
統計学的仮説検定の考え方

先に上記の記事を読んでください。
データサイエンスが流行っている。
データサイエンスで必要な知識が、「統計学的仮説検定の考え方」であろう。
A君とB君は、大学の囲碁サークルに所属している。今度行われる全国大会では、大学代表として2人のうちどちらか1人を送り込むことになった。どちらか強いほうを選ばなくてはいけない。
この例において、どちらを代表とすればよいか?
なお、これまでの2人の対戦成績は、15戦中、A君の12勝3敗である。
【統計学的検定の手順】
①仮説を設定する
「A君とB君の実力は五分五分である(差がない)」
⇒本来主張したいこととは反対の内容の仮説(帰無仮説)を立てる。
②統計的仮説検定に用いられる標本統計量を選択する
「15回の対局におけるA君の勝利数」
※この場合の標本は「15回の対局結果」
③仮説が間違っているか正しいかの判断の基準になる確率(有意水準)を設定する
心理学では有意水準を5%とすることが多い。
⇒「2人の実力に差がない」という仮説のもとで,5%以下の確率でしか起こらないような極端な勝敗差がついたときに,先の帰無仮説が間違っていると判断する。
④実際のデータから標本統計量の数値を求める
「15回対局したら,A君が12勝した」
⑤最初に定めた仮説が間違っているか正しいかを判断する
確率分布からA君の勝利数が12となる確率は、0.0139<0.05(有意水準)
⇒最初の仮説「A君とB君の実力は五分五分である」は間違っていると判断する。
【帰無仮説と対立仮説】
帰無仮説(null hypothesis):統計学的分析で否定する(棄却する)ことを前提として立てられる仮説
対立仮説(alternative hypothesis):帰無仮説が棄却されたときに採択される仮説
両側(対立)仮説(two-tailed hypothesis):方向性を仮定しない対立仮説
例)「AとBには差がある」→「A>B」でも「A<B」でもどちらでも構わない
片側(対立)仮説(one-tailed hypothesis):方向性を仮定する対立仮説
例)「AのほうがBよりも強い」→「A>B」のみを考え,逆方向の「A<B」は考えない
【両側検定と片側検定】
両側検定(two-tailed testまたはtwo-sided test):対立仮説に両側仮説を用いる検定⇒検定統計量の標本分布の両すそ部分を棄却域とする検定
片側検定(one-tailed testまたはone-sided test):対立仮説に片側検定を用いる検定⇒検定統計量の右または左の片すそだけを棄却域とする検定
統計的仮説検定では設定される仮説は帰無仮説と対立仮説の2つだけ。
互いに背反する2つの仮説のうち,どちらかを採択する。
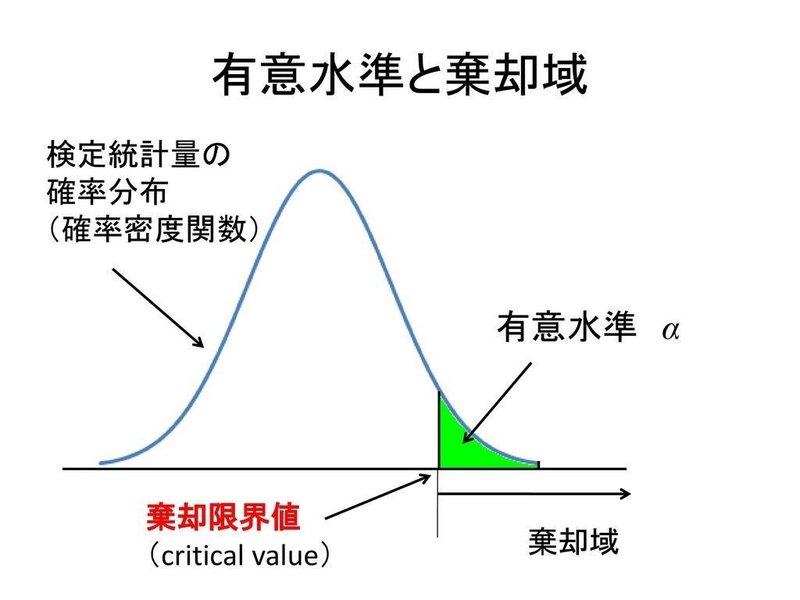
【有意水準】
・有意水準(significance level):帰無仮説を棄却し、対立仮説を採択するかどうかを決定するときに、どの程度低い確率の結果が示されたら帰無仮説を棄却するかということを判断する基準(αで表される)
・棄却域(rejection region):帰無仮説のもとでの標本分布におけるすそ野の部分で,その確率がαとなる領域→求めた統計量がこの領域に入ったら,帰無仮説を棄却する。
・棄却限界値(critical value):データから計算された統計量がいくら以上(または以下)であれば、帰無仮説を棄却し対立仮説を採択するかという境目になる値
【検定結果の報告】
・有意差がある
「差がない」という帰無仮説のもとで、偶然には起こりえないようなデータが得られた→帰無仮説を棄却し,「差がある」という対立仮説を採択
※この判断の結果を統計的に意味のある差があるということで「有意差がある」という。
・有意差がない
帰無仮説のもとでも,確率的に生じうる,それほど極端ではないデータが得られた→帰無仮説を棄却できない(帰無仮説を採択)
※この判断の結果を統計的に意味のある差がないということで「有意差がない」という。
【統計学的仮説検定における誤り】
統計学的検定では帰無仮説が誤りであるか否かを確率論的に推測し判断する。
そのため、次の2つの誤りが生じる危険性が伴っている。
・第1種の誤り(type Ⅰ error):本当は帰無仮説が正しい(差がない)にもかかわらず、それを棄却してしまう(差があると判断してしまう)誤り
・第2種の誤り(type Ⅱ error):本当は対立仮説が正しい(帰無仮説が誤りであり,差がある)にもかかわらず、それを採択しない(帰無仮説を棄却せず、差があると判断しない)誤り。
・危険率(p値):第1種の誤りを犯す確率(α)
⇒第1種の誤りを犯す危険性は有意水準の分だけ存在するため、有意水準と同じことを意味する。
・検定力(検出力):誤りである帰無仮説を,正しく棄却できる確率。
⇒第2種の誤りを犯す確率βを用いて、1-βで表せる。

Q.第1種の誤りを起こさないためにはどうすればよい?
A.第1種の誤りが生じる可能性イコール有意水準(α)なので、有意水準を5%から1%や0.1%と低く設定すれば良い。ただし、αとβには、一方が小さくなると他方が大きくなるという関係があるため、有意水準(α)を低くすると、βが大きくなり、結果的に検定力(1-β)が下がってしまいます。
Q.第2種の誤りを起こさないためにはどうすればよい?
A.
①標本サイズを大きくする→実施者の負担は大きくなりますが,現実的な方法としては有効
②有意水準(α)を大きく設定する→タイプⅡエラーが起こる可能性は低くなるが、タイプⅠエラーを起こす可能性が大きくなる。
③両側検定ではなく片側検定にする→ただし、片側検定を行う場合は対立仮説に方向性が含まれるため、片側仮説を設定する際に事前に根拠がない限り使えない。
心理学の調査では、統計的仮説検定を行う場合、「タイプⅠエラー」が起こる可能性(有意水準)を一定の小ささ(5%)に抑え、かつ「タイプⅡエラー」の起こる可能性も小さくするために、ある程度多くの人数を対象として行うことが現実的には多い。
この記事が気に入ったらサポートをしてみませんか?