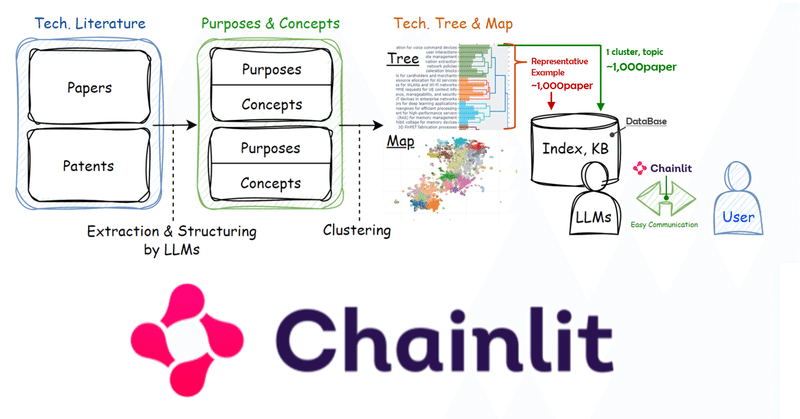
[UI]Chainlitで専門家AI_Local-LLM+Langchain+ChromaDB

LLMのUIにはtext-generation-webuiをはじめ様々なものがありますが、今回はChainlit(GitHub)に下記の記事で作成したDB(Langchain+ChromaDB)を使ってLocal-LLM(Starling-LM-7B-alpha)に回答してもらうChat-UIを作成します。

ほかのユーザーに使用してもらう際に、UIはユーザーの認知容易性の面でメリットがあります。またLangchainとChainlitはどちらもWinPython内で実装が可能で、配布の際に環境構築を伴わずに使用してもらうことができる点もメリットかもしれません。
0. 環境
OS:Windows
CPU:Intel(R) Core i9-13900KF
RAM:128GB
GPU:RTX 4090
1. Chainlit の設定pyファイル
LLMのmodelはStarling-LM-7B-alphaを使用、txt_pathに冒頭の記事で作成したDBの保存場所を指定、DBを作成したときに使用したembeddingのモデルも指定していします。
下記のコードを app.py などの名称で作成します。
import torch
from transformers import pipeline
from langchain.llms import HuggingFacePipeline
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain.chains import RetrievalQA
from langchain.vectorstores import Chroma
import chainlit as cl
#load the LLM
def load_llm():
pipe = pipeline("text-generation", model="berkeley-nest/Starling-LM-7B-alpha", torch_dtype=torch.bfloat16,
device_map="auto", max_new_tokens=512,
repetition_penalty=1.15
)
llm = HuggingFacePipeline(pipeline=pipe)
return llm
def retrieval_qa_chain(llm,vectordb):
retriever = vectordb.as_retriever(search_kwargs={"k": 5})
qa_chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="map_reduce",
retriever=retriever,
return_source_documents=True
)
return qa_chain
def qa_bot():
model_name = "BAAI/bge-large-en-v1.5"
encode_kwargs = {'normalize_embeddings': True}
embedding_function = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs={'device': 'cuda'},
encode_kwargs=encode_kwargs
)
llm=load_llm()
txt_path = r".\3D FinFET fabrication process"
DB_PATH = f'{txt_path}/vdb'
vectordb = Chroma(persist_directory=DB_PATH, embedding_function=embedding_function)
qa = retrieval_qa_chain(llm,vectordb)
return qa
@cl.on_chat_start
async def start():
chain=qa_bot()
msg=cl.Message(content="Firing up the research info bot...")
await msg.send()
msg.content= "Hi, welcome to research info bot. What is your query?"
await msg.update()
cl.user_session.set("chain",chain)
@cl.on_message
async def main(message):
chain=cl.user_session.get("chain")
cb = cl.AsyncLangchainCallbackHandler(
stream_final_answer=True,
answer_prefix_tokens=["FINAL", "ANSWER"]
)
cb.answer_reached=True
# res=await chain.acall(message, callbacks=[cb])
res=await chain.acall(message.content, callbacks=[cb])
print(f"response: {res}")
answer=res["result"]
answer=answer.replace(".",".\n")
sources=res["source_documents"]
if sources:
answer+=f"\nSources: "+str(str(sources))
else:
answer+=f"\nNo Sources found"
await cl.Message(content=answer).send() 2. Chainlitでpyファイルを実行
chainlit run app.py3. UI
下記のようにUI上で質疑が可能です。
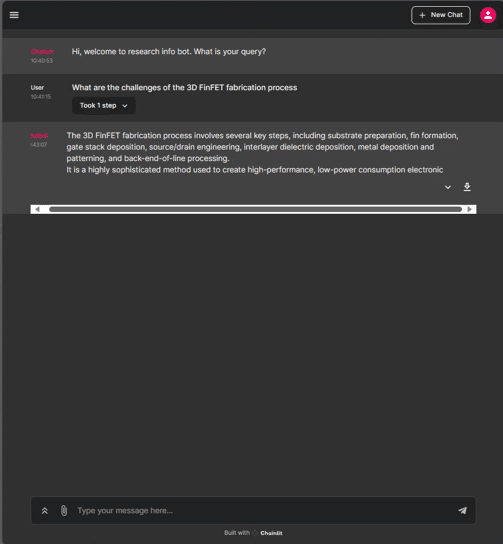
"Took 1 step" のようにクリック箇所が表示されるので、そちらからMap Reduceの過程を確認することができます。
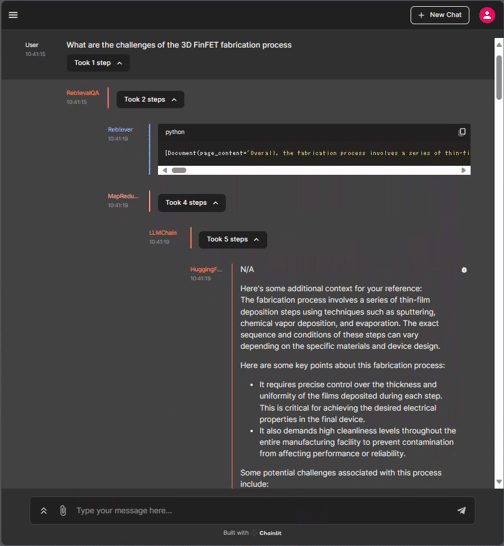
RetrievalQAWithSourcesChainを使用する場合は下記の通りです。
.pyファイル
import torch
from transformers import pipeline
from langchain.llms import HuggingFacePipeline
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain import hub
from langchain.chains import RetrievalQA
from langchain.chains import RetrievalQAWithSourcesChain
from langchain import PromptTemplate
from langchain.vectorstores import Chroma
import chainlit as cl
#load the LLM
def load_llm():
pipe = pipeline("text-generation", model="berkeley-nest/Starling-LM-7B-alpha", torch_dtype=torch.bfloat16,
device_map="auto", max_new_tokens=512,
repetition_penalty=1.15
)
llm = HuggingFacePipeline(pipeline=pipe)
return llm
def retrieval_qa_chain(llm,vectordb):
retriever = vectordb.as_retriever(search_kwargs={"k": 5})
template = """
{summaries}
{question}
"""
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={
"prompt": PromptTemplate(
template=template,
input_variables=["summaries", "question"],
),
},
)
return qa_chain
def qa_bot():
model_name = "BAAI/bge-large-en-v1.5"
encode_kwargs = {'normalize_embeddings': True}
embedding_function = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs={'device': 'cuda'},
encode_kwargs=encode_kwargs
)
llm=load_llm()
txt_path = r"C:\Users\yoshi\Documents\Patent\Semiconductor\topic folder\3D FinFET fabrication process"
DB_PATH = f'{txt_path}/vdb'
vectordb = Chroma(persist_directory=DB_PATH, embedding_function=embedding_function)
qa = retrieval_qa_chain(llm,vectordb)
return qa
@cl.on_chat_start
async def start():
chain=qa_bot()
msg=cl.Message(content="Firing up the research info bot...")
await msg.send()
msg.content= "Hi, welcome to research info bot. What is your query?"
await msg.update()
cl.user_session.set("chain",chain)
@cl.on_message
async def main(message):
chain=cl.user_session.get("chain")
cb = cl.AsyncLangchainCallbackHandler(
stream_final_answer=True,
answer_prefix_tokens=["FINAL", "ANSWER"]
)
cb.answer_reached=True
# res=await chain.acall(message, callbacks=[cb])
res=await chain.acall(message.content, callbacks=[cb])
print(f"response: {res}")
answer=res['answer']
answer=answer.replace(".",".\n")
sources=res["source_documents"]
if sources:
answer+=f"\nSources: "+str(str(sources))
else:
answer+=f"\nNo Sources found"
await cl.Message(content=answer).send() 一応UI画面
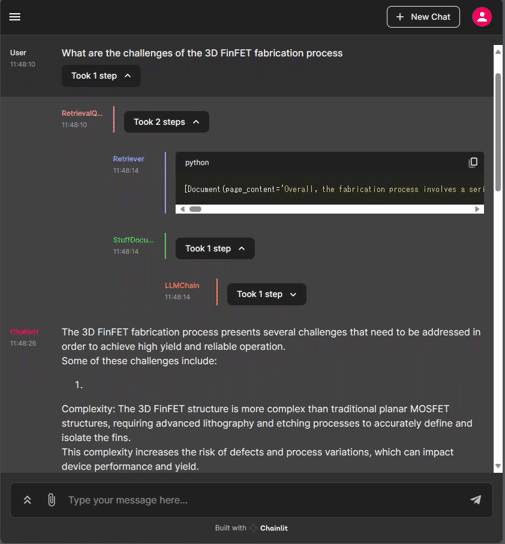
4. まとめ
手軽にLlamaindexやLangchainを組み込めるChainlitは本当に素敵です。
この記事が気に入ったらサポートをしてみませんか?