e5-mistral-7bを蒸留して中程度の大きさの埋め込みモデルを学習する

2023/12にintfloatからintfloat/e5-mistral-7b-instructという、7BのLLMを埋め込み用にファインチューニングしたモデルがリリースされました。
このモデルは日本語の評価でもかなり優秀ですが、通常使われる埋め込みモデルと比べモデルサイズが大きく、使えるシーンは限られます。
使い勝手を向上させるために、もう少し小さいモデルに蒸留ができるかを試しました。
今回は同じ埋め込み次元を持つ1.9bのモデルへの蒸留を試しました。
STS関連のタスクは成功したものの、検索タスク(MIRACL)の評価が元モデルほど良くならず、モデルサイズに見合った精度とは言えない結果です。
表の一番上の行が今回蒸留したモデルです。
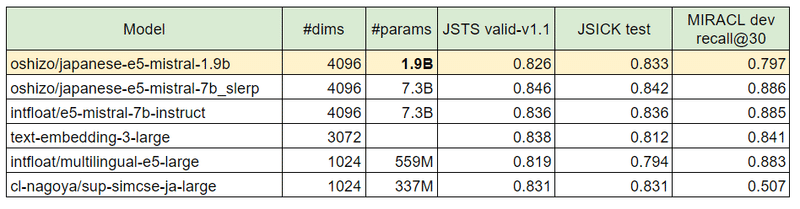
埋め込み次元、パラメタ数、タスクの評価結果
https://github.com/oshizo/JapaneseEmbeddingEval
作成したモデルはここで公開しました。
学習手順
Student Modelの作成
Studentモデルとしてはe5-mistral-7b-instructを縮小したものを使います。
縮小の仕方はいろいろありえますが、今回は32レイヤのMistral-7Bを8レイヤに潰しました。
以下の図のように、レイヤ0, 8, 16, 24の平均がレイヤ0になり、レイヤ1, 9, 17, 25の平均がレイヤ1になるような形です。
これで7.3Bのパラメタ数が1.9Bになりました。
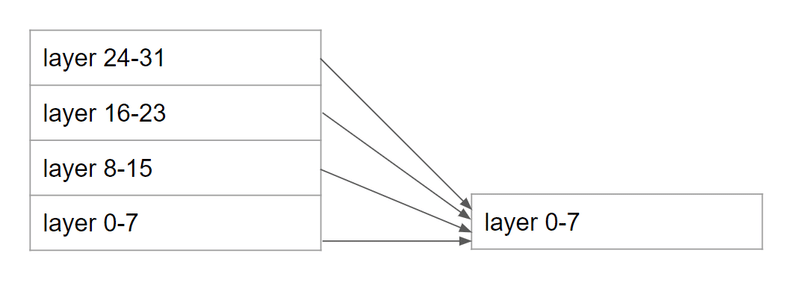
mergekitを使って、以下のような設定でlinear mergeしました
slices:
- sources:
- model: japanese-e5-mistral-7b_slerp_with_lm_head
layer_range: [0, 8]
parameters:
weight: 0.25
- model: japanese-e5-mistral-7b_slerp_with_lm_head
layer_range: [8, 16]
parameters:
weight: 0.25
- model: japanese-e5-mistral-7b_slerp_with_lm_head
layer_range: [16, 24]
parameters:
weight: 0.25
- model: japanese-e5-mistral-7b_slerp_with_lm_head
layer_range: [24, 32]
parameters:
weight: 0.25
merge_method: linear
dtype: float16merge元のモデルはe5-mistralそのままではなく、stabilityai/japanese-stablelm-base-gamma-7bをマージしたoshizo/japanese-e5-mistral-7b_slerpを使っています。
学習データの作成とLossの定義
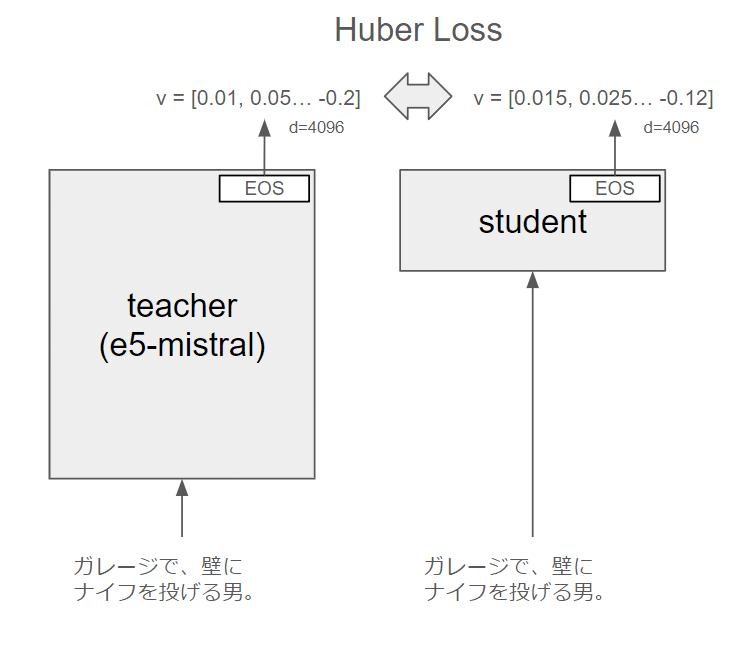
この方法であればモデルの埋め込み次元は変わらないので、教師モデルの埋め込みとの誤差を直接学習させることができます。今回はHuber Lossを使いました。
埋め込みモデルの蒸留に関する研究としては DistilCSE: Effective Knowledge Distillation For Contrastive Sentence Embeddings があります。
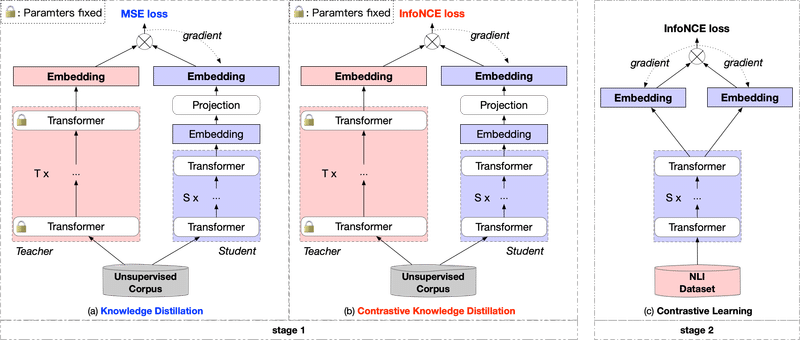
私の今回行った手法はこの図の(a)に当たります。この論文では、(a)の手法では精度劣化が発生するため、精度劣化の発生しない方法としてInfoNCE lossを使った2ステージの学習を提案しています。
学習データ
unicamp-dl/mmarco から日本語のquery, passageを30万件ずつ、jsnliから日本語の短文を20万件取得した計80万件を使用し、teacher modelで事前に埋め込みを計算しました。
この学習方法では文ペアは必要なく、ラベルなしの文の集合のみが必要なため、このデータセットを使うことに特別な意味はありません。
学習中のLoss、Metricの変化
左端がモデルを縮小した直後の数値ですが、MIRACLEのRecall@30は0.1未満になっており、元のモデルの能力はかなり失われてしまっているようです。
Train Loss(青)と各データの評価指標は相関しているように見えますが、MIRACL(紫)は紫の点線で描画している蒸留元モデルの評価値と、学習中のモデルの数値との乖離が大きく、これ以上データを増やして学習しても蒸留元モデルと近い値にはならなそうに見えます。

その他細かい話
ハイパーパラメータ
今回の学習はLoRAを使わず、フルパラメタチューニングを実施しました。
2xRTX3090の環境で、fp16=Falseの32bit trainingで大体VRAM42G程度を消費し、5it/sec前後の処理速度でした。800k steps実施したので、2日程度かかっています。
batch size=1, warmup_ratio=0.01, lr_scheduler_type="cosine"
学習率は3種類試し、2e-6を採用しました。
以下のグラフが3種類での学習率でのloss変化で、初動である程度差が見えていることが分かります。

緑:lr=5e-7, 青: lr=2e-6, 紫:lr=1e-5
学習コードの実装
Huber Lossで学習するための修正としては、モデルのサブクラスを作って、forwardで新しく定義したlossを返すように実装するだけで、他は通常の学習時と同じようにTrainerを使うことができます。
class MistralForEmbedding(MistralModel):
def forward(
self,
input_ids=None,
attention_mask=None,
labels=None,
**kwargs
):
# ベースモデルの出力を取得
outputs = super().forward(
input_ids=input_ids,
attention_mask=attention_mask,
**kwargs
)
# 最終層の隠れ状態を取得
last_hidden_states = outputs.last_hidden_state
# embeddingを取得
student_embeddings = self._get_embeddings(last_hidden_states, attention_mask)
# 損失を計算
loss = None
if labels is not None:
loss = nn.SmoothL1Loss()(100*student_embeddings, 100*labels.to(student_embeddings.device))
return (loss, outputs)
def _get_embeddings(self, last_hidden_states, attention_mask):
# embeddingを抽出
embeddings = last_token_pool(last_hidden_states, attention_mask)
# 正規化
embeddings = F.normalize(embeddings, p=2, dim=1)
return embeddingslast_token_pool関数はe5-mistralのモデルカードに書いてある実装そのままです。
embeddingを100倍してからlossを計算することで、lossの値が小さくなりすぎることを防いでいます。100倍せずに計算すると、lossの値が0.00400、0.00300、0.00200、0.00100の4つの値しか取らなくなりうまく学習できませんでした。
この記事が気に入ったらサポートをしてみませんか?