Self-Extendでfine-tuningせずに長文コンテキストを扱おう

概要
Self Extendという既存のLLMモデルをfine-tuningせずに長文を扱えるようになる手法が提案されました。LLMの学習において長文を扱うのは大変なので、後処理で長文が扱えるようになるのは有用そうに思います。早速いくつか既に実装されていたので、論文の簡単な解説、ソースコードのチェックと、実験をしてみましょう。
論文の簡単な解説
今回利用する論文は、「LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning」です。論文では、「Self-Extend」という新しい手法について紹介しています。Self-Extendは、事前学習された大規模言語モデル(LLM)のコンテキストウィンドウ(利用できる文章の長さ)を拡張することを目的としています。Self-Extendはfine-tuningを必要とせず、既存のLLMにそのまま適用できます。この手法では、RoPE(相対位置符号化)を用いたLLMに、推論時に特別な処理を加えることで、より長い文脈を理解できるようにします。
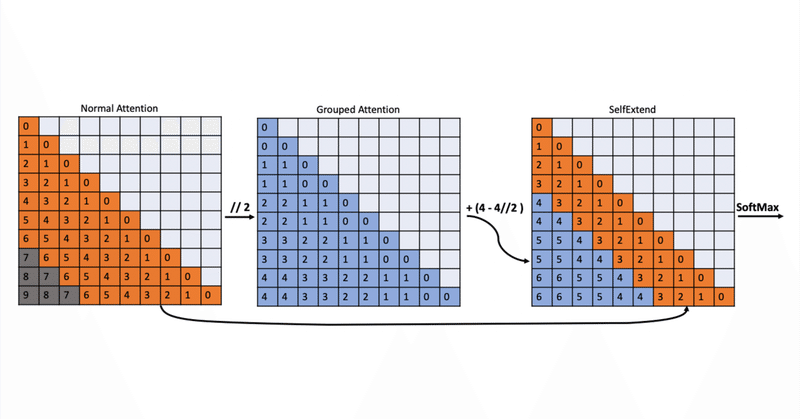
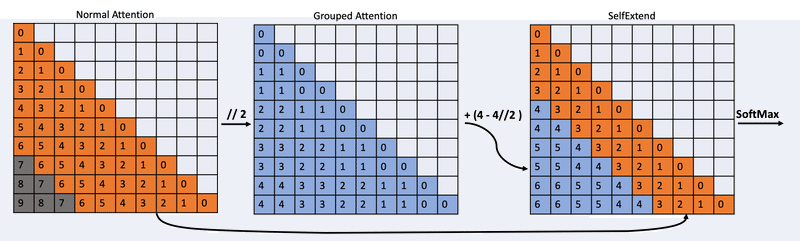
Self-Extendは、グループ化されたAttentionと通常のAttentionの組み合わせを用います。FLOOR操作を使用して、学習のときに利用していなかったような大きな相対位置を、モデルが扱えるような位置にマッピングします。下図の例では、入力シーケンスの長さが10、事前学習時のコンテキストウィンドウの長さが7である例を使用して説明しています。Self-Extendは、近傍のトークンに対しては通常の自己注意を用い、ウィンドウの外のトークンに対してはグループ化された自己注意を用いています。これにより、コンテキストウィンドウを7から10に拡張できることを示しています。
ソースコードについて
簡単に作れそうだったので途中まで自分で実装していたんですが、調べたら著者らの実装が見つかったので、若者らしくタイパ重視で、それを使うことにしましょう。
論文中の擬似コードは以下のようになっています。前半で通常通りにattentionの計算をしつつ、後半ではposの値を計算して、そちらのattentionの計算もします。最後の段落では、それらを合成する際に、先頭近傍は元のattention(ngb_attn)を、それ以外はg_attenを利用するようになっています。

実際のコードは長くなるので、割愛しながら紹介します。近傍のトークンは以下のように計算します。
def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
# The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
q_embed = (q * cos[:,:, -q.shape[2]:]) + (rotate_half(q) * sin[:,:, -q.shape[2]:])
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
neighbor_query_states, neighbor_key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids) # normal attention また、グループされたトークンは以下のように計算しています。
def apply_grouped_rotary_pos_emb(q, k, cos, sin, position_ids, g_size_1=8, g_size_2=1024):
# The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
position_ids_q = position_ids//g_size_1 + g_size_2 - g_size_2//g_size_1
position_ids_k = position_ids//g_size_1
cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
cos_q = cos[position_ids_q].unsqueeze(1) # [bs, 1, seq_len, dim]
sin_q = sin[position_ids_q].unsqueeze(1) # [bs, 1, seq_len, dim]
cos_k = cos[position_ids_k].unsqueeze(1) # [bs, 1, seq_len, dim]
sin_k = sin[position_ids_k].unsqueeze(1) # [bs, 1, seq_len, dim]
q_embed = (q * cos_q) + (rotate_half(q) * sin_q)
k_embed = (k * cos_k) + (rotate_half(k) * sin_k)
return q_embed, k_embed
# in case that, the smallest q position, g2-g2//g1 exceed the max position
_re_group_size_2 = 0 if position_ids.max() < group_size_2 else group_size_2
# grouped attention
group_query_states, group_key_states = apply_grouped_rotary_pos_emb(
query_states, key_states, cos, sin, position_ids, g_size_1=group_size_1, g_size_2=_re_group_size_2
)
それらを以下のように合成しています。実際は文の長さが短いときと分岐していたりするのでもう少し複雑ですが、概ね下記のコードになっています。
neighbor_attn_weights = torch.matmul(neighbor_query_states, neighbor_key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
group_attn_weights = torch.matmul(group_query_states, group_key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
group_attention_mask = torch.tril(torch.ones((q_len-group_size_2, kv_seq_len-group_size_2), device=group_attn_weights.device))
neighbor_attention_mask[group_size_2:, :-group_size_2] -= group_attention_mask
merged_attn_weights = torch.where(neighbor_attention_mask.bool(), neighbor_attn_weights, group_attn_weights) # replace the group attention with neighbor attention within the neighbor window.
merged_attn_weights = nn.functional.softmax(merged_attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_output = torch.matmul(merged_attn_weights, value_states)これをtransoformersのライブラリで利用できるように、以下のようにメソッドを置き換えることをやっています。setattrでメソッド入れ替えてるのか、中々の力技だ笑
def modify_method_of_instance(instance, target_class_name, target_method_name, new_method, visited_instances=None):
...省略...
if instance.__class__.__name__ == target_class_name:
bond_method = MethodType(new_method, instance)
setattr(instance, target_method_name, bond_method)
else:
# モデルのレイヤーを再帰的に探索
...省略...
original_llama_forward = LlamaAttention.forward
self_extend_forward = partial(
LlamaSE.self_extend_forward, group_size_1=8, group_size_2=1024
)
modify_method_of_instance(
model, "LlamaAttention", "forward", original_llama_forward
)実験について
パスキーを書いた長文をプロンプトに入れ、それを回答できるかをテストします。実験に利用したコードは以下のLanguage/17_SelfExtend.ipynbになります。ColabのA100で動作を確認しました。
LongLMの著者リポジトリではTinyLlamaを使っていましたが、Llama2が利用できる方が実用性が高いので、load_in_4bitにして実験してみましょう。
データについては以下のようになっています。長文のなかに、しれっとパスキーの89427が含まれています。
There is an important info hidden inside a lot of irrelevant text.
Find it and memorize it. I will quiz you about the important information there.
The grass is green. The sky is blue. The sun is yellow.
...省略...
There and back again.
The pass key is 89427. Remember it. 89427 is the pass key.
The grass is green.
...省略... さて、これを見つけるためのソースコードは以下のようになります。
original_llama_forward = LlamaAttention.forward
self_extend_forward = partial(LlamaSE.self_extend_forward, group_size_1=8, group_size_2=1024)
model_path = 'meta-llama/Llama-2-7b-chat-hf'
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
load_in_4bit=True,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
model.eval()
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
modify_method_of_instance(model, "LlamaAttention", "forward", original_llama_forward)
tokens = model.generate(input_ids.to(model.device), max_new_tokens=6)結果として、元のLlamaとSelf-Extendを比較すると以下のようになりました。以下が実際に出力した結果です。Llamaの方は、…..と回答出来ていないのに対し、SelfExtendではキーを出力できました。
Llama2: [What is the pass key? The pass key is ......]
SelfExtend: [What is the pass key? The pass key is 89427.]おわりに
今回は、LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuningという技術について、簡単な解説と実際に動かしてみてレポートしました。この技術を使うことで学習済みのモデルを再学習せずとも長文を扱えるようになります。モデルを作る・使う際に長文を扱うのが容易になるのは嬉しいですね。
この記事が気に入ったらサポートをしてみませんか?