Karasu and Qarasu: The new top Japanese Chatbots


In this blog post, we introduce Karasu and Qarasu - state of the art open-source Japanese chatbots.
Try chatting to our best model, Qarasu, here (https://lightblue-qarasu.serveo.net/)!
These models are able to chat in Japanese to a higher level than all other available LLMs of a similar size, as rated by a popular conversation benchmark. In this article, we describe the design and engineering process behind building them.
Base model
We choose two separate models to train on. First, we trained on the Shisa (augmxnt/shisa-7b-v1) model made available by Augmxnt, due to its already high score on the Japanese MT-Bench benchmark and due to the fact that it has a Japanese-specific tokenizer, meaning that tokenization and inference can be multiple times more efficient (and thus faster) than other open source models.
We also chose to do some training using Qwen (Qwen/Qwen-14B-Chat) which is another very high performing model on the Japanese MT-Bench benchmark.
Unstructured training data
We trained a Shisa model on roughly 7 billion tokens of mostly unstructured Japanese text. We chose the following data sources to use in our pre-training phase:
.lg.jp, .go.jp, .ac.jp domain webscrapes from the Japanese subset of CulturaX
English Ultrachat200K-gen
※ We included the Ultrachat dataset so that the model did not forget its already learned English and chat abilities. However, this made up less than 10% of our training tokens in this phase.
Training the 7 billion parameter Shisa on 7 billion tokens took ~60 hours on one instance of 16 A100 (40GB) GPUs with Deepspeed (stage 3 setting). We used Axolotl as our training harness due to its ease of use and support of multi-gpu training frameworks such as Deepspeed.
With this, we generated our pre-trained model, Karasu-7B.
Structured training data
As has been discussed by Augmxnt in their repo, we find that many available Japanese fine-tuning datasets (E.g. Dolly) have already been outmoded by better datasets when training English and Chinese LLMs. Therefore, we set out to create our own datasets which could improve the abilities of our own LLM.
We had three broad criteria that we wanted our datasets to excel in:
Topic relevancy - We wanted to train on datasets which are relevant to Japanese speakers. Upon manual inspection, many open-source Japanese fine-tuning datasets contain a large amount of prompts and answers about US- and European-centric topics. While prompts regarding Jim-Crow laws in the Southern states of the US is undoubtedly an important topic, we hypothesize that training on data closer to a Japanese speaker's everyday experience would lead to a more useful Japanese LLM. Therefore, we wanted to focus more on Japanese topics.
Language fidelity - Many open-source Japanese fine-tuning datasets are built up of either translated data or translation tasks. Datasets such as HH-RLHF, Dolly, and OASST are largely made up of data translated to Japanese from English. This can often lead to strange Japanese being produced (e.g. a native Japanese speaker would almost certainly not use 私はあなたに at the start of a prompt like this) and thus perhaps could limit the Japanese abilities of the resultant LLM. Therefore, we generate our data without translation and aim to generate as natural a Japanese dataset as possible.
Volume - The open source datasets which are both relevant to Japanese speakers and have been generated natively from Japanese remain quite small. The OASST dataset contains 48 native Japanese conversations and only 363 total back-and-forth messages, meaning that training on this data does not cover a wide variety of topics or showcase a wide range of language. Therefore, we set a goal of generating a dataset with hundreds of thousands of examples to train on.
We ended up generating three datasets with these criteria:
An RAG-based question answering dataset (~250K examples)
A category-based prompt-response dataset (~250K examples)
A Chain-of-Thought Orca-style dataset (~40K examples)
We will not be releasing these datasets publicly.
We supplemented this with the following open source datasets:
OASST (Japanese conversations only)
ShareGPT (Japanese conversations only)
Augmxnt (airoboros, slimorca, ultrafeedback, airoboros_ja_new only)
Our datasets were largely generated using the output of much larger LLMs, and so we found that multiple rows in the prompt-response dataset were refusals to reply (e.g. 申し訳ございませんが、LLMとしてその質問を対応できません). We tested training both with and without these refusals, and we denote the models that are trained without them with the "unleashed" suffix.
We also tested training on different mixes of datasets, training both with and without the Chain-of-Thought dataset. We found that training with this dataset did not have a very large effect on the output of the model. The models where the Chain-of-Thought dataset is included in training is denoted with the "plus" suffix.
In total, we trained our pre-trained Karasu-7B on the above datasets to make the following models:
karasu-7B-chat - Open source datasets + question answering datasets + prompt-response datasets
lightblue/karasu-7B-chat-plus - Open source datasets + question answering datasets + prompt-response datasets + chain-of-thought datasets
lightblue/karasu-7B-chat-plus-unleashed - Open source datasets + question answering datasets + prompt-response datasets (refusals removed) + chain-of-thought datasets
Finally, we decided to use our fine-tuning datasets on another model to see how it would fare. We chose to train on the Qwen/Qwen-14B-Chat model due to its high scores on the MT-Bench and JGLUE benchmarks.
We called this model Qarasu:
lightblue/qarasu-14B-chat-plus-unleashed - Qwen trained on open source datasets + question answering datasets + prompt-response datasets (refusals removed) + chain-of-thought datasets
Evaluation
We evaluated our models on the Japanese MT-Bench benchmark and also evaluated some of the most popular open-source and OpenAI models.
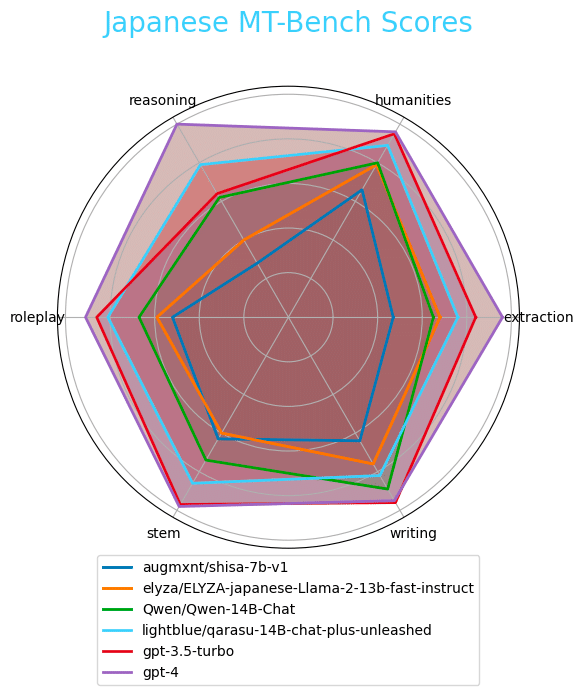
Full results:

However, benchmarks can mask the real story with LLMs, so please try our demo online here (https://lightblue-qarasu.serveo.net/).
Development team
This model was created by the natural language processing team at Lightblue KK in Tokyo.
If you have any questions or want to reach out to the developers of this model, feel free to contact Peter Devine at peter [at] lightblue-tech.com.
この記事が気に入ったらサポートをしてみませんか?