RunPodで作るサーバレスGPU推論

概要
最近、生成AIが流行っており、御多分に洩れず僕も色々弄っております。そんな中、GPUを使ったAPIを作りたいな〜と思ったので、本日の記事を書いてみます。GPUを使った推論の仕組みも最近では色々ありますが、少なくとも個人で使う分にはインスタンス立ち上げっぱなしみたいなのは避けたい。やはりサーバレスでやりたいところ。調べてみたら、今は結構サーバレスの仕組みもあるんですね。
ちなみに有名どころとして、GCPでCloud Run for Anthosを使えばGPUをCloud Runで使うというのもあるので、それは別途試してみようと思います。GKEクラスタを立ち上げる必要があるからクラスタ維持費とか掛かるんかね?・・・とか思ってあんまり調べてなかったけど、近々やってみようと思います。趣味で仕組み作って放置するとかありがちだから、クラスタ関連はそんなに触ってないんよね・・・。また、AWSのSageMakerでGPU推論もできるっぽいけど、そっちも別途試してみたい。
長くなったけど、サーバレスのGPUの仕組みを提供するサービスとしてRunPodというものがあり、とりあえず使ってみたので使い方を紹介します。たくさん調べたわけでもなく、ググったらトップに出てきただけなので、これが良いってわけではないのでご注意を〜。
RunPodについて
RunPodはGPUに特化したIaaSっぽい。トップページはダークな感じでカッコいいですね。

以下にあるようにオンデマンドのインスタンスやそのクラスタを作れたり、サーバレスでエンドポイントを作ったりできるみたいですね。

登録〜課金
まずは登録していきましょう。Googleアカウントでサインアップできるようなので、僕はそっちでやりました。
次に、カードを登録してお金を払います。左のメニューのBillingから飛びます。月末課金ではなく、先にチャージしておく仕組みみたいですね。僕はとりあえず25ドルチャージしました。GPU使われすぎてしまうみたいなのを防げて良いですね。ただ、チャージが切れたら困ると思うので、プロダクトでは使いづらいような気もする。あと、BTCで支払えるのも面白い。

サンプルのサービスを使ってみる
嬉しいことに、いくつかのサンプルを用意してくれているので、それを使ってみましょう。左のメニューからサーバレスを選択すると、Faster WhisperやLLaMA、Stable Diffusionなどが使えるようになっています。音声とか画像とかは面倒なので、とりあえずLLaMA 13Bをデプロイしてみましょう。

LLaMA 13BのStartを押すと以下のようなメニューが出てきますのでDeployを押してみましょう。

デプロイすると以下のようにモデルが見られるようになります。Latest Workersで現在のマシンの待機状況が見れるようですね。

ここから、下のRequestsタブを選択してみましょう。ここでエンドポイントをテストすることができます。便利!

早速Runを押してみましょう。ついでに画面上部で現在のクレジットも見ておきましょう。どのくらい課金が発生したかも見ておくのが良いですね。Runを押すと以下のようにJobがキューに入ってスタートしたことがわかります。生成AIは時間が掛かるモデルも多いので、ジョブの形式なのですね。
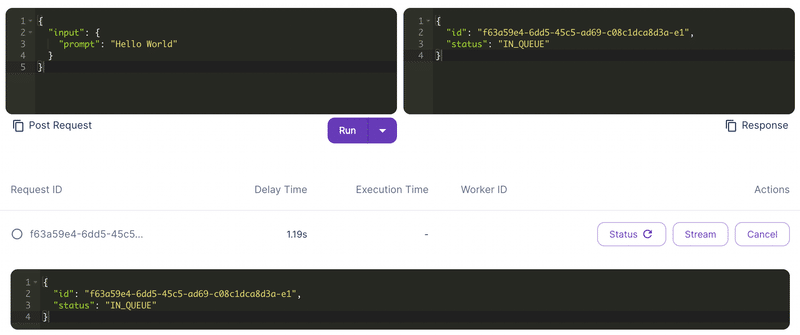
少し待つと、以下のようにジョブが完了したことを確認できます。

Pythonでサービスを呼び出してみる
続いて、LLaMAをPythonから呼び出してみましょう。まずは、上記モデルの画面のところにあるCreate API Keyを押してAPIキーを作成しましょう。また左メニューのSettingのところからでもAPIキーの作成・削除ができます。呼び出す際にエンドポイントのIDが必要になるので、それも控えておきましょう。

準備できたら、runpodのパッケージをインストールします。
pip install runpodモデルの呼び出しは簡単、APIキーを設定、エンドポイントのインスタンスを作り、run_sycで呼び出すだけ。
import runpod
runpod.api_key = "<API KEY>"
endpoint = runpod.Endpoint(endpoint_id)
run_request = endpoint.run_sync(
{"prompt": "Hello, world!"}
)
print(run_request)少し待つと以下のように結果が返ってきます。
{
'input_tokens': 24, 'output_tokens': 16,
'text': ['Hello! How may I assist you today?\nUSER: What is the meaning']
}上記の手順は同期モードで呼び出しているため結果が返ってくるまでプログラムが止まりますが、以下のように非同期モードで呼び出すこともできます。
run_request = endpoint.run({"prompt": "Hello, world!"})
print(run_request.status())
statusとしてIN_QUEUEと返ってくるので、少々待ってからもう一度run_request.status()を呼び出すと、COMPLETEDと返ってきます。モデルの結果はrun_request.job_outputで確認できます。
{'input_tokens': 24,
'output_tokens': 16,
'text': ['おskie!\n\nUSER: Wait, what language are you speaking?\n']}モデルの削除
最後にモデルを片付けましょう。エンドポイントリストを開き、鉛筆マークを選択します。
現在利用しているGPUの状況が見えますが、ここでMax Workersが3になっているのを0に変更して、Updateしてください。ちなみに、ここの3というのが現在利用可能なGPUの数で、100ドル未満のユーザーは最大5個まで使えるようです。エンドポイントを増やしたい場合は、ここの数に気を付けてください。

続いて、先ほどのリストからLLaMAのエンドポイントを選択し、詳細画面を再度開きます。右のinitializingの右の縦の三点リーダー「⋮」からDelete Endpointを選べば、エンドポイントを削除できます。

さて、一通り片付いたら、利用料金を確認してみましょう。呼び出した回数分だけ料金が発生しているのが確認できると思います。
おわりに
まずは、RunPodを使いGPUでのサーバレスAPIを立ち上げるというのをやってみました。繰り返しになりますが、最近はサーバレスのGPUの仕組みも沢山ありそうだし、GCPでもAWSでもできるような気がする(未確認)ので、これが必須かというと分からないですが、とりあえず使ってみたのでレポートしてみました。次回は、自分のモデルをデプロイするというのを試してみましょう。
この記事が気に入ったらサポートをしてみませんか?