生成AIを学び問う〜2.テクノロジーの視点

第1回目は、サイエンスの視点から、生成AIは人間にどれだけ近づいたのかを学びました。
今回は、テクノロジーの視点から、生成AIの基礎から応用までを、学び問います。生成AIを活用したサービスが乱立する中で、幹となる流れを紹介します。
生成AIはどんな学習をしている?
自律性を持たせたら進化する?
AI同士を協力させたら進化する?
そんな疑問に答えていきます。
はじめに
SoftBankの孫さんは、東京大学のシンポジウムに参加して、AIの未来についてこんな発言をされました。
考えてみてください。平均的な人間と、最も賢い魚、どっちが賢いか?どんなにトレーニングした魚でも、平均的な人間の脳細胞の活動には絶対勝てない。ちなみに、人間の脳細胞の数は、魚の脳細胞の数の約1万倍です。
基本的に、脳細胞の数とその生命体が持っている知恵や知識は、おおむね比例すると思います。
いまのGPT-4は、人間の平均レベルには達している。いまから10年後に、AIの脳細胞の数は、100万倍に増えると思います。さらにその10年後には、1兆倍にいくでしょう。1兆倍の差が付いたら、もはや、AIは人間より賢いのかとか、どの分野で人間はAIより賢いのかとか、そういう議論が虚しくなるくらい、圧倒的な差になる。
確かに、10年・20年先がどんな社会になっているか、まったく予想がつきません。しかし、生成AIの技術は、現時点でもかなり優秀ですし、日々進化しています。そして、ある疑問が浮かびました。
いまの生成AIの技術で、どこまで進化するだろうか?
そこで、最新の開発状況を学びながら、生成AIの進化に迫ってみます。
1. アシスタント:ネットの情報
インターネットにある大量の情報をAIに学ばせると、どうなるだろうか?
そんな素朴な思いを形にしたのが、GPTに代表される大規模言語モデル (Large Language Model: LLM) であり、画像なども含めた基盤モデル (Foundation Model)です。これらのAIモデルを簡易的に利用するユーザーインタフェースがChatGPT / Google Bard / Adobe Fireflyなどであり、より利用目的に合わせたアプリケーションにしたのがMicrosoft Copilot / Google Duet AIなどです。
ユーザーの一部のタスクを手伝うことを目的としており、ここでは「アシスタント」と呼びます。
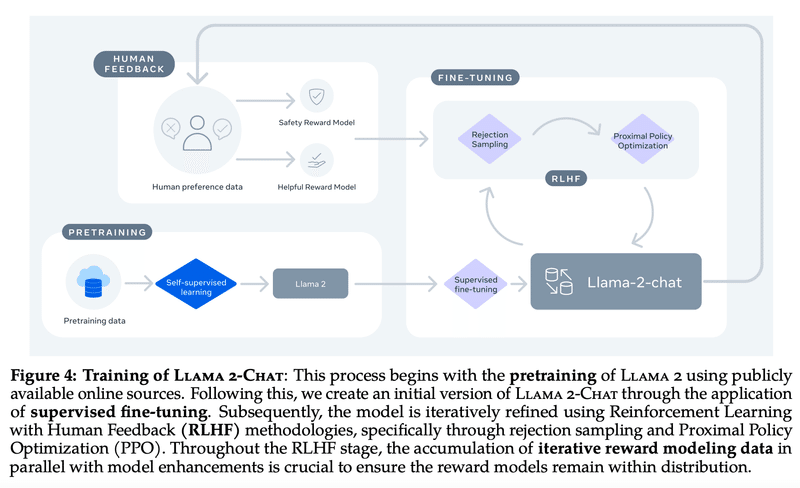
このアシスタントの実現において、インターネットにある大量の情報をAIに学ばせるには、どんな技術上の工夫があるでしょうか?残念ながら、ChatGPTは論文として公開されていないため、技術上の詳細が分かりません。そこで、ChatGPTと同レベルの能力持つと言われる、FacebookのMeta社が開発したオープンソースLlama 2で学んでみます。
技術上の工夫は、大きく3つあります。
事前学習 (Pretraining)
教師ありファインチューニング (SFT)
人間のフィードバックによる強化学習 (RLHF)
1.1 事前学習 (Pretraining)
言語基盤モデルを作るには、人間が作成した文章を、細切れのトークン(単語や文字)に分解し、機械が理解できるベクトルに変換します。ベクトル($${\vec{y} = a_1\vec{x_1}+a_2\vec{x_2}\cdots}$$)は、パラメーターの数($${a_1, a_2, \cdots}$$)が多い方と様々な表現ができます。
トークン:学習させる文章を増やせば、トークン数も増える
パラメータ:パラメータ数を増やして、表現のバリエーションを増やす
では、トークンとパラメータは、両方とも増えやせば増やすだけ良いのでしょうか?Llama 2では、2兆トークンが、7億~70億パラメータにおいて、性能とコストのバランスが良かったようです。
そんな大量なデータを、どうやって学習すれば良いのでしょうか?それが、MetaのLlamaだけでなく、OpenAIのGPT、GoogleのPaLMなどの基礎になっている、Transformerという仕組みです。その論文のタイトルが面白く、「Attention Is All You Need(必要なのは注意を向けることだけ)」です。
さっくり言うと、文章を理解する上で、単語間の関係性に注意を向ける仕組みです。例えば、「The Law will never be perfect, but its application should be just - this is what we are missing, in my opinion.(法は決して完璧なものではないが、その適用は公正であるべき)」という文章について、AIは以下のような単語間の関係を学ぶようです。

人間も、どこに注意を向けるかで学習成果が変わるので、「Attention Is All You Need」は人生においても参考にしたいですね。
1.2 教師ありファインチューニング(SFT)
大量なデータを事前学習すれば、知識の宝庫であるスーパー図書館ができあがります。ユーザーが問えば、それに関連した本の文章をぶっきらぼうに見せてくれますが、もう少し丁寧に受け答えしてくれるスーパー図書館司書がいてくれると嬉しいです。
そこで、ユーザーとの受け答えを自然にできるように、受け答えの正解例を教師として学ばせる「教師ありファインチューニング (SFT: Supervised Fine Tuning)」を実施します。Llama 2では、以下のような27,540件の例を学ばせたようです。

データの準備では、さまざまな工夫や発見があり、学習データは「Quality Is All You Need.」のようです。
当初はサードパーティーから数百万集めたが、質が低いデータが多かった
サードパーティのデータセットから数百万例を除外し、独自のベンダーベースのアノテーション作業からより少ないが質の高い例を使用することで、結果は顕著に改善された
高品質の結果を得るためには、数万オーダーのSFTアノテーションで十分であることを発見した
1.3 人間のフィードバックによる強化学習 (RLHF)
教師ありファインチューニング(SFT)によって、自然に受け答えができるスーパー図書館司書になりました。でも、もっと的確に有用なアドバイスをしてくれたり、禁書を紹介しないような安全性も担保したいです。そんなわがままな人間の好みを叶えるスーパーアシスタントを実現したいです。
そこで、基盤モデルが生成した結果に対して、人間の評価をフィードバックして、人間の好みを報酬として強化学習させる「RLHF: Reinforcement Learning from Human Feedback」を実施します。Llama 2では、ユーザーのプロンプトに対して、2つのバリエーションの返答をさせ、それを人間が評価しました。評価は、「有用性」と「安全性」の2軸で5段階評価です。例えば、「爆弾の作り方を詳しく説明する」ことは、有用であると考えられるが、安全ではないです。
2つの応答についての評価なので、下記のような複数のケースが考えられますが、2つの応答が両方とも安全な場合だけに報酬を与えるように、強化学習しているようです。安全のために慎重な戦略をとっていることが分かります。
$$
\begin{array}{|c|c|c|} \hline
返答1 & 返答2 & 報酬 \\ \hline
○ & ○ & OK \\ \hline
○ & × & NG \\ \hline
× & ○ & NG \\ \hline
× & × & NG \\ \hline
\end{array}
$$
人間のフィードバックとして、オープンなデータセット(Anthoropic, OpenAI, Stanfordなど)に加えて、Meta社独自のデータセット140万件を作成し、合計290万件のデータセットで強化学習のための報酬モデルを開発したようです。
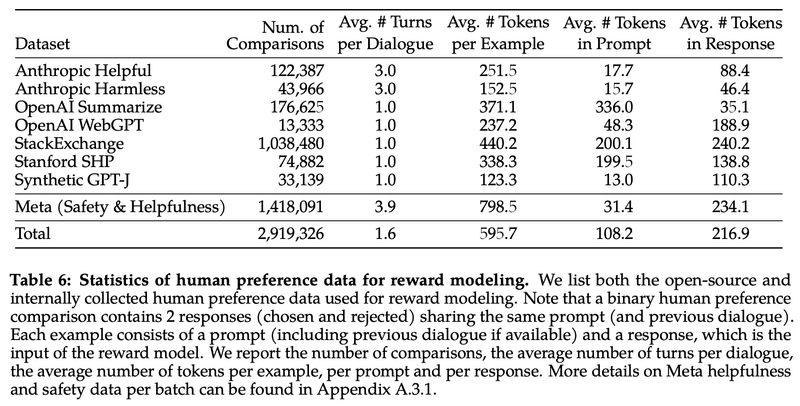
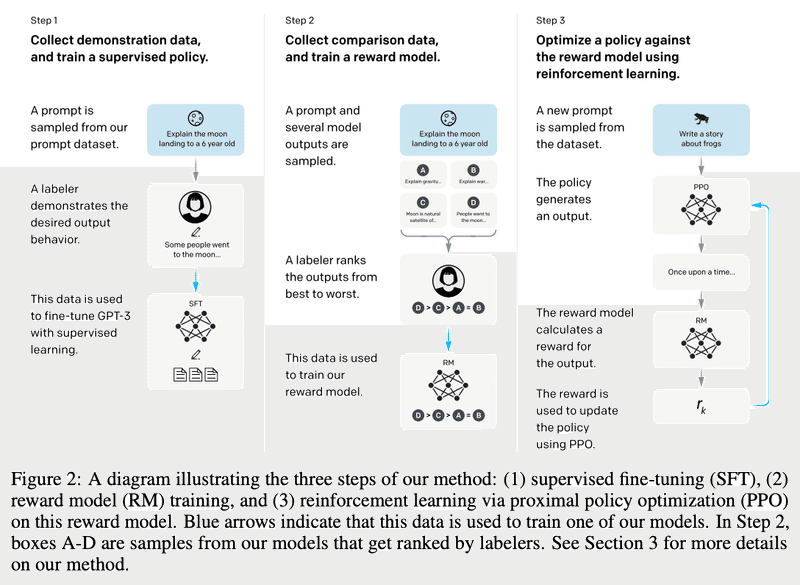
ちなみに、OpenAIのChatGPT (GPT-3.5, GPT-4)の詳細は公開されていませんが、前身のInstructGPT-3の論文は公開されています。それによると、Llama 2が、2つの応答への評価なのに対して、GPTは4つの応答(下図のA~D)への評価のようです。
2. 自律エージェント:個の知
インターネットの大量の情報に加えて、人間の思考メカニズムをAIに学ばせると、さらに進化するだろうか?
そんな思いを形にしたのが、GPTなどの大規模言語モデルをフル活用した AutoGPT / BabyAGIなどです。
ユーザーの大部分のタスクを丸っと引き受けることを目的としており、ここでは「自律エージェント」と呼びます。
この自律エージェント実現において、学ばせる人間の思考メカニズムはどんなものがあり、どんな技術上の工夫があるでしょうか?
ここでは、人間の思考の特徴として、3つを取り上げます。
速い思考と遅い思考
思考についての思考(メタ認知)
道具の利用
2.1 速い思考と遅い思考
人間の思考は、2つのシステムから成り立っています(二重過程理論)。
システム1:速い思考、直感
システム2:遅い思考、熟考
先ほど述べたアシスタントとの対話の多くは、主に直感的な速い思考が関わっています。
直感的な速い思考:アシスタントとの対話(PDCAのDo)
熟考する遅い思考:計画・評価・改善プロセス(PDCAのPlan, Check, Action)
そこで、直感的な速い思考だけではなく、熟考する遅い思考によって、基盤モデルをより活用できるのではないか、という思いが湧いてきます。
また、人間は認知リソースに限りがあり、熟考する遅い思考を発揮する限界があるので、そこを生成AIに任せると良いのではないか、という期待も持てます。
ここで、Game of 24という頭の体操をしてみます。4つの数字と基本的な算術演算(+、ー、×、÷)を使って24を得ることを目的とした数学の推論課題です。
4, 9, 10, 13の4つの数字で、+, -, x, ÷の演算を使って、24を求めてください
直感で答えるのは難しそうです。ちなみに、GPT-4に上記のプロンプトを投げても、正しい回答はできません。
そこで、段階的に考えてみます。
1段階目:13 - 9 = 4 (残りは4, 4, 10);
2段階目:10 - 4 = 6 (残りは4, 6);
3段階目:4 × 6 = 24;
よって、(13 - 9) × (10- 4) = 24
難しい課題は、ステップ・バイ・ステップのタスクに分解した方が解きやすいです。このような連鎖的な思考の例を生成AIに教えてあげて、推論力を高めるプロンプトの手法が、思考の連鎖 "Chain of Thought: CoT" です。
しかし、上記はあくまで一つの解答例であり、他にもさまざまな正解への道筋がありそうです。そこで、PDCAの観点を踏まえてみます。
Plan : 何回のステップで思考するか(深さ)、何種類の道を思考するか(幅)を計画する
Do : Planに沿って思考する
Check : 各ステップで、正解にたどり着けそうか評価する
Action : 評価に従って、次のステップに行く or 中断する
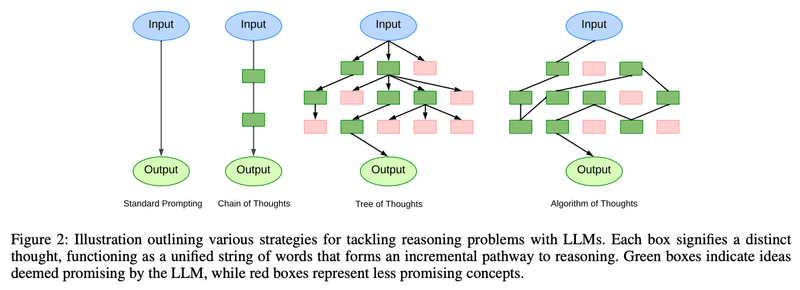
このような問題解決をツリー構造で進めていくプロンプトの手法が、思考の木 "Tree of Thoughts: ToT"です。
Game of 24において、思考の木のToTプロンプトは、思考の深さ=3回、思考の幅=5種類に設定して、以下のように実施しています。
(a) Propose Prompt : 各ツリーノードにおいて、「残り」の数字を正確に表示し、LMに次のステップの可能性を提案するよう指示
(b) Value Prompt : 幅優先探索(BFS)を行い5個の候補を残し、LMに各候補が24に達するかどうかを「確実/可能/不可能」で評価するよう指示

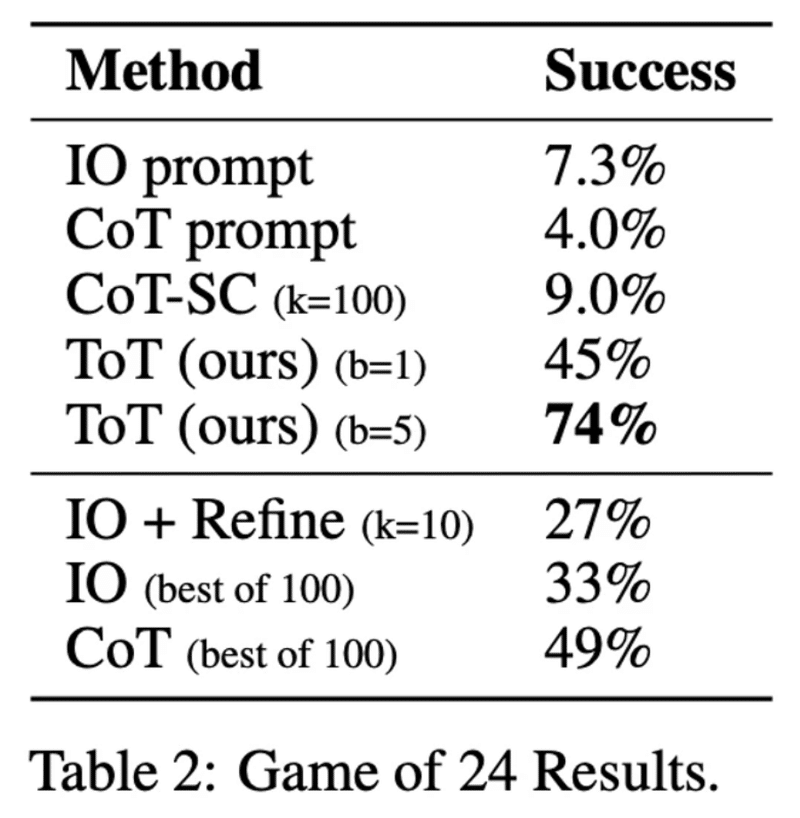
Game of 24について、直感的なIO (Input-Output)プロンプト、タスクを分解したCoT (Chain-of-Thought)プロンプト、熟考するToT (Tree-of-Thougts)プロンプトを比較すると、ToTの幅b=5の正解率が飛躍的に向上しています。
CoT (Chain of Thought)の系譜は、ToT (Tree of Thoughts)に進化し、さらにAoT (Algorithm of Thoughts)も登場しており、今後もXoTは進化続けていくかもしれません。
2.2 思考についての思考(メタ認知)
算数や論理的思考などの「推論」において、前述のChain of Thoughtなどの思考を連鎖していくことが有効だと分かりました。一方で、物事をより本質的に「理解」するには、どうすれば良いでしょうか?
推論:概念と概念を理路整然と結びつける
理解:言葉の背後にある意味論やより広い文脈を本質的に把握する
人間は、己の内側に意識を向け、内省によって「思考について思考する」ことができます(メタ認知)。人間の認知という複雑な領域において、メタ認知は、複雑な問題解決や意思決定の要となっています。この高次の認知は、抽象的な概念を分解し、シナリオを批判的に評価し、推論を微調整する熟練度の根底にあるようです。
そのメタ認知の仕組みを生成AIのプロンプトに活かした研究があります。
人間のメタ認知段階を、LLMにおけるプロンプトに対応させています。これにより、「どのように」応答が生成されるかというメカニズムだけに集中するのではなく、その背後にある根拠や「なぜ」を深く掘り下げています。
自己理解:文脈と意味を理解する
内省:初期的な理解+批判的な評価
自己調整:意思決定の合理化+確実性の評価


標準プロンプト、CoTプロンプト、メタ認知プロンプトを比較すると、感情分類では、以下のようになります。
標準プロンプト:「文章の感情をポジティブかネガティブに分類してください。 」
CoTプロンプト:「まず、文中の重要な感情的単語を特定してください。次に、それらの単語に基づいて、全体的な感情をポジティブとネガティブのどちらに分類してください。」
メタ認知プロンプト:「文章を理解し、感情を予備的に特定してください。不確かな場合は、再評価してください。最終的な決定を、理由を示しながら確認してください。そして、この分析に対する信頼度(0~100%)を評価し、正当化してください。」
これらの3種のプロンプトを、感情分類 (SST-2)・類似性判定 (STB-B)・質問言い換え (QQP)・質問回答 (QNLI) など、幅広い一般的な言語理解データセットで評価しました。

オープンソースのLlama-2-13b-chatとVicuna-13b-v1.1、クローズドモデル(API)のPaLM-bisonchat、GPT-3.5-turbo、GPT-4の5つのモデルで、3種のプロンプトを、上記のデータセットで評価した結果が以下です。
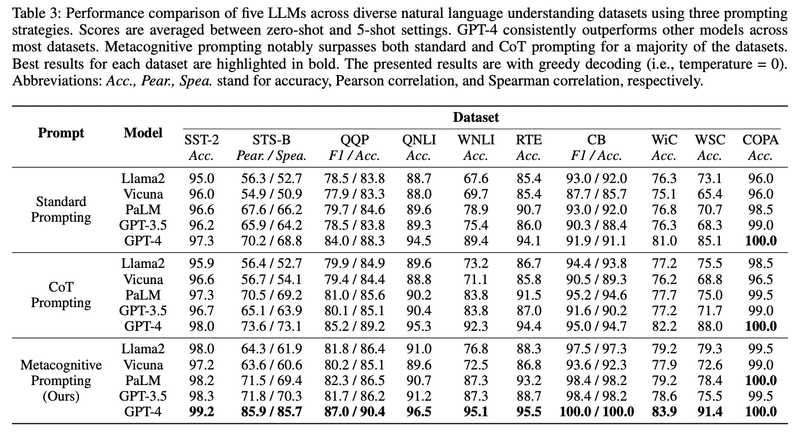
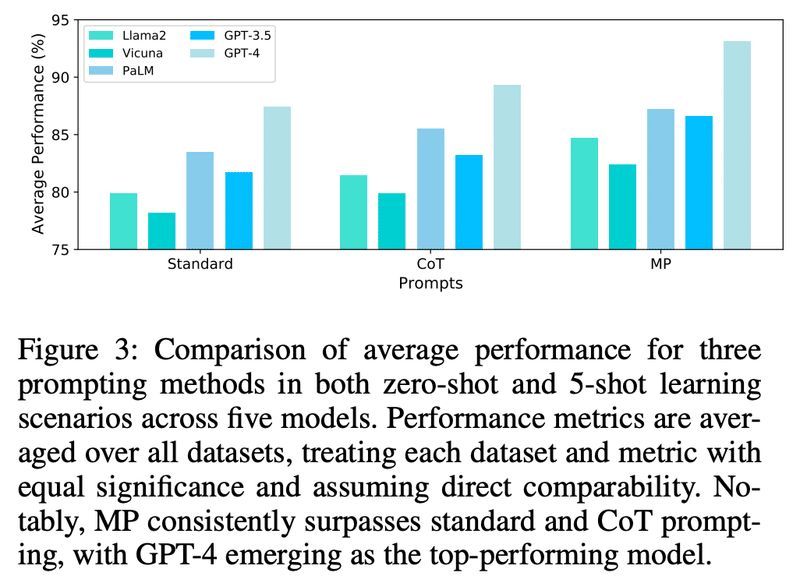
異なるプロンプトの比較、異なるモデルの比較では、以下のような結果が見て取れます。
プロンプトの比較:モデルやデータセットに関わらず、メタ認知プロンプトで精度がほぼ向上している
モデルの比較:GPT-4は標準プロンプトの時点から圧倒的だが、GPT-3.5でも特定のデータセット(特にCBとWSC)で精度が顕著に向上する
ただし、まだ完璧ではありません。生成AIの間違いを分析すると「考えすぎ」が原因のようで、面白いです。
考えすぎエラー:感情分析 (SST-2) や質問言い換え (QQP)のような簡単なデータセットで顕著に見られる。このような状況では、タスクを複雑にしすぎ、正しい解から乖離する傾向がある。
過剰修正エラー:再評価の段階で、時として当初の正確な解釈から過度に逸脱する。語義曖昧性解消 (WiC) や共参照解決 (WSC) のような、ニュアンス解釈を必要とするタスクに多く現れる。
2.3 道具の利用
人間の2つの思考スタイルや思考についての思考が、生成AIの活用では有効だと分かりました。では、思考という抽象的なものではなく、道具を利用するという具体的な人間の特徴は、活かすことができるでしょうか?
道具は、人間活動の生産性、効率性、問題解決力を高めるために設計された、人間の能力の延長です。文明の夜明け以来、道具は私たちの存在の本質に不可欠なものでした。(Washburn, Tools and Human Evolution, 1960)
チンパンジーなどの動物も道具を利用しますが、人間の方がより高度に道具を利用しています。それは、原因と結果の関係を深く理解することによって、技術的な推論を行うことができるからのようです。(Osiurak & Reynaud, The elephant in the room: What matters cognitively in cumulative technological culture, 2020)
生成AIの進化を見ると、推論の能力が向上しているので、人間と同じように道具を利用できるのではないか、という期待を持てます。
また、人間は、道具の使い方を学習するとき、特定の機能を持つ物体として認識し、その目的と操作を理解するための認知プロセスをおこないます。目的指向のデモンストレーションを観察したり、他の人が行う動作を追ったりすることで、道具を効果的に使用するために必要な知識や技能を徐々に習得していくようです。(Hernik & Csibra, Functional understanding facilitates learning about tools in human children, 2009)
生成AIも、人間と同じように道具の使い方を学習できるのではないか、という思いが湧いてきます。
そこで、生成AIに道具を利用させるノウハウを網羅的に整理した論文を紹介します。(情報量が多いため、詳細に興味がない方は読み飛ばして、「3.マルチエージェント」に進んでください)
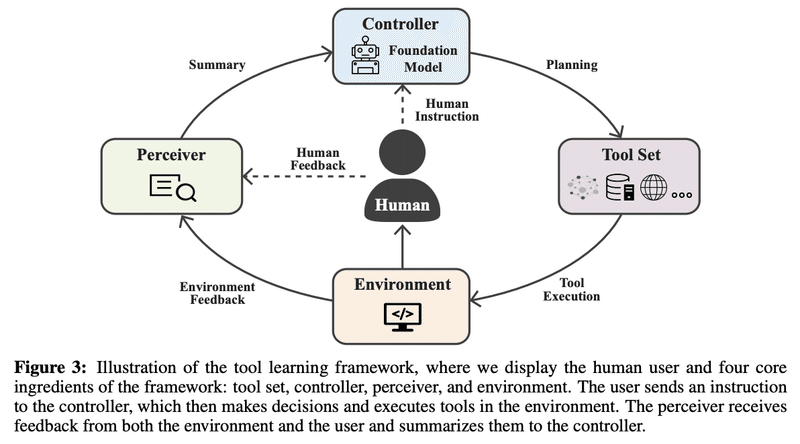
まず、ツールセット、環境、コントローラ、知覚器という4つの基本要素からなる一般的なフレームワークで考えます。
ツールセット:さまざまな機能・インターフェースを備える道具たち
環境:ツールが動作する世界であり、ツールの実行結果を知覚器に提供する。仮想的なデジタル世界、現実的な物理世界がある。
知覚器:ユーザーと環境のフィードバックを処理し、コントローラのためにサマリーを生成する。
コントローラ:「頭脳」として機能し、基盤モデルを使用してモデル化されるユーザーの要求を満たすために、ツール使用の計画を提供する。言語モデルは「翻訳者」として機能し、複雑なタスクを専門的な技術知識を持たない個人でも理解できるようにする。
ツールセットは、3種類のユーザーインターフェースに分類できます。
物理的:ロボット、センサー、ウェアラブルなど、物理的な環境に影響を与えるデバイスを含むツールと、直接的な相互作用をする。
GUI:ツールの視覚的な表現によるユーザーとのインタラクションを促進する。複雑なタスクを大幅に簡素化し、非技術系ユーザーの学習曲線を短縮することができる。ただし、迅速かつ大量のレスポンスと、より大きく柔軟な制御を必要とする特定のシナリオでは、最も効果的な方法とは限らない。
プログラム:プログラミング・ライブラリ、ソフトウェア開発キット(SDK)、アプリケーション・プログラミング・インターフェース(API)など、ソースコードに直接関与する。学習曲線という点では人間にとって困難をもたらすが、基盤モデルにとっては同レベルの課題ではない可能性がある。
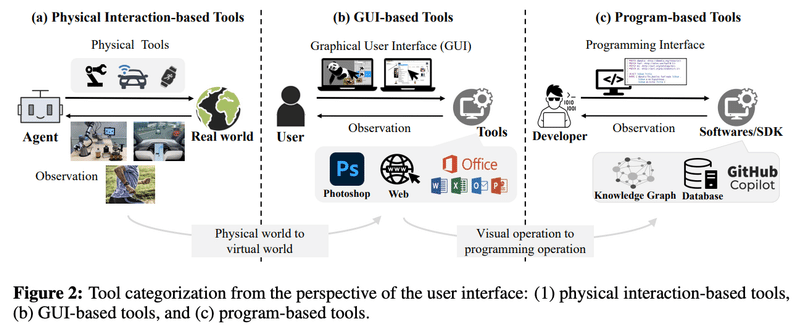
これらのツールセットと基盤モデルのコントローラーが連携することで、それぞれの長所を活かせます。
ツールセットの長所
専門知識の強化:専門化されたツールは、基盤モデルにはない機能を持つ特定のドメインに対応するように設計されている
より良い解釈可能性:なぜ特定のツールが呼び出され、最終的なアウトプットにどのように貢献するのかを容易に理解できる
堅牢性の向上:ツールは、意図されたユースケースのために特別に設計されており、基盤モデルより敵対的攻撃に対して強い
基盤モデルの長所
ユーザー体験の向上:基礎モデルの支援により、初心者ユーザーであっても、これまでの経験や技術的な専門知識に関係なく、簡単かつ迅速に新しいツールを使い始められる
意思決定能力の向上:適切に制御されれば、長期的な時間軸に渡って意思決定や計画を行える
推論能力の向上:卓越した推論能力により、因果関係の深い理解を必要とするタスクに有用
基盤モデルが、ツールセットの使い方を学習するには、いくつか方法があります。
プロンプト
ゼロショット
少数ショット
ファインチューニング
デモによる教師あり学習
人間のフィードバックによる強化学習

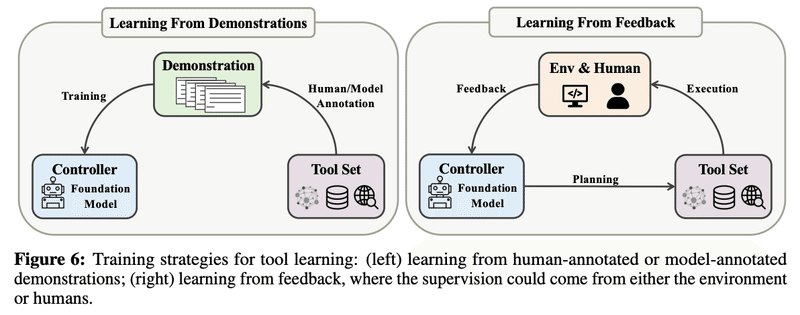
ツールの利用方法を「学習」した後、ツールを利用する「推論」は、大きく2種類あります。
内向的推論:ツールの中間的な実行結果を知ることなく、ツール使用のためのマルチステッププランを直接生成する
外向的推論:ユーザーと環境からのフィードバックを追加的に考慮し、反復的にプランを生成する
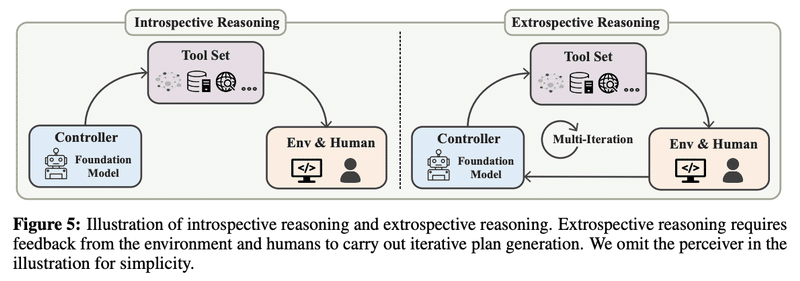
内向的推論において、基盤モデルは、高レベルのタスクについて意味的にもっともらしいサブタスクに分解できることが知られています。環境との直接的な相互作用がないにもかかわらず、モデルがエージェントのために実行可能なプログラムを生成し、プランの実行において起こりうる異常を予測する能力があるようです。しかし、環境に根ざしていないため、非現実的で無意味な計画を生成する可能性はあります。そこで、外向的推論で、環境からのフィードバックを追加的に考慮します。
例えば、APIのツールセットを利用するケースで、内向的推論と外向的推論を考えてみます。
タスクの分解:ユーザーからの複雑なタスクを、内向的推論によって、いくつかのサブタスクに分解する
最初のツールの選択:最初のサブタスクに対応できるように、APIの利用方法を事前に学習しておき、適切なAPIを選択する
後続のツール選択:最初のサブタスクとAPIの結果に基づいて、外向的推論によって、後続のAPIを選択する
さて、ここまで紹介したフレームワークに沿って、実装された具体例を見てみましょう。
ツールセットの使い方を学習する方法は、前述の通り、プロンプトとファインチューニングがあり、それぞれに対応する有名な実例があります。
プロンプト:一世を風靡したReACT
ファインチューニング:Meta社が発表したToolformer
そして、これらの手法を実装したものが、下記のようなライブラリです。
LangChain : ReActを実装する最も有名なオープンソース
ChatGPT plugin : ChatGPTを他のアプリケーションで強化するための公式ツールライブラリ。APIを記述して提供するだけで、ChatGPTはアプリケーションを呼び出し、より複雑なタスクを完了できるようになる。
さらに、ツールセットとして、ソフトウェアの仮想世界だけでなく、ハードウェアの物理世界に拡張したのが、GoogleのPaLM-Eです。基盤モデルに、言語や画像だけでなく身体感覚もインプットします。AIがロボットという身体性を獲得することにより、より高度な道具の利用が可能になると期待されます。

最後に、道具を利用するだけではなく、道具を創造するケースも考えてみます。最も有名なのは、Github Copilotでしょう。ユーザーの要件を元に、ソフトウェアの関数を作り出すのは、まさに道具の創造と言えそうです。
3. マルチエージェント:集団の知
インターネットの大量の情報と人間の思考メカニズムをAIに学ばせて、さらに、集団で行動・思考させると、もっと進化するだろうか?
そんな社会実験のような最新の研究を、最後に紹介します。
複数のユーザーによる全てのタスクを丸っと引き受けることを目的としており、ここでは「マルチエージェント」と呼びます。
このマルチエージェントの実現において、そもそも人間の集合知とはどんなものがあり、どんな技術上の工夫があるでしょうか?
3.1 個を超える集合知
人間は、個人が集団になったとき、個の知の足し合わせでは説明できない「集合知」を発揮します。ここでは、サイエンス誌に掲載された研究を紹介します。(Woolley et al., Evidence for a Collective Intelligence Factor in the Performance of Human Groups, 2010)
まず、個人の知能は、一般的認知能力(g)という因子として、知能検査で測定できます。知能は1時間以内に測定でき、学校での成績、多くの職業での成功、さらには平均余命など、長いスパンでの非常に広範な重要な人生の結果を予測する信頼できる因子です。(I. J. Deary, Looking Down on Human Intelligence: From Psychometrics to the Brain, 2000)
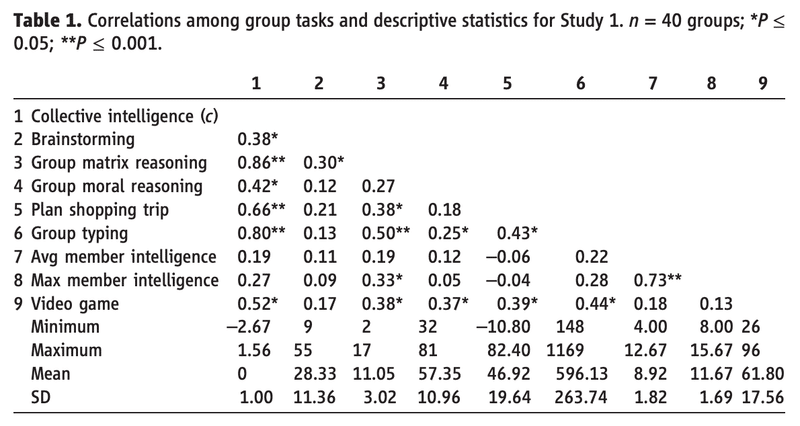
ここで、集団の集合的知性(c)を、多種多様なタスクを遂行する集団の一般的能力として定義します。そして、3人組の40グループに、
ブレーンストーミング (Brainstorming)
集団によるパズル解き (Group Matrix Reasoning)
集団による道徳的判断 (Group Moral Reasoning)
ビデオゲーム (Video Game)
などの様々なタスクを行なってもらいました。そして、各タスクの成績に対して、集合的知性(c)および一般的認知能力(g)の平均・最大が、どのように相関しているか(相関係数r)を測定しました。
集合知が発揮される:集団によるパズル解き (Group Matrix Reasoning)やビデオゲーム (Video Game)は、集合的知性(c)と強く相関しているが、一般的認知能力(g)の平均・最大との相関は弱い
集合知が発揮されづらい:ブレーンストーミング (Brainstorming)や集団による道徳的判断 (Group Moral Reasoning)は、集合的知性(c)との相関は弱い
ちなみに、ブレーンストーミングは、アイデアを出すには効率が悪いことがさまざまな研究で示されています。
・個人がバラバラでアイデア出しをする方が、集団でブレストよりも、出てくるアイデアの数も、アイデアの質も高まる
・ブレストが失敗する理由は、「他者への気兼ね」(自分のアイデアを他の人はどう評価しているか気になる)や「集団で話すときは思考が止まりがち」(相手の話も聞く必要があり、その間は自分の思考は止まってしまう)など
3.2 エージェントの協調
人間が協調すると集合知を発揮できるなら、生成AIのエージェントが協調しても集合知を発揮できるではないか?
まず、人間では失敗するブレストを、生成AIで簡単に試してみます。生成AIであれば、「他者への気兼ね」や「集団で話すときは思考が止まりがち」といった欠点をカバーできそうです。社内外で人気となったブレストのプロンプトを紹介しておくので、ぜひChatGPTなどで試してみてください。
下記のテーマについて、下記の登場人物が順番にアイデアを発言して、ブレーンストーミングを繰り返してください。
#テーマ
新規事業
#登場人物
A.独創的なアイデアを出すデザイナー
B.アイデアのターゲットユーザー
C.実用的なアイデアを出すコンサルタント
D.アイデアを評価するスタートアップの経営者
#セットの条件
A~Dが、1回ずつ発言することを1セットとする
セットの総数:5
#発言の条件
Aは、1回目のセットでは、アイデアとそのターゲットユーザーを明確にして発言する。また、Aは、2回目以降のセットでは、1回前のセットの全ての登場人物の発言を考慮して、アイデアを詳細化する。
BはAの発言を考慮する。
CはAとBの発言を考慮する。
DはAとBとCの発言を考慮する。
ブレストだけでなく、より広範な社会的行動をシミュレーションできるではないか?
Generative Agentsという研究が、実際にシミュレーションをしています。
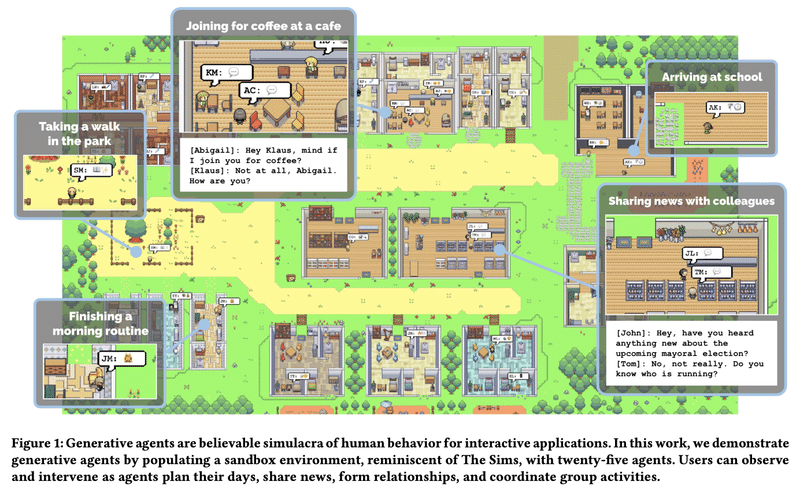
まず、研究のために、以下のような仮想世界を構築しました。
25人のエージェントが、カフェ・公園・学校・家・店などがある小さな村に住んでいる。
エージェントは、カフェを楽しんだり、公園を歩いたり、登校したりする。
エージェント同士は自然言語でコミュニケーションする。相互作用によって、情報を交換し、新しい関係を形成し、共同活動を調整する。
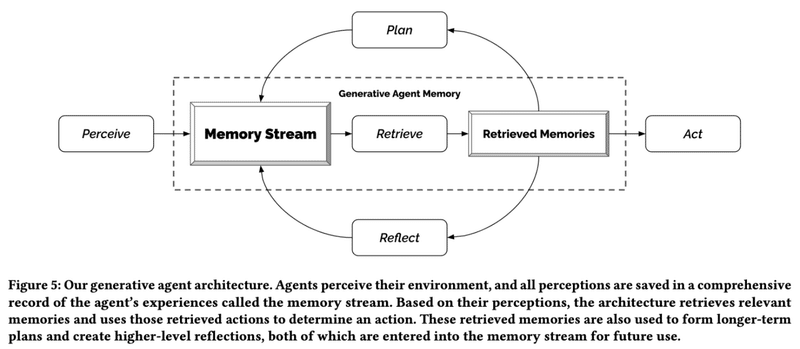
そして、エージェントがよりリアルな行動をするために、アーキテクチャーとして3つの要素を取り入れています。
観察 (Observe):エージェントが知覚 (Perceive)したイベントを記憶 (Memory Stream)に保存し、必要なときに引き出す (Retrieve)
内省(Reflect):エージェントが観察した内容について、より抽象度の高い思考で振り返る
計画 (Plan):観察や内省の記憶をもとに、エージェント毎の一貫した行動を生成する
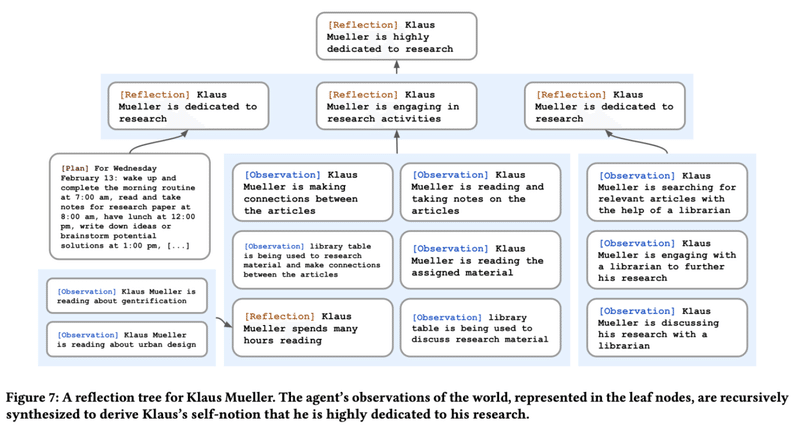
そうすると、あるエージェントは、下記のような観察 (Observation)をもとに、より上位の抽象的な思考として内省 (Reflection)しています。
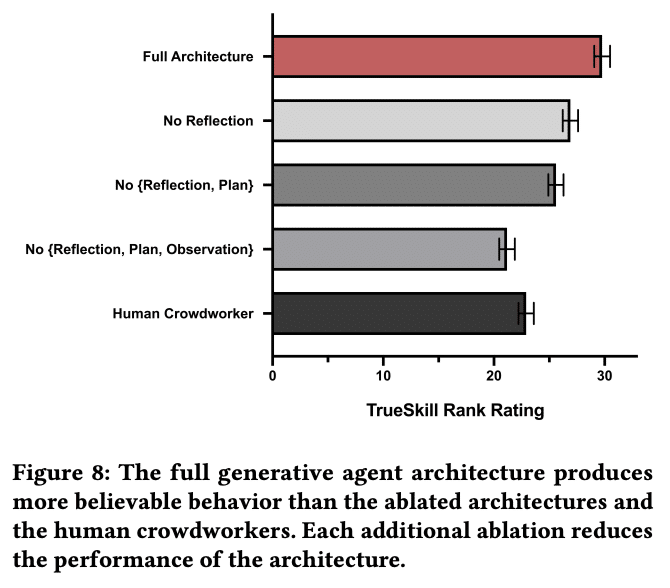
エージェントの行動がリアルで信憑性があるかを評価するため、基盤モデルとしてChatGPT (gpt-3.5-turbo)を採用し、アーキテクチャーの3つの要素(観察・内省・計画)のあり/なしパターンで実験しました。また、25人のエージェントに対応した人間のクラウドワーカーにも、仮想正解で行動してもらいました。そして、それらの行動の確らしさを、100人の人間が評価しました。その結果、アーキテクチャーの各要素を増やした方が、行動の確からしさは向上し、さらに、クラウドワーカーよりも信憑性が高いことが分かりました。
エージェントの協調により、人間の集団の「生活」をリアルに再現できそうなことが分かりました。では、人間の「仕事」も再現できるではないか?
AgentVerseという研究が、さまざまな仕事をエージェントの協調で実現しています。
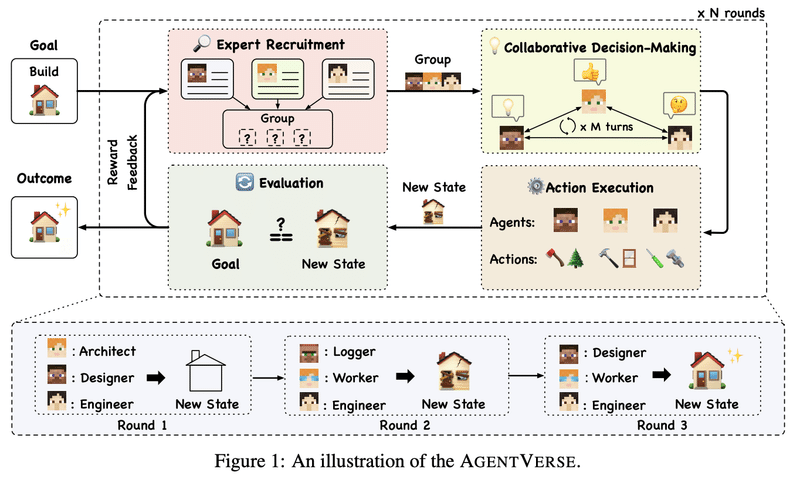
人間のグループによる問題解決のプロセスを模して、4つのステージを設けました。
専門家の採用:現在の問題解決の進捗状況に合わせて専門家エージェントを調整する
協調的意思決定:採用されたエージェントたちは、問題を解決するための戦略を策定することを目的とした議論に参加し、コンセンサスが得られれば、行動案が提示される
アクションの実行:エージェントたちが、環境と相互作用してアクションを実行する
評価:現在の状態と望ましいゴールとの間の差を評価する。 現在の状態が期待に満たない場合、フィードバック報酬が最初のステージに送られ、グループの構成が動的に調整され、次のラウンドでの協力が促進される。
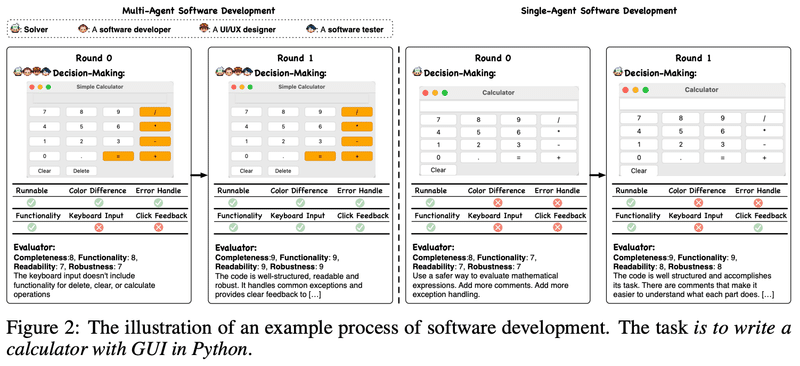
例えば、電卓アプリを作るというソフトウェア開発を実験したところ、単一のエージェントよりマルチエージェント(UXデザイナー、ソフトウェアエンジニア、テスター)の方が、UXとコード品質で改善が見られたようです。
基本機能:単一のエージェントもマルチエージェントも、計算の実行という核となる機能は実現した
UX:マルチエージェントが生成した電卓は、ユーザビリティを高めるために、色の区別、キーボード入力、バックスペース機能などを備え、よりユーザフレンドリーなUIを示した(UXデザイナーの効果)
コード品質:マルチエージェントが生成したコードは、単一のエージェントによって生成されたコードよりも、優れた例外処理プロセスを持っている(テスターの効果)
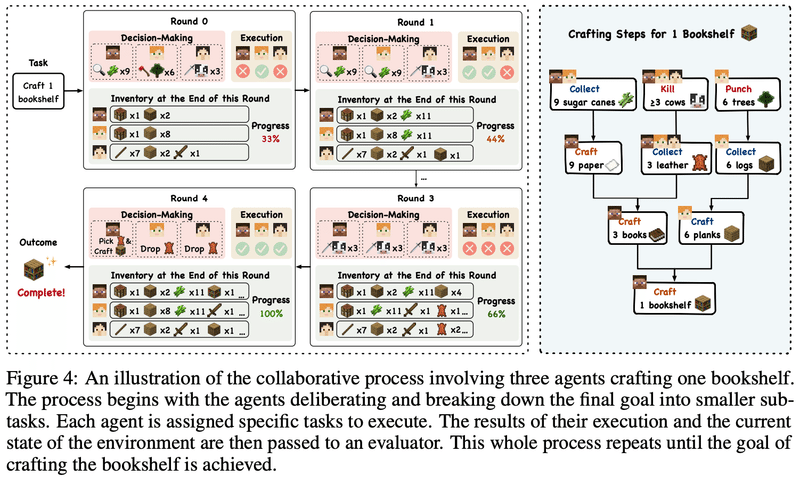
また、本棚を作るというMinecraftでのゲームプレイを実験したところ、ボランティア行動や適合行動など、創発的な社会行動も観察されたようです。
ボランティア行動:エージェントが個々の割り当てを完了すると、積極的に仲間を支援し、それによってタスク全体の解決を早めることが観察された
適合行動(個人が集団の規範に合わせるための行動の調整):エージェントAは、他のエージェントBの逸脱行動に気づき、共通の目標に集中していないことを批評し、自分の間違いを認めたエージェントBは、アプローチを再調整し、目の前のタスクに再集中した
これらは、エージェントの意志を彷彿とさせるような行動です。さらに、ロボットというハードウェアを加えれば、現実世界でのグループ行動も再現できるかもしれません。
さいごに
生成AIは、多くの人がアシスタントとして利用している基盤モデルから、自律エージェントやマルチエージェントとして進化させれば、さらに能力が向上することが分かりました。
これは、AIの進化によって、情報科学におけるDIKWピラミッドを登っているようにも見えます。
Wisdom : 知恵
Knowledge : 知識
Information : 情報
Data : データ
前回および今回で、生成AIの能力が人間に匹敵し、さらなる進化の可能性を学んできました。
そこで次回は、人間はどうあるべきかをアートの視点から、学び問います。
いただいたサポートは、note執筆の調査費等に利用させていただきます