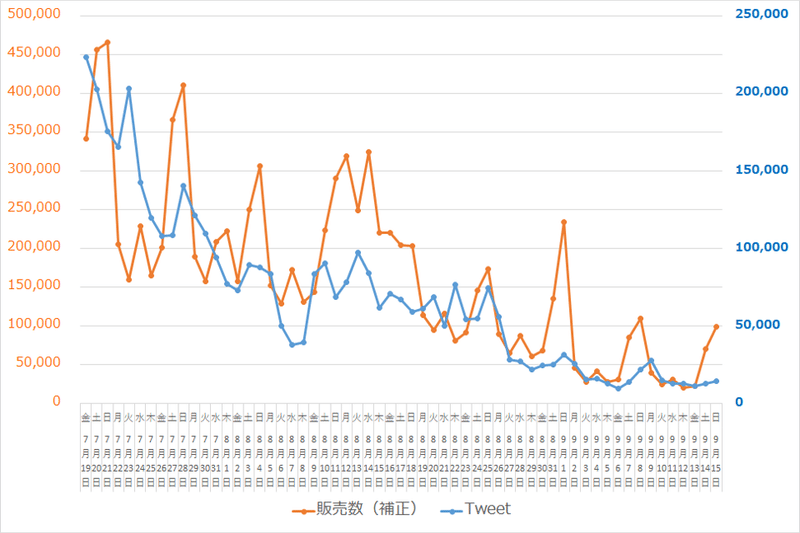
(Excelの)回帰分析で出てくる値のうち、主に参照する箇所を説明していきます。
今回の分析で知りたいのは、説明変数X(ツイート数)が1単位増えるとY(映画の販売数)がいくつ増えるかです。それが、
Y=aX+bの「a(係数)」です。ツイート数の横の「1.5947332」がそれにあたります。
切片の横の「53,975」が「b(切片)」です。
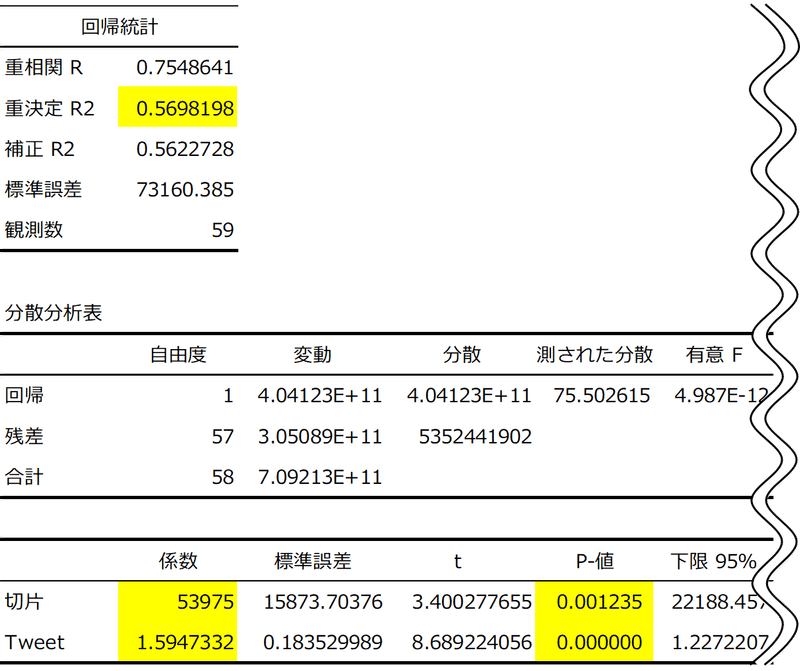
この関係をグラフで説明すると下記になります。横軸がX(ツイート数)で、縦軸がY(販売数)です。Xが増えれば増えるほど、Yも増える右肩上がりの関係です。
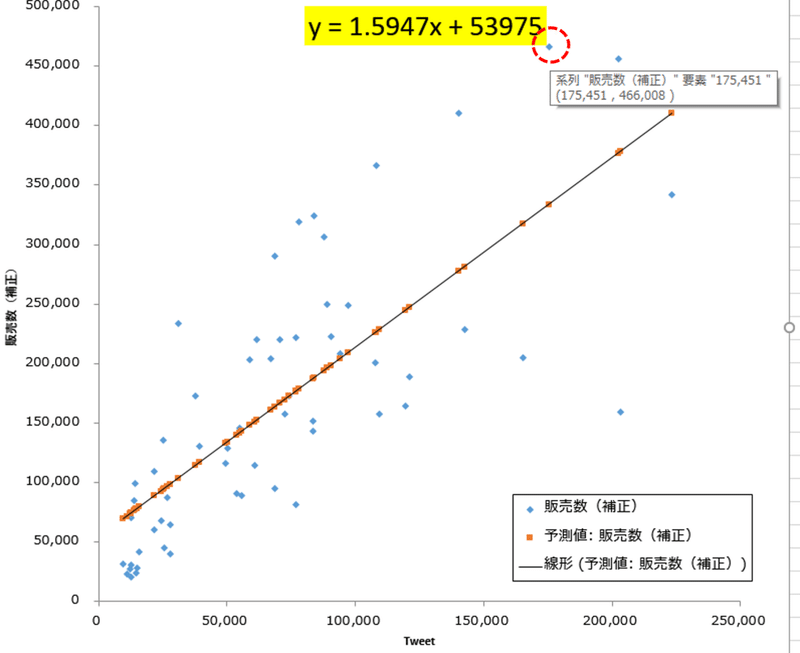
点線の赤丸で囲った青い点は販売数が最大値となっていた7月21日の値です。販売数Yは466,008でツイート数Xは175,451です。
他の青い点も同様に実際の値を示しています。対して、オレンジ色の点は方程式(y=1.5947x+53,975)によって導いた予測値です。
係数aはXが1増えるとYが1.5947増える関係の「傾き」を表しています。bは予測線を結んだ黒い線を伸ばしてY軸に当たる時のYの値です。Xの値が0だった時のYの予測値と考えられます。
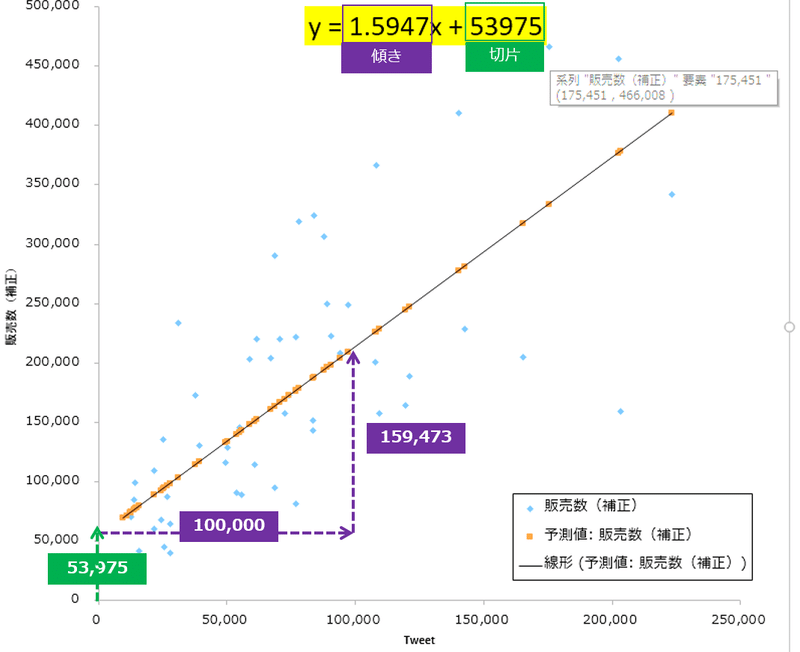
Xの値が増えれば増えるほど、Yの値が減る右肩下がりの関係の場合は、係数はマイナスになります。
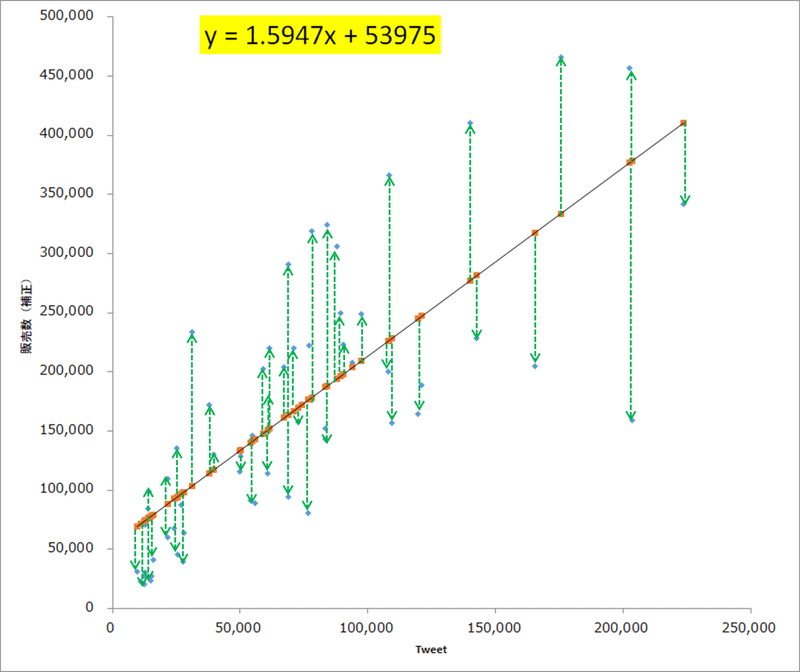
YとXの関係を求めるために、予測値と実績値の距離、以下の図の緑の矢印の長さを最小化する予測線を求めるのが回帰分析です。緑の矢印の値を残差と言います。残差は+と-の値をとります。全ての残差の値を足すと0になるため、残差の二乗して、その値の合計値を最小にするためのaとbを求め、方程式を導く分析が回帰分析です。
次に、決定係数とP値について説明します。
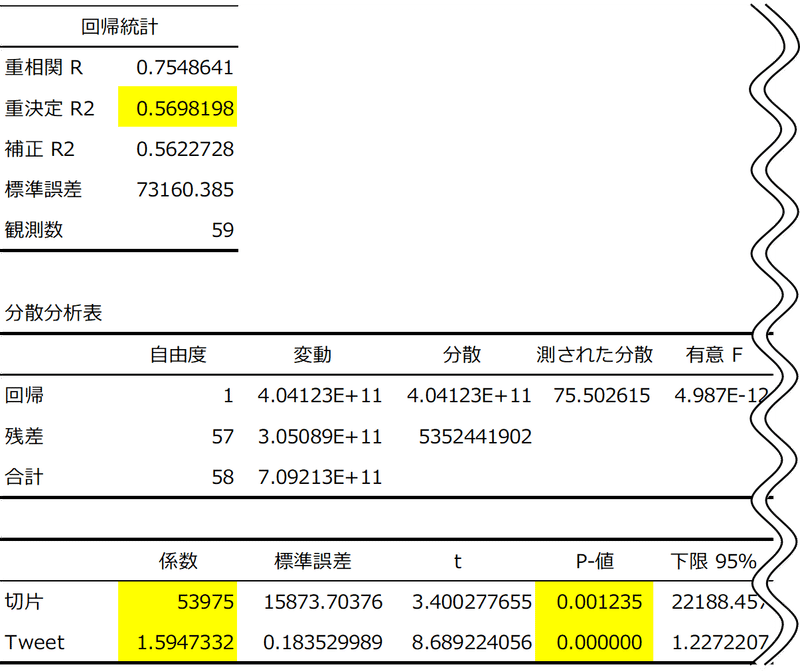
P値は、説明変数が目的変数に対して影響があるか?回帰分析で導いた係数が0ではないことを確からしく判断するために、「係数は0である」について検定した結果です。一般的にはこれが5%(0.05)を下回るのが望ましいとされています。有意水準といった言葉を聞いたことがあるでしょうか?一般的には5%または1%が用いられます。社会科学では10%が用いられることもあります。マーケティングは社会科学に内容が近しいことなどから、有意水準を10%として分析演習を進めていきます。
導いた方程式のあてはまり(≒予測精度)の良さを表す値が決定係数です。Excelの回帰分析で出力される重決定R2が決定係数に該当します。0.5698198となっています。これはYの値の総変動のうち、方程式によって説明できる変動の割合を示しており、予測精度の目安となります。
予測値と実績値と残差を折れ線グラフに
教科書的な解説はここまでにします。
このnoteでは、私の書籍の付録として提供しているExcelマクロを組んだプログラム(マーケティング施策の効果把握のための時系列データ解析ソフト)を使ってサクサク分析して、決定係数(≒予測精度)を上げていく手順を紹介します。
ツイート数、販売数と他の変数を用いた回帰分析によってどんな発見ができそうか?どんな風に活用できそうか?イメージして頂くことを目指します。
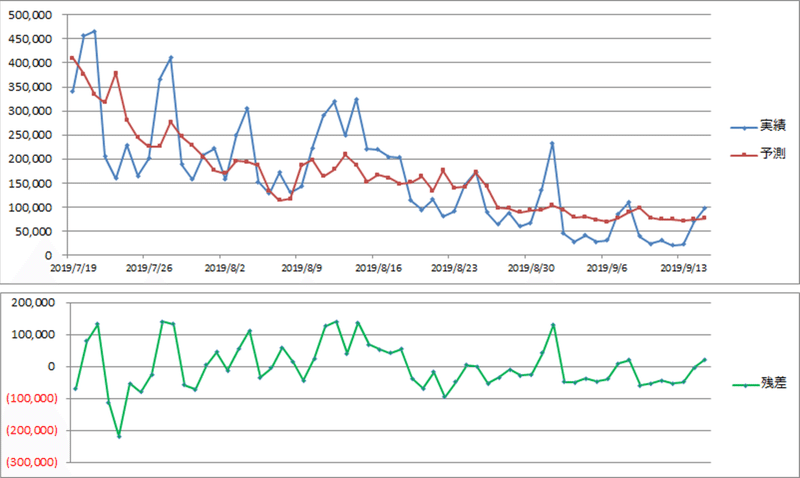
付録Excelではマクロ実行ボタンを押すだけで回帰分析を行えます。予測値と実績値と残差を自動で時系列のグラフにするなど、作業の手間を省く工夫をしています。
さきほど求めた方程式(y=1.5947x+53,975)による予測値と実績値と残差の折れ線グラフは下記です。
予測値はどのように計算されているでしょうか?
ツイート数×係数1.5947+切片53,975でそれぞれ計算されます。それを示すために作った表が以下です。
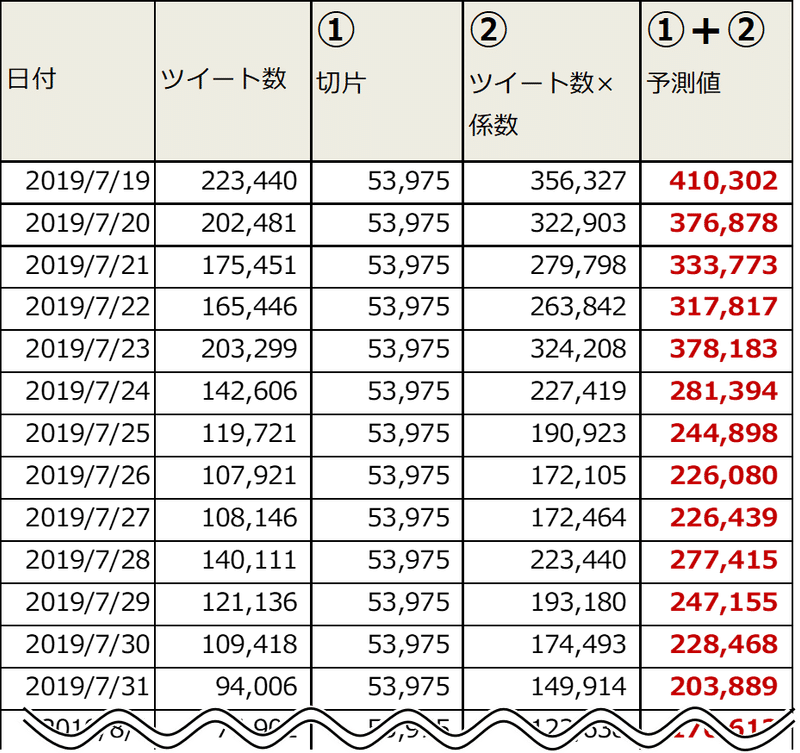
マクロ実行ボタンの「LINEST回帰1」を押すと回帰分析が行われ、切片や係数、P値だけでなく、効果数という値も計算されます。
「効果数」は、筆者が付録Excelの分析で自動算出する指標として独自に定義した用語です。
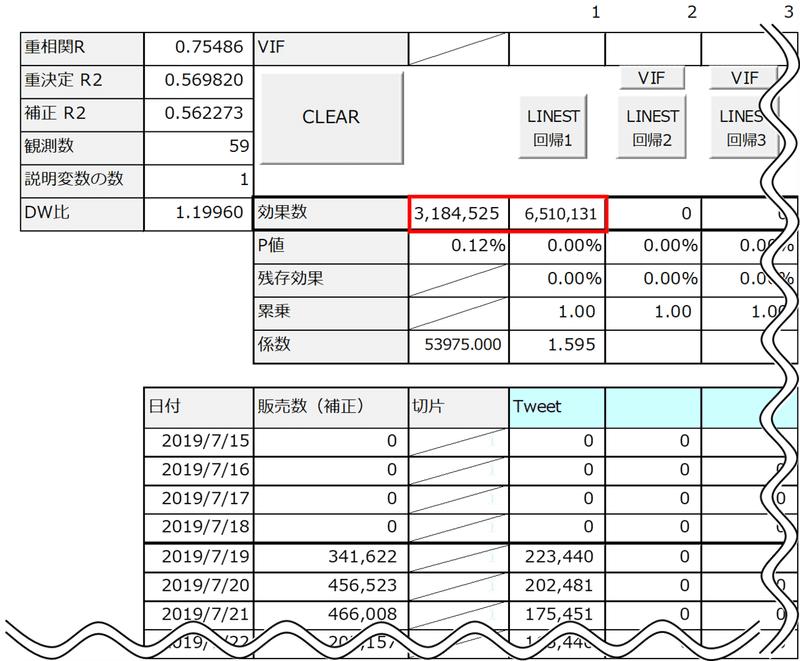
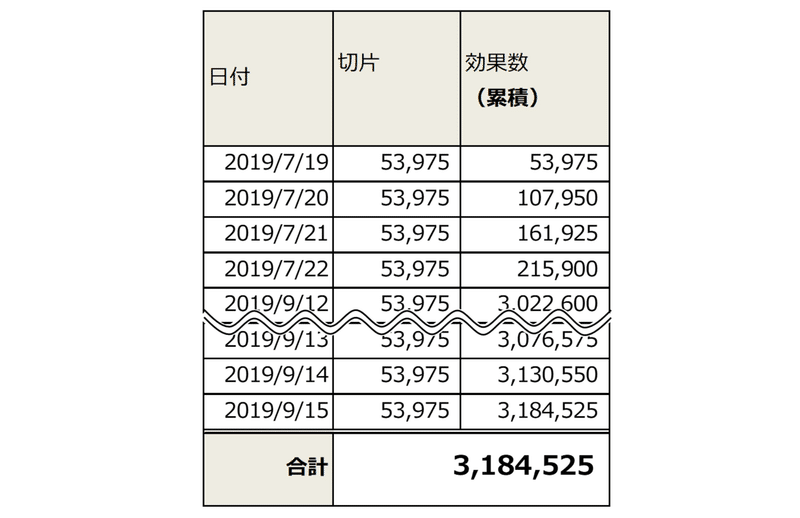
切片の効果数は3,184,525です。これは切片の値53,975×観測数(ここでは日数)59によって導いています。
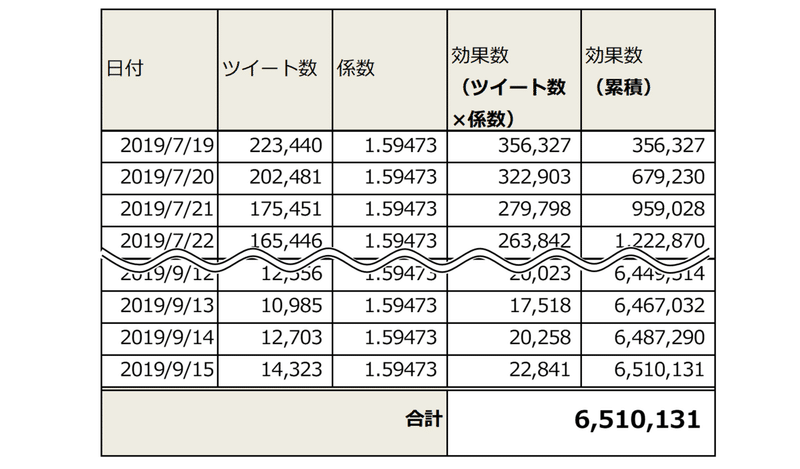
Tweetの効果数6,510,131は59日のそれぞれのツイート数×係数1.5947の合計値から導いています。
予測精度を上げるために説明変数を追加
次に、予測精度を上げるために、販売数に影響がありそうな要因を考え説明変数として追加していきます。
まず、曜日や祝日の影響を加えます。曜日や祝日などを表現するためには0と1の値を記載するダミー変数を用います。
以下のように、該当する日を1、該当しない日を0としていきます。
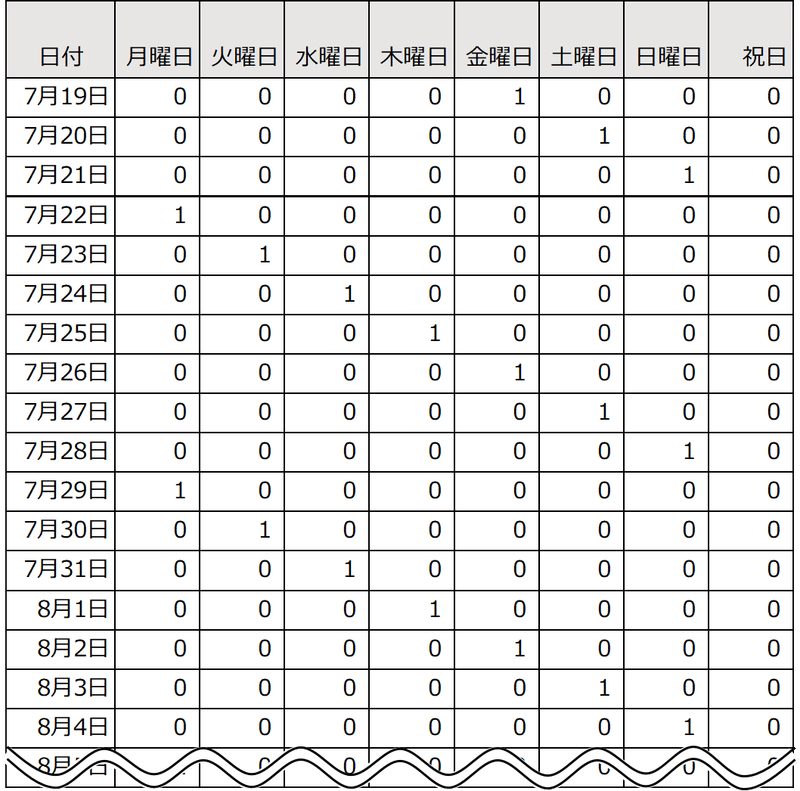
今回は、お盆の週の平日を全て「祝日」としました。
複数の曜日のダミー変数のうち、どれがYの予測に有益か?組み合わせた際に全てが有意水準が10%を下回る組み合わせを探したところ、水曜日、土曜日、日曜日、祝日が選択出来ました。
なお、拙書では適切な説明変数の組み合わせを採択の仕方の例を詳しくレクチャーしています。
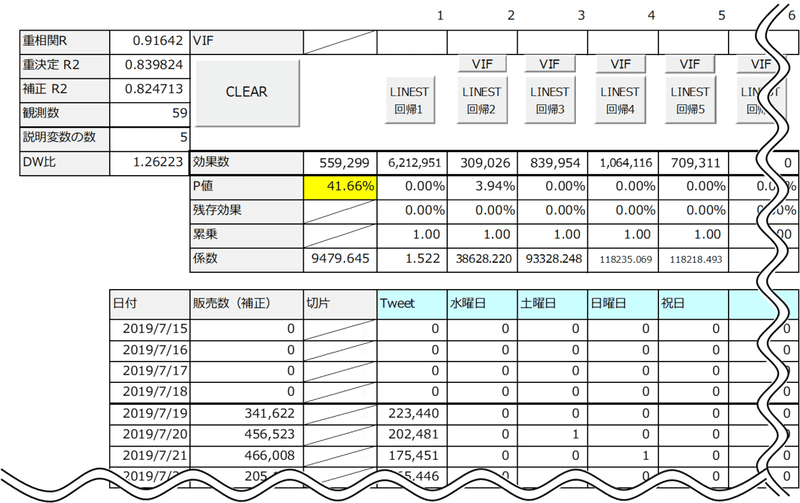
土日祝日が客足が伸びるのは当然ですが、水曜日についてはレディースデイなどのイベントがあるからでしょうか?
Excel付録では、切片またはP値が10%を上回ると自動で黄色く着色されます。この時点で黄色くなっている切片のP値は「切片は0である」を検定した結果です。係数の検定は、係数は0である(つまり、求めた係数には意味がない)かを検定していますが、それとは意味が違います。切片の絶対値が0に近づくとP値が高くなるだけですので、切片のP値は原則気にしなくて良いです。
説明変数は5個になりました。説明変数がひとつの回帰分析を単回帰分析、説明変数が2個以上の回帰分析を重回帰分析といいます。ただし、重回帰分析の場合は決定係数は補正R2を参照して下さい。単回帰分析の場合は、重決定R2を参照してください。
補正R2はExcelの独自用語です。正しくは自由度調整済み決定係数と言います。
一般的に決定係数は説明変数を増やすほど高くなります。目的変数への影響がない変数であっても、たくさん入れれば決定係数が上がります。自由度調整済決定係数は、それを補正した値です。
決定係数(自由度調整済み決定係数)は0.824713まで上がり、実績値と予測値がかなり近づきました。
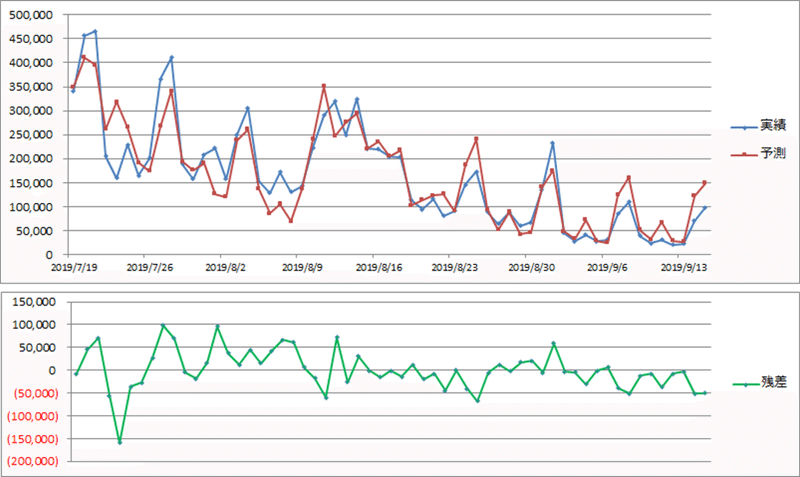
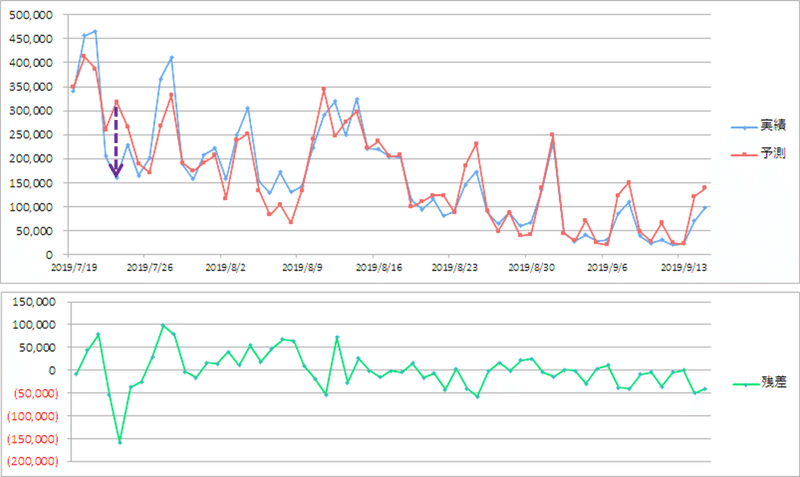
予測と実績の差分が大きいところにヒントがあります。例えば、紫の矢印で示した8月1日と9月1日です。映画好きな方ならばすぐわかると思いますが、チケットが安くなる映画の日の効果だと思われます。
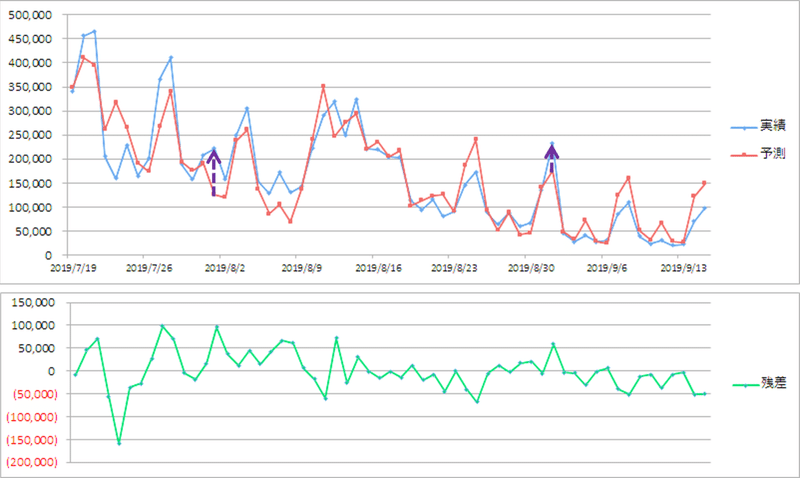
映画の日(8月1日と9月1日)をダミー変数として説明変数に加え分析し直しなおすと、残差は小さくなりました。
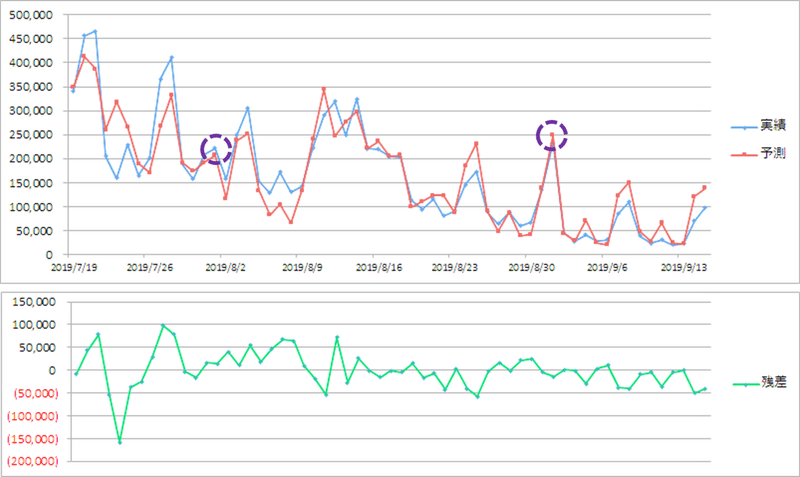
この段階で最も予測と実績の乖離が一番大きいのはこの箇所です。7月23日です。
この付近で何か要因がないか、調べたところ、気になった事象がありました。「天気の子」には原作となるパソコンゲームが存在するらしいという噂が(実際には存在しない)、ツイッターやネットでざわついた模様です。
これに関するツイートが急増したのが7月23日となっていました。このトピックがチケット販売にマイナス影響を与えたかもしれないため、ツイートを再度調べなおしました。
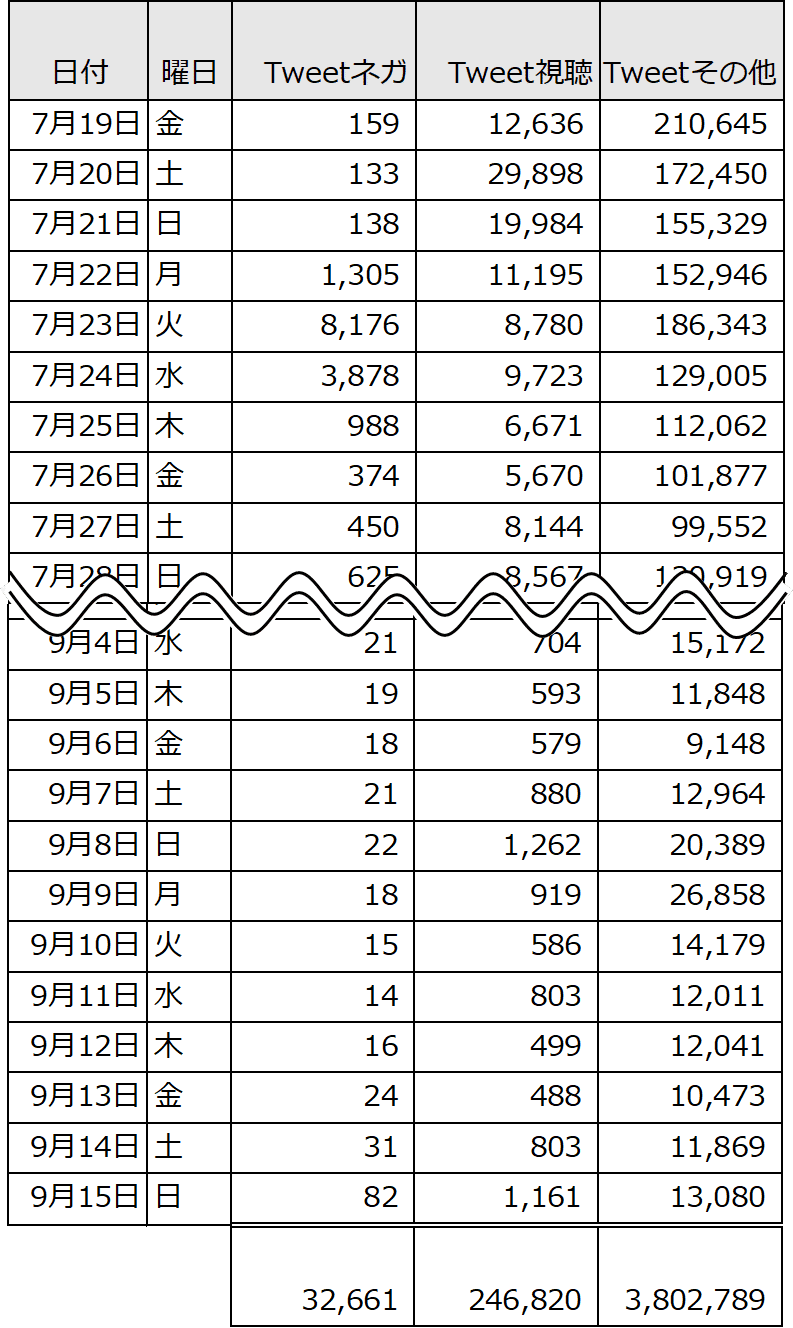
「天気の子」を含むツイートを下記の①②③に3分割しました。
①ネガティブツイート
「天気の子」and「原作」または「天気の子」and「パソコンゲーム」など、このトピックに関わる単語を含むツイートを抽出しました。
②視聴後ツイート
もうひとつ、「天気の子」ツイートのうち、「天気の子」and「見た」など視聴し終わった後と思われる単語(下記の1行ごとのor条件)で抽出しました。こうしたツイートはフォロワーへの訴求効果が高く、より映画の販売に貢献するのではないかと考え、このカテゴリーを新しく作りました。

③その他ツイート
「天気の子」を含む全ツイートから①と②の値を引いて「その他ツイート」としました。
これまでの説明変数「Tweet」をこの①②③と入れ替えて分析しました。
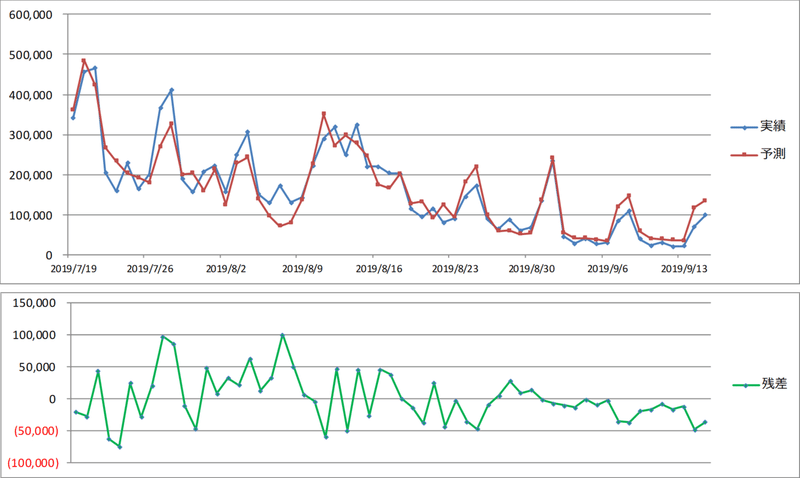
実績と予測の値がさらにあてはまりました。ネガティブなツイートが増えることで販売数にはマイナス影響が出ていた可能性があります。
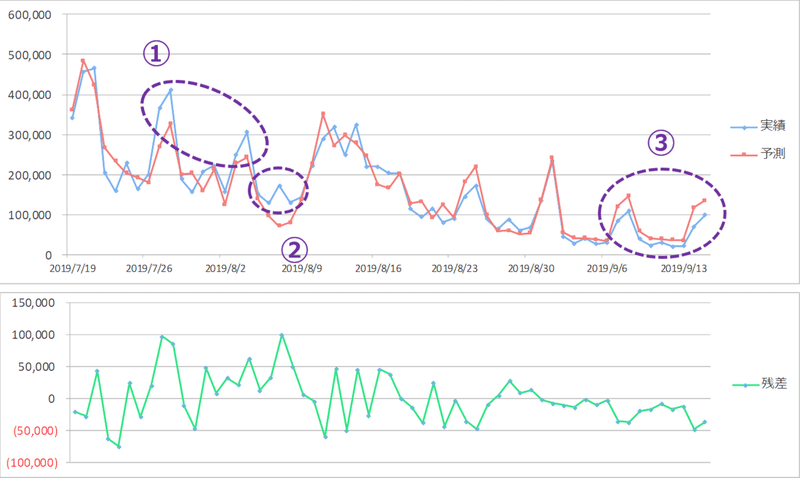
この段階で予測と実績の差が目立つ箇所は①②③でしょうか?
差が出たところに、「ダミー変数」をあてはめれば、予測と実績の差は縮まり、決定係数も増えて「それらしい」方程式はできますが、根拠の無いダミー変数のあてはめはNGです。ミスリードにつながります。
安易にダミー変数をあてはめることはせず、①②③について考えられる仮説を考えます。
①は土日が上振れしています。公開直後の上振れ分でしょうか?大規模なプロモーション施策が行われたなど、他の要因があるかもしれません。
②は8月6日、8月7日、8月8日の3日間です。8月5日に「興行収入60憶円」を突破したニュースが出て、「RADWIMPS」による主題歌のひとつ「大丈夫(Movie edit)」を使用した特別映像が公開されていました。それらが数日のプラス要因となっている可能性が考えられます。
③の時期(最近)は、ロングヒットとはいえ、上映館数や席数が減ってくる頃だと思います。「かぐや姫は告らせたい」 など、同じ東宝配給の作品など、天気の子と同様学生がコアターゲットの新作が出てきているので、その影響がマイナス要因となっているかもしれません。他の作品のツイートや広告の出稿量を説明変数に加えると、この下振れ分を説明できるかもしれません。
実際の分析ではこうした考察から、必要な変数を加えたり、減らしたりして予測精度を高めていきますが、本noteの分析は「あえて」ここまでに留めます。
然るべき手段で同作品のTVCMなどの広告出稿量の時系列データを調べ、説明変数として追加し、予測精度を上げ、同作品の広告それぞれが販売数に対して対してどれだけ寄与しているか?係数を導いて効果を把握することはできますが、そこまでは行いません。理由は3つです。
1:特定企業のTVCMなど、広告の効果を推定し公開することを避けた。
2:「時系列データ」を使って、事象(ここではYの映画の販売数の推計値)をツイートなどから予測する方法の雰囲気をつかんで頂くことを重要視しているため、難解な分析手順の紹介を避けた。
3:次回noteで紹介する因果関係を考える際に「考慮すべきこと」を説明するために広告など、本来必要と考えられる説明変数を欠落させた。
方程式によって導いた結論は?
最終的に作った方程式に用いた切片と係数を見てみましょう。ネガティブなツイートがマイナス係数となり、「見てきた」「観てきた」など、視聴完了ツイートの係数がその他のツイートの係数の4倍近い値になっています。
これは、感覚的に理解できる結果ではないでしょうか?
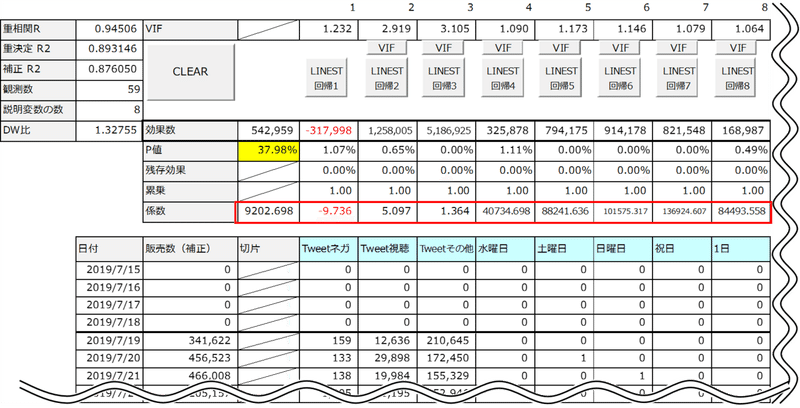
3種類のTweetの説明変数のそれぞれの効果数に平均入場料金1,310円を掛け合わせ、Tweetによって興行収入が増えた金額を導きました。「%」は127憶円に対する割合です。
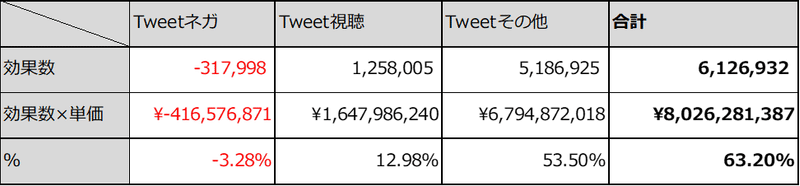
3つの%を足し上げるとおよそ6割強です。つまり、
「天気の子」の興行収入127憶円の6割強の80憶円がTweetの影響によって増えた。
と、分析結果から導けました。しかし、興行収入(ここでは「販売数」データを元にした推計値)にTweetの影響があることはおそらく間違えなさそうですが、6割強は多すぎる気がしませんか?
回帰分析によって、Xが1増えるとYはいくつ増える、こうした因果関係を数値で把握する場合に、考慮しなければならないことがあります。しかし、これまで紹介した分析ではそれができていません。
現状の分析結果では、間違えた結論である可能性が高いのです。
次作(2回目のnote)では、PRにまつわる変数や指名検索数なども加えて分析を行いながら、分析時に考慮すべきことは何か?について説明していきます。マーケティングの意思決定において、重要な知識がマーケティングの現場で殆ど知られていないため、ぜひ、知って頂きたいと思います。
実はまだ、
私はこの映画を観に行けてません。執筆のために一人で観ようとしましたが、それも寂しいので、家族と行けるタイミングを探っています。
冒頭でネタバレを書きませんとしていましたが、当然です。私自身がネタバレツイートを見ないようにツイートの文字を読む分析を避け、時系列の変動を調べていました。映画もツイートのコメントも見ていませんが、時系列データの推移と予測と実績のあてはまりが良くない箇所から、7月23日のネガティブツイートなどの事象に気づけました。天気の子の予備知識はゼロでも、時系列データ解析によって示唆が得られました。こうした分析を知ってるか否か?それによって折れ線グラフを眺めるだけか、新たな示唆を得られるか?大きく変わります。
時系列データの分析を活用した経験がない方はぜひチャレンジください。その1歩として、残り2回のnoteや私の書籍が少しでもお役に立てれば幸いです。次回のnote公開は10月初旬を予定しております。フォロー頂ければ幸いです。
【note】
https://note.mu/ogataka
【Twitter】
https://twitter.com/dancehakase
ここまでお読み頂き誠にありがとうございました。
【その他 補足事項】次回以降のnoteでは、回帰分析の係数の推定にバイアスをかける原因などについて言及していきながら、マーケティングの実務への活かし方を具体的に紹介していく予定です。なお、本noteで紹介した分析事例は拙書の演習データとしては紹介していません。(拙書ではアルコール飲料と通販の模擬事例など紹介)また、拙書の付録Excelは分析に使用する標本サイズを118(週)として時系列データ解析を行うことを想定したものとなっております。また、付録Excelのプログラムコードはロックをかけており標本サイズは変更できません。本noteでは付録Excelのプログラムを変えて分析期間を変えて標本サイズを59(日)として分析しています。
【告知】
(2019年10月4日更新) 第2回のnoteを公開致しました。
追加情報(2023年12月23日更新)
マーケティング・アナリストとして、どんな価値を提供しているのか?紹介しております。