
PythonでスクレイピングするWebサイト(Web Scraper)を作ったよ

どうも初めまして、しょう(@K20Wh)と申します。
Pythonの案件探すのに、クラウドサービスをいろいろ見ていたら、スクレイピング案件がやはり多いことに気づきました。
なので、指定したURLから指定したキーワードが含まれているWebサイト作ったら、便利なんじゃね?ということで、スクレイピングを行うためのWebサイト(Web Scraper)を開発しました。
※当Webサイトを利用する場合には、自己責任でお願いいたします。Pythonの勉強の一環として活用してもらえると嬉しいです。
実際の動きは、以下のようになっています。
スクレイピングするwebアプリ、ほぼほぼ完成🙃 pic.twitter.com/IfKfozZnzM
— しょう@python×ブログ (@K20Wh) September 25, 2023
Webサイトの役割はただただスクレイピングをして、その結果をExcelに保存・ダウンロードするだけなので、デザインは一切いじっていません。
機能を十分果たしてくれれば、それでいいかなと思うので、デザインについては気が向いたらやろうと思います。
スクレイピングサイトの機能
当Webサイトの機能は非常に単純です。
指定したURLから指定したキーワードを指定したタグ内から抽出
指定したURLから内部リンクを探し出して、内部リンク先でも指定したキーワードを検索して抽出
電話番号やメールアドレスなどの固有のものに関しては、タグ指定をせずに抽出可能(キーワード欄に「電話番号」「メールアドレス」と入力すればOK)
抽出結果は自動的にExcelに変換して、ダウンロード
上記のことを当Webサイトでは行うことができます。
ちなみに、このnoteではPythonのソースコードも提示するので、電話番号やメールアドレス以外にも正規表現を使ってパターン登録をしておくと、従業員人数やJANコードなども検索・抽出することができます。
ただ、あまり複雑なWebサイトではタイムアウトになってしまうので、同期処理ではなく、非同期処理を実装したWebサイトが必要になります。
当Webサイトの活用
スクレイピング案件を受ける際のベースにしてもらえると、かなりスムーズにスクレイピングを行えると思います。
特にChatGPTに課金している場合、ファイルをアップロードして、「JANコードを抽出できるように修正して」「価格を取得できるようにして」「代表取締役の名前を抽出できるように修正して」などどリクエストをすれば、そのように修正をしてくれます。
スクレイピングの相場は以下の感じです

スクレイピングのベースはできているので、少し修正すれば、スクレイピング案件を結構いいペースで受注できるようになります。
WebサイトのURL
URLは上記です。
Renderを使用しているので、スリープ状態に入っていると、応答が遅いかもしれませんが、2-3分待って、再アクセスすると問題なく起動します。
Web Scraperの使い方の前にHTML構造の話
HTML(HyperText Markup Language)は、ウェブページを作成するための標準マークアップ言語です。HTMLでは、タグを使用してテキストやその他のコンテンツを構造化します。
1.<!DOCTYPE html>
<!DOCTYPE html>は、ドキュメントがHTML5で書かれていることをブラウザに伝える宣言です。これはHTML文書の最初の行として配置する必要があります。
2.<html>
このタグは、HTML文書のルート(最上位)要素
このタグの内部には、<head>タグと<body>タグが含まれます。
3. <head>
このタグの中には、文書のメタ情報(例:タイトル、文字セット、スタイルシートのリンクなど)が含まれます。
4. <title>
このタグは、文書のタイトルを指定します。これはブラウザのタイトルバーやページタブに表示されます。
5. <body>
このタグの中には、文書の主要なコンテンツ(テキスト、画像、動画、リンクなど)が含まれます。
6. <h1>, <h2>, ..., <h6>
これらのタグは、見出しを作成します。<h1>は最も重要な(最大の)見出しで、<h6>は最も重要でない(最小の)見出しです。
7. <p>
このタグは、段落を作成します。
8. <a>
このタグは、ハイパーリンクを作成します。href属性を使用して、リンク先を指定します。
9. <img>
このタグは、画像を埋め込みます。src属性を使用して、画像のURLを指定します。
10. <ul>, <ol>, <li>
<ul>(順序なしリスト)と<ol>(順序付きリスト)タグは、リストを作成します。
<li>タグは、リストの各項目を表します。
11. <div>
このタグは、文書のセクションまたはコンテナを作成します。主にCSSと組み合わせて使用されます。
12. <span>
このタグは、文書内の小さな部分(例えば、一部のテキスト)を囲むために使用されます。
HTMLの例
<!DOCTYPE html>
<html>
<head>
<title>私のウェブページ</title>
</head>
<body>
<h1>こんにちは、世界!</h1>
<p>これはウェブページです。</p>
<a href="https://www.example.com">ここ</a>でもっと学びましょう!
</body>
</html>この例では、HTML文書の基本構造と、いくつかの一般的なタグ(<title>, <h1>, <p>, <a>)を使用しています。
Web Scraperの使い方
スクレイピングを行うのは簡単です。
スクレイピングを行いたいサイトURLを入力し、検索したい単語を入力、検索するタグを指定して、スクレイピングを開始すれば、スクレイピング終了後に自動でExcelファイルがダウンロードされます。

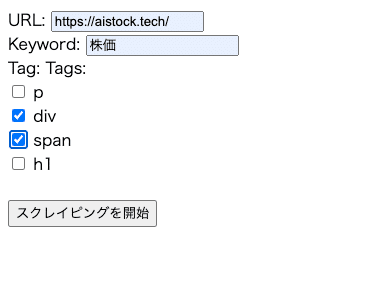
さらに、コード内に記載している「patterns」はキーワード欄に「電話番号」or「メールアドレス」と入力するだけで、タグを選択せずとも検索してくれるようになっています。
注意点として、正規表現を使っているので、正規表現に該当する情報は拾ってきてしまいます。
patterns = {
'電話番号': r'\(?\d{2,4}\)?[-.\s]?\d{2,4}[-.\s]?\d{2,4}',
'メールアドレス': r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b',
#ここに追加
}基本的には、pタグ、divタグ、spanタグを選択しておけば、該当のキーワードは拾ってこれるはずです。
一方で、箇条書きになっている項目については拾ってくることができないので、箇条書きされている内容も抽出したい場合には、コードを編集して<li>タグも抽出できるようにする必要があります。
また、冒頭でも述べましたが、複雑なWebサイトではタイムアウトになる可能性が高く、非同期処理を実装する必要があります。
実際、私が作成したサイトですら、タイムアウトになってしまいました。
Excelファイルの編集
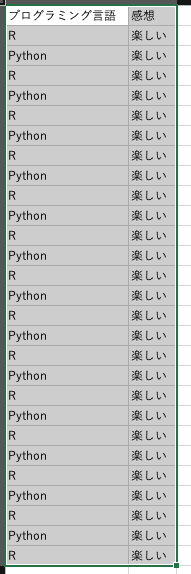
自動的にダウンロードされるExcelファイルは内容がタブっていることがほとんどです。
これは、内部リンクを辿ってキーワードを抽出しているので、一部仕方がない部分があります。
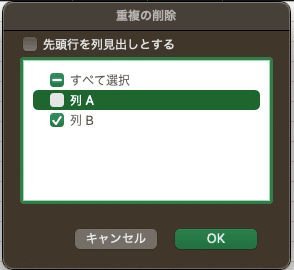
同一URLで同一内容を抽出したくない場合のコードも記載しておくので、内容のダブりを減らしたい場合には、そちらに変更をして下さい。
もしくはExcelの機能で、ダブりを削除することができるので、そちらを使うのもいいかもしれません。
Webサイトのコード提供
今回の構成は以下のようになっています。
/project
/templates
index.html
app.py
scraper.py
excel_output.pyコードを全てそのまま提供しますので、ローカル環境で動かすことができるはずです。
もし自分で編集して、デプロイしたい場合には、Renderがおすすめです。
それぞれのライブラリのバージョンが異なっているとエラーになる可能性もありますので、そこだけ気をつけてもらえればいいと思います。
なお、今回は以下のバージョンです。
requests ver.2.31.0
beautifulsoup4 ver.4.12.2
pandas ver.1.3.5
Flask ver.2.2.5
gunicorn ver.19.9.0
openpyxl ver.3.1.2
Python 3.9.16
index.html
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Web Scraper</title>
</head>
<body>
<form method="post">
<label for="url">URL:</label>
<input type="url" id="url" name="url" required><br>
<label for="keyword">Keyword:</label>
<input type="text" id="keyword" name="keyword" required><br>
<label for="tag">Tag:</label>
<label>Tags:</label><br>
<input type="checkbox" id="p" name="tag" value="p">
<label for="p">p</label><br>
<input type="checkbox" id="div" name="tag" value="div">
<label for="div">div</label><br>
<input type="checkbox" id="span" name="tag" value="span">
<label for="span">span</label><br>
<input type="checkbox" id="h1" name="tag" value="h1">
<label for="h1">h1</label><br>
<!-- 他のタグも追加可能 -->
</select><br>
<button type="submit">スクレイピングを開始</button>
</form>
{% if message %}
<p>{{ message }}</p>
{% endif %}
</body>
</html>app.py
from flask import Flask, render_template, request, send_from_directory
import os
from scraper import scrape_website
from excel_output import create_excel
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def index():
message = ""
if request.method == 'POST':
url = request.form['url']
keyword = request.form['keyword']
tag = request.form.getlist('tag') # タグはリストとして取得
results, message = scrape_website(url, keyword, tag)
if results:
filename = create_excel(results, url)
return send_from_directory(os.path.abspath("output"), filename, as_attachment=True)
return render_template('index.html', message=message)
if __name__ == '__main__':
app.run(debug=True)scraper.py
import requests
import re
from bs4 import BeautifulSoup
from urllib.parse import urljoin
def scrape_website(url, keyword, tag=None):
patterns = {
'電話番号': r'\(?\d{2,4}\)?[-.\s]?\d{2,4}[-.\s]?\d{2,4}',
'メールアドレス': r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b',
#ここに追加
}
def scrape_single_page(url, keyword, tag):
try:
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
if keyword in patterns:
text = soup.get_text()
pattern = patterns[keyword]
matches = re.findall(pattern, text)
return matches, ""
else:
if tag is None:
return None, "タグを指定してください"
sentences = []
elements = soup.find_all(tag)
for element in elements:
text = element.get_text()
sentences.extend(re.findall(r'[^。]*?{}[^。]*。'.format(re.escape(keyword)), text))
return sentences, ""
except requests.RequestException:
return None, "無効なURLです"
except Exception as e:
return None, str(e)
results, message = [], ""
# 最初に指定されたURLから抽出
main_results, main_message = scrape_single_page(url, keyword, tag)
if main_results:
results.extend([(url, result) for result in main_results])
# 内部リンクを探す
try:
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
links = [urljoin(url, link.get('href')) for link in soup.find_all('a', href=True)]
for link in links:
link_results, link_message = scrape_single_page(link, keyword, tag)
if link_results:
results.extend([(link, result) for result in link_results])
except requests.RequestException:
return None, "無効なURLです"
except Exception as e:
return None, str(e)
return results, messageexcel_output.py
import pandas as pd
import os
def create_excel(results, url):
df = pd.DataFrame(results, columns=['URL', 'Result'])
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
filename = "output.xlsx"
filepath = os.path.join(output_dir, filename)
df.to_excel(filepath, index=False)
return filenameExcelファイル内のダブりを減らすコード
こちらはexcel_output.pyの別コードになります。
import pandas as pd
import os
def create_excel(results, url):
# 結果をDataFrameにロード
df = pd.DataFrame(results, columns=['URL', 'Result'])
# 重複する行を削除
df = df.drop_duplicates()
# Excelファイルを出力ディレクトリに保存
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
filename = "output.xlsx"
filepath = os.path.join(output_dir, filename)
df.to_excel(filepath, index=False)
return filenameもしうまくいかないなどがあれば、SNSからDMしてもらえれば大丈夫です。
また、公式ラインも作成しておいたので、そちらから問い合わせをしていただいても大丈夫です。
また、FastAPIで非同期処理を実装したスクレイピングのコード・WebサイトURLが欲しい方は、公式ラインに本記事の感想メッセージを送っていただければ、プレゼントしますので、お気軽にメッセージを送って下さい。
最後に、記事のいいねとフォローしていただけると、今後の開発の気力になります!
よろしくお願いします\(^^)/
この記事が気に入ったらサポートをしてみませんか?