
サービスの目視チェックをヘッドレスブラウザで効率化した話

■ モチベーション
サービスを継続的に改善していく上で、バグを避けることはできません。そこで、バグが混入した時にそれにいち早く気付ける仕組みが必要になります。
Webサービス開発ではふつう、ユニットテストを書きます。一連のページ遷移(動線)をチェックするE2Eテストを書くこともあります。これらを用いることで、バグに簡単に気づくことが出来ます。
しかし、フロントエンドのエラーには微妙なページデザインの崩れなども含まれます。この場合、単にDOMの存在やページ遷移の可否をチェックするだけでは不十分です。
このようなエラーチェックに関しては、2018年になった今も、人が直接見なければ良し悪しがわかりづらいというやっかいな側面があります。かといって、主要なページを毎日手でチェックするのは非常に手間がかかってしまいます。
■ 自動でページのスクリーンショットを取る
そこで、ChromeをNodeから操作するライブラリであるpuppeteerを使い、サービスページのスクリーンショットをSlackに通知することで、人が簡単にCSS崩れやjsのレンダリングエラーをチェックできるツールを作りました。

具体的な動作フローは以下の通りです。
1. puppeteerを使ってURLのホワイトリストを巡回
2. PC/SPの2パターンでスクリーンショット撮影
3. サービス毎にスクリーンショットを一つにまとめ、Slackに投稿
4. このスクリプトをAWS EC2のcronで始業・終業頃に定期実行
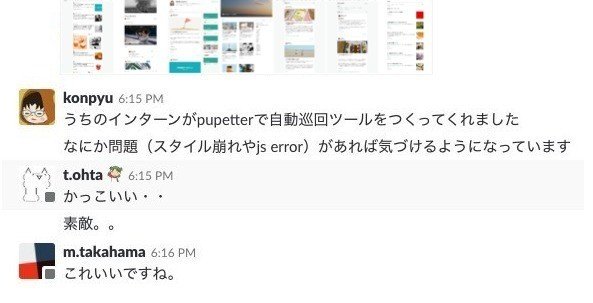
実際に動かしてみたところ、嬉しい感想をいただきました!
■ 工夫した点・苦労した点
・スクリーンショットを見やすく通知する
このようなツールをせっかく作っても、Slackでの見せ方によってはいつの間にか誰にも見てもらえなくなる可能性があります。この手の定期実行の通知はちゃんと見てもらえるための工夫が必要です。
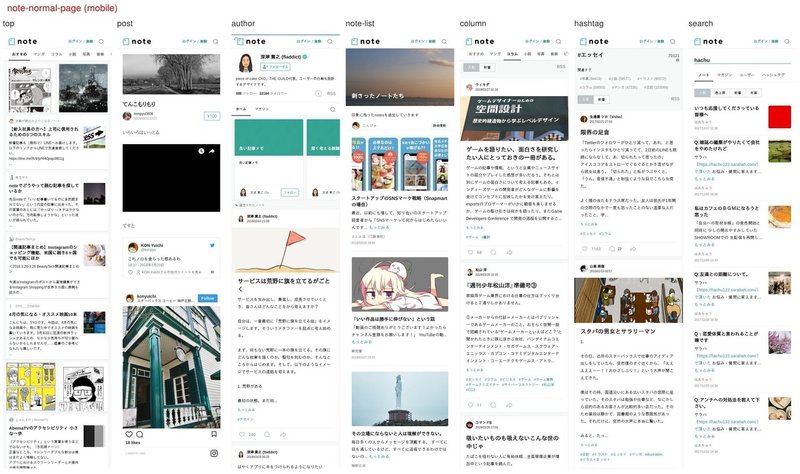
今回のケースでは、スクリーンショットを1画面ずつ連続投稿すると、ノイズになりやすく、また縦に長くなって流れてしまう危険性がありました。そこで、サービスごとに1枚の大きなキャンバスにまとめることで、ワンクリックでチェックできるようにしました。
・ページのロード判定
AngularなどのJavaScriptで動的にDOMを書き換えるようなサービスの場合、ページのロードがいつ完全に終了したのかを判定するのが難しいという問題がありました。puppeteerのページを訪問する関数には、loadイベントやDOMContentLoadedイベントが発火されるまで待つオプションに加え、直近の500ミリ秒間でネットワークコネクションが0本(または2本)の場合に終了と判定するものがあります。
今回の私のケースではいずれを用いてもうまくいかなかったのですが、実行速度が求められないケースのため、3秒間スリープするという策をとりました。愚直ですが、確実です。
・Nodeでの処理の同期実行
今回、ヘッドレスブラウザを操作するライブラリとして安直にpuppeteerを選んでしまったのですが、自分は普段全くNodeを触らないため、同期的に処理を行いたい場面で思うようにできずに時間を費やしてしまいました。例えば、複数のスクリーンショットを1つのキャンバスにまとめるために、
1. 大きなキャンバスを用意
2. 1番目の画像をキャンバスに貼り、上書き保存
3. 2番目の画像をキャンバスに貼り、上書き保存
...
のような処理を行いましたが、これは同期的に行わなければ思い通りの結果が得られません。
画像処理にはNodeのimagemagickのライブラリを使ったのですが、公式のExampleは以下のようにコールバック関数を渡すように設計されているため、繰り返し処理を行うとネストが深くなったり、配列の要素を順に実行する処理の記述が難しくなります。
var im = require('imagemagick');
im.readMetadata('kittens.jpg', function(err, metadata){
if (err) throw err;
console.log('Shot at '+metadata.exif.dateTimeOriginal);
})今回は最新のNodeを使うことができたため、この問題に対しては以下のようなimagemagickを実行するPromiseを返す関数を用意し、awaitすることで対処しました。
function executeImagemagick(cmd) {
return new Promise((resolve, reject) => {
im.convert(cmd, (err, stdout) => {
if (err) {
reject(err);
}
resolve();
});
});
}ただ、今回はほとんどが同期的に実行してほしい処理であったため、Nodeに慣れていない方は素直にPython/RubyなどからSeleniumを使うのが良いと思いました。
■ 今後改善したいこと
・ログインが必要なページへの対応
今回は一般ページのみをスクレイピングの対象としていましたが、会員情報の画面の撮影にはログインが必要になります。そのためにはログインの自動化・セッションの維持が必要になりますが、今後やってみたいです。
・E2Eテスト
前項の延長とも言えますが、会員登録やログインなどの一連のページ遷移をテスト(E2Eテスト)することもできますね。
・訪問ページリストの自動生成
現在はスクリーンショットを取りたいページは手動で選んでjsonに書き出していますが、サービスのURLを与えると自動でTOPページや記事ページ、ユーザーページなどを選んでくれると非常に楽です。具体的にはサイトマップを基にしたり、クローリングを行うことでページリストを生成することが考えられます。
この記事が気に入ったらサポートをしてみませんか?