
NovelAI V3 初心者教本・改

初めての方は初めまして、知っている方はこんにちは。かたらぎと申します。この度前作のNovelAI初心者教本を改定して公開することになりました。NovelAIの新UIやインペイント、コントールネットの一部などに対応した解説をしていきます。
↓前作
NovelAIに登録する
まずは下記のURLにアクセスして下さい。
NovelAI公式サイト
このような画面が現れますので「ログイン」を押してください。
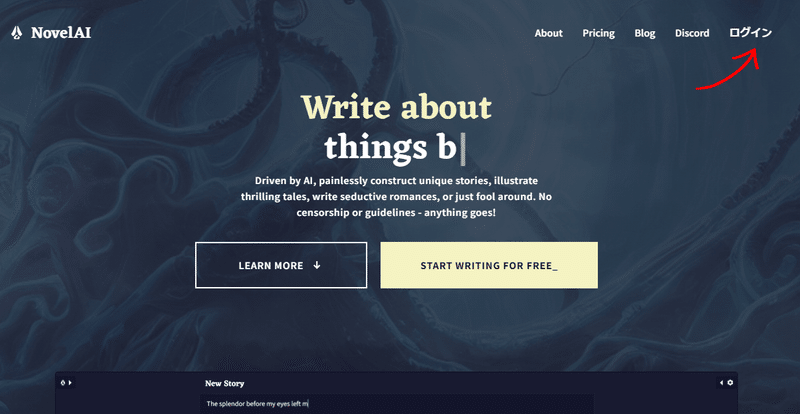
次にこのような画面が現れますのでアカウントを作ったことがない人は「Sign UP」から登録してください。アカウントを持っている方は「Email」と「Password」を入力してログインしてください。
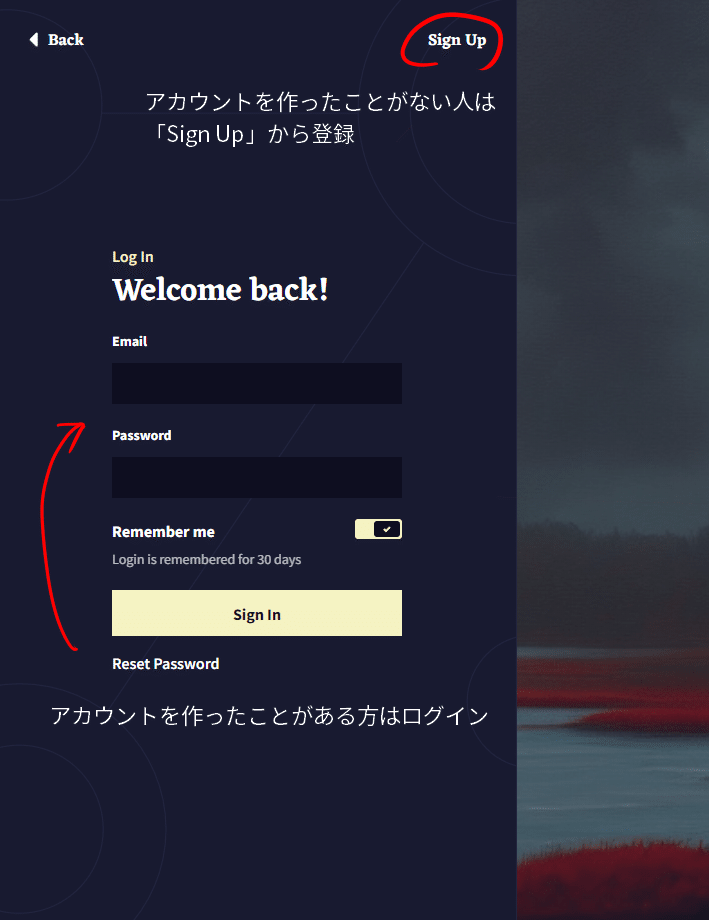
サインイン、ログインするとこのような画面になるので画像生成をしたい場合は赤枠の場所に進んでください。
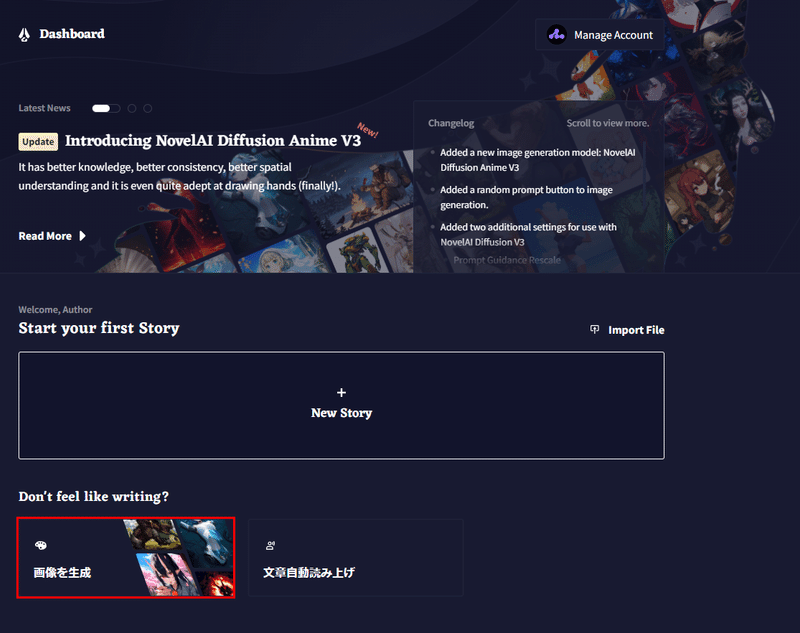
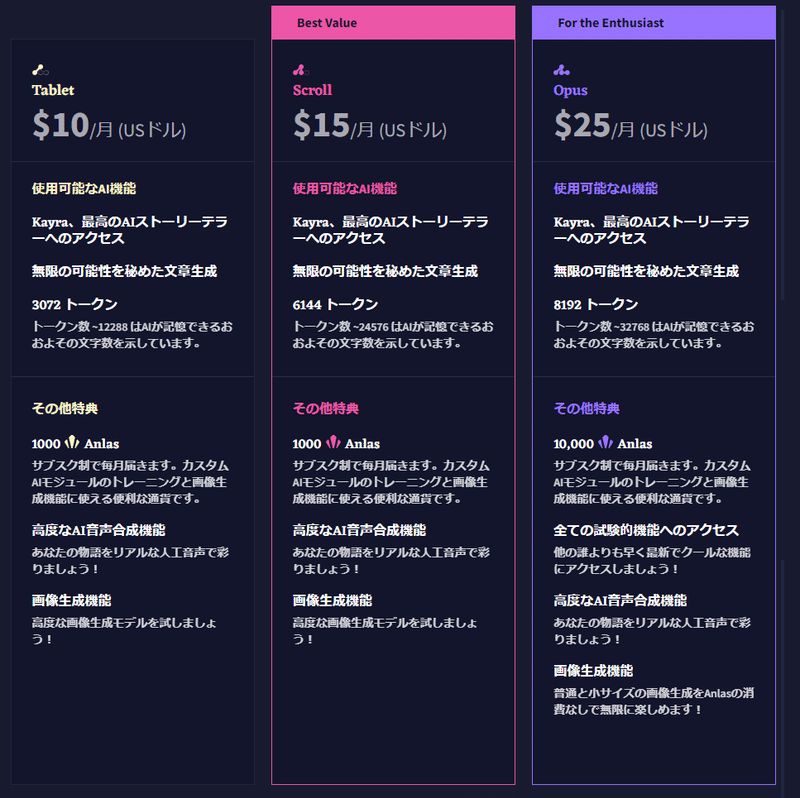
NovelAIで画像生成をするには「Anlas」と呼ばれる通貨が必要です。赤枠の「+」マークからAnlasを購入することができます。隣には残りのAnlasが表示されています。
23年11月18日現在の価格表はこうなっています。
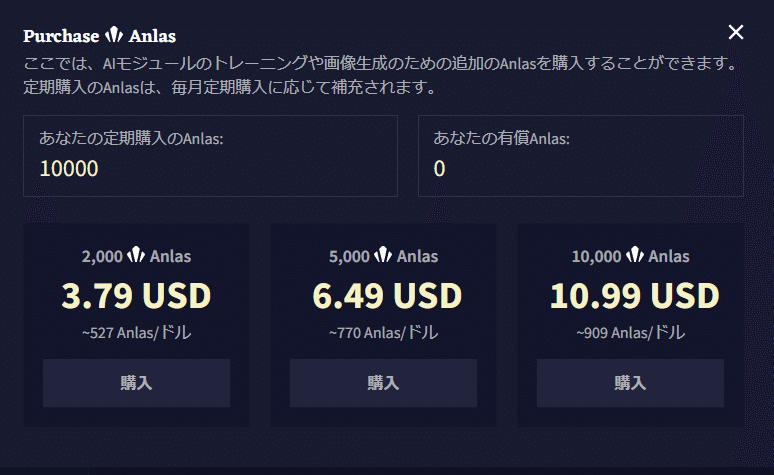
また、黄色枠からサブスクリプションとして契約することも可能です。ガチョウのマークを押すと「サブスクリプションを管理」→「進む」を押してプランを選択します。10$と15$のプランで変わるのは文章生成機能だけっぽいので、興味があって使ってみたいというだけの人は10$(Tablet)のプラン、がっつり勉強してうまくなりたい人は25$(Opus)プランをお勧めします。また、最初は10$のプランを選択し、途中から25$のプランにすることもできます。
ちなみに、25$のプランは後で小さいと普通の画像サイズの28step以下なら無料で画像を生成することができます。この機能は25$プランにしかありません。
一つ注意なのですが定期購入のAnlasはサブスクリプション契約時に亡くなってしまうようです。(上限が10000?)前回の分が残っている方は気をつけてください。
画面の説明
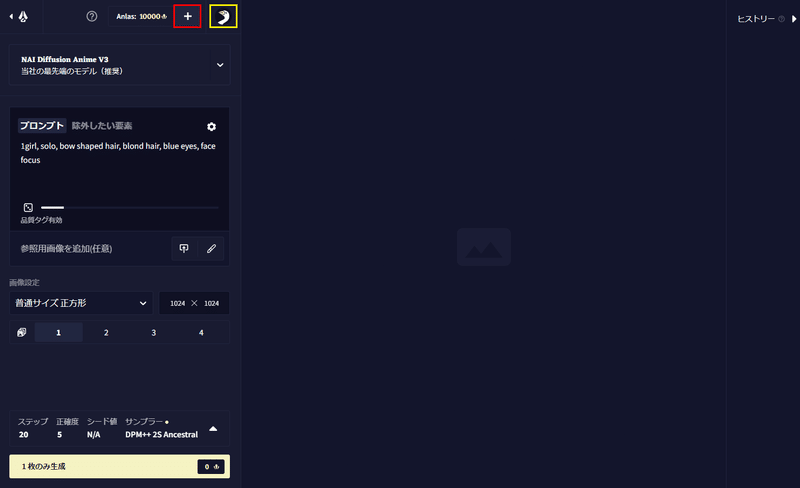
NovelAIの画像生成画面は次のようになっています。解説する部分を色枠でおおまかに囲んだのでそれぞれ説明していきます。
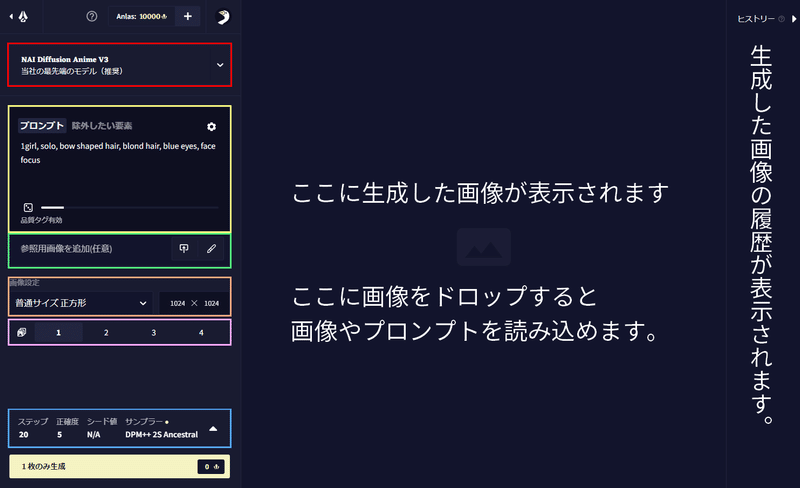
モデルの選択
まず、赤枠の部分が画像を生成するモデルを決める部分です。デフォルトでV3が選択されていますがこれが今のところ一番品質が良いのでそのままで構いません。

プロンプトとネガティブプロンプト
黄色の枠の部分はプロンプト(画像に描いてほしい要素)と除外したい要素(いわゆるネガティブプロンプト)を入力します。NovelAIはdanbooruというサイトの画像と画像に付けられたキャプション(画像の説明)を学習させていると考えられており画像のように「,」で英単語を区切って記述していきます。
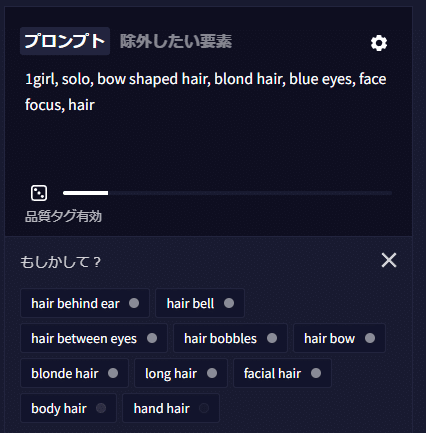
例)1girl, solo, bow shaped hair, blonde hair, blue eyes, face focus

NovelAIではプロンプトの強調の仕方がローカルと違います。ある単語を強調したいときは{blonde hair}と書きます。さらに強調したいときは{{{blonde hair}}}というように重ねていきます。また弱体化したいときは単語を[blonde hair]のように書きます。強化と弱化の数値に関しては次の早見表を見てみてください。

ただV3のモデルではプロンプトの順序がより重要になっている気がします。強調を使うよりプロンプトの順序を入れ替える方が良いかもしれません。
プロンプト欄の歯車マークを開くとより詳細な設定が出てきます。品質タグを加えるでは表面的には見えませんが自動的に「best quality, amazing quality, very aesthetic, absurdres」などのプロンプトが加えられています。
また、除外したい要素プリセットでは除外したい要素を自動的に追加してくれます。強い、軽い、指定なしの三種類がありそれぞれ次のような内容になっています。指定なしでも全く入っていないわけではないようです。強いと軽いにはnsfwが入っているので18禁画像などを作る場合は使用しない方がいいかもしれません。
強い:nsfw, lowres, {bad}, error, fewer, extra, missing, worst quality, jpeg artifacts, bad quality, watermark, unfinished, displeasing, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]
弱い:nsfw, lowres, jpeg artifacts, worst quality, watermark, blurry, very displeasing
指定なし:lowres
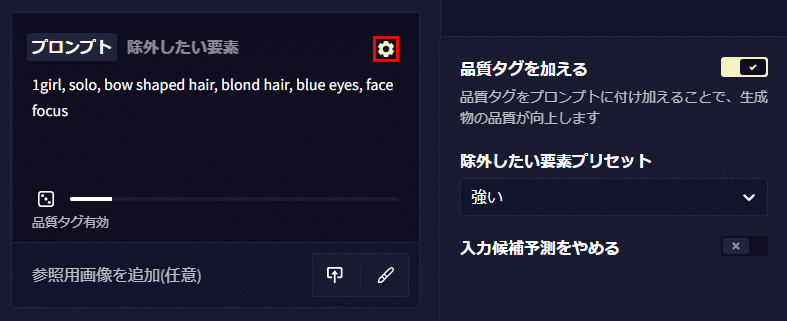
入力候補予測をやめるではプロンプトを入力する際に出てくる予測変換機能をオフにすることができます。多くの場合、生成モデルを学習したときに使用されたタグが予測として出てきますのでこれに沿って入力していくのがセオリーといえます。単語のそばに白い丸がありますがこれが濃いほど多く学習しているという意味です。
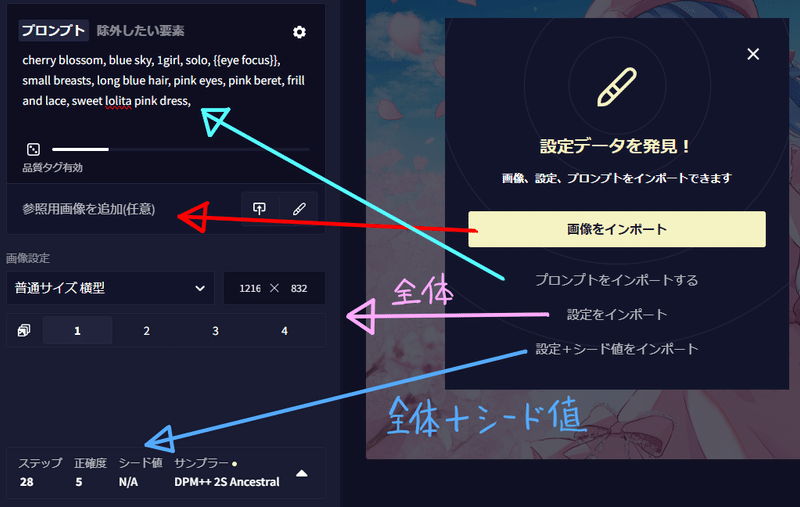
緑枠の部分では既存の画像や手描きしたものを素材に画像を生成するときに使います。(img2imgとコントロールネット) ↑のマークがついた場所で画像をインポートします。またペンのマークでは自分で線画を書きAIに完成させてもらうこともできます。

以前生成した画像もここから読み込めます。メタデータにプロンプトなどが含まれていれば自動で下記のような項目が出てきます。
画像をインポートするではプロンプトや設定をそのままに画像だけを読み込みi2iやコントロールネットで使用します。
プロンプトをインポートではプロンプトのみ画像から読み取ってコピーします。
設定をインポートではシード値を除くすべての設定が読み込まれます。(画像は読み込まれません)
設定+シード値では生成した画像と同じ画像を作るときに使います。
ただし、その際はモデルのバージョン同期は行われませんので生成された画像とのものと一緒かどうか確認してください。
余談ですが右のヒストリーボードでは「Ctrl+左クリック」でプロンプトと設定を読み込むことができます。

画像サイズと枚数
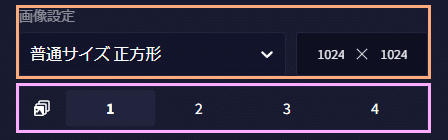
オレンジの枠は画像の生成サイズを決める場所です。画像サイズが大きければ消費するAnlasも増えていきます。ただし、25$のサブスクに加入している方は小さいサイズと普通サイズの28ステップまではAnlasを消費することなく生成できます。
紫枠では画像の同時生成枚数を決めます。元となるサイズによって上限が変わり小サイズでは6枚まで、普通サイズでは4枚まで、大サイズは2枚まで同時にできます。壁紙サイズでは使用することができません。
各種設定
青枠の部分ではステップ数と、プロンプトの反映度を決める正確度(CFGスケール)、シード値、サンプラーを決められます。
ステップ数の解説すると長くなるので詳しい説明は省きますが、基本的には少なすぎるとぼやけた絵になります。ただ増やせばいいというものでもないので品質が安定したうえでAnlasの消費が少なめな20ステップ前後がおすすめです。ただし、25$プランの方は28ステップまで無償なので特別の理由がなければそれでいいでしょう。
正確度ではプロンプトをどれほどプロンプトに忠実にするかを決めるところです。V3のデフォルトでは5ですが8までくらいまでは上げても大丈夫そうです。9以上だと色味や破綻が多くなり生成できないこともありました。
シード値とは生成した画像に付与される番号です。プロンプトや設定も含め全く同じであればほぼ同じ画像を生成することができます。
サンプラーも詳しい説明は省きますが、NovelAIが推奨している「Eular」「Euler Ancestral」「DPM++ 2S Ancestral」のいずれかを使うとよいでしょう。
一番下のボタンが生成のボタンになっています。

画像を生成した後の操作
NovelAIではローカルと同じように生成した後も画像を拡大したり、一部を残したまま編集するなど、様々な操作を行うことができます。
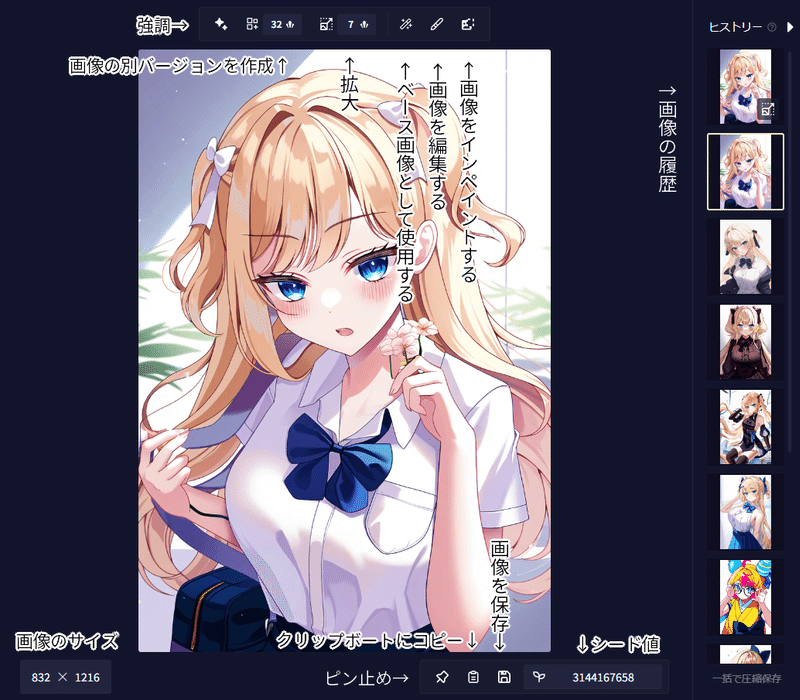
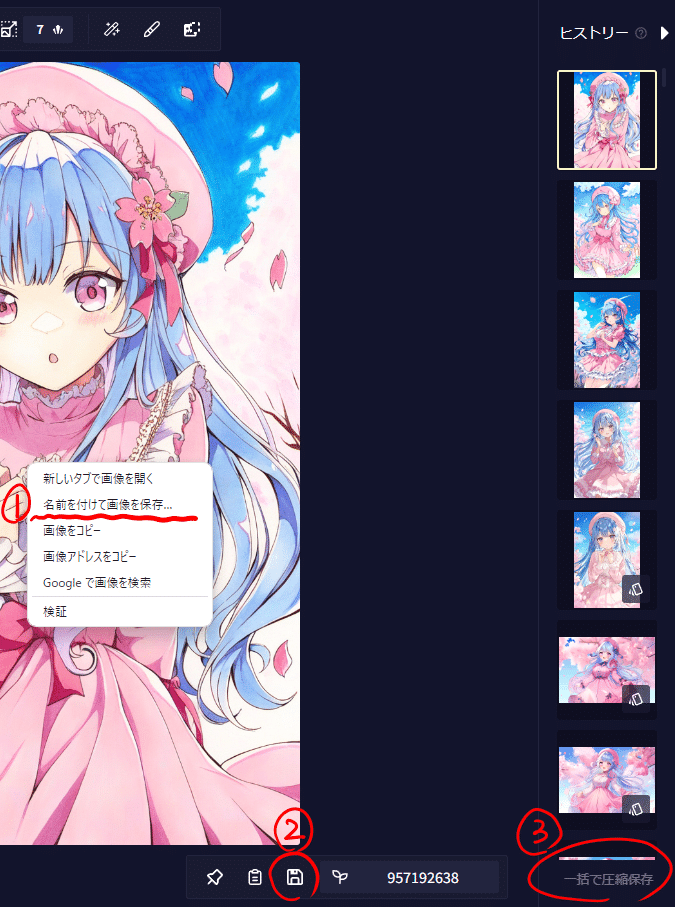
画像の保存
画像の保存の方法は三つあります。どの方法でもプロンプトなどの設定を画像のメタデータに保存しておくことができます。①は右クリックをして「名前を付けて画像を保存」です。②は既存の保存マークを使用する方法です。この方法はファイルの名前がプロンプトになります。(長い場合は途中まで)
③は今まで生成した画像をZIPファイルに圧縮して保存します。
強調
強調は画像サイズを変えずに、あるいは強調する画像の大きさに基づいて1.5~2倍の大きさにしながら画像の雰囲気を変えます。ローカルでいうところの高解像度補助(hires)と同じようなものです。解像度を上げるかは左下から選べます。

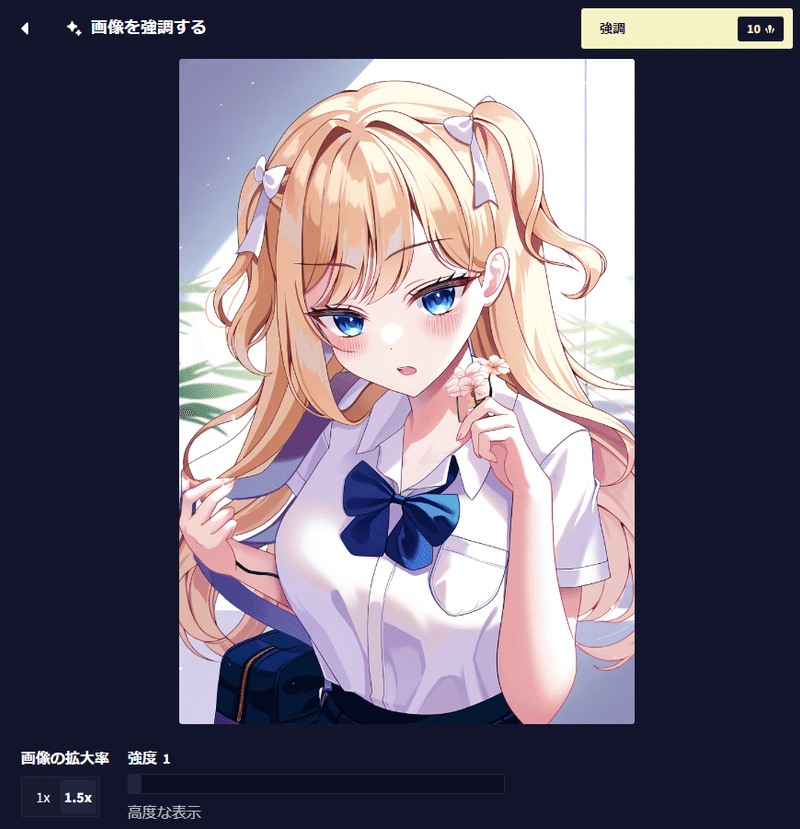
強度は元の絵からどれくらい変更を加えるかを決めます。強度1ではほぼ変わりませんが、強度3くらいになると口元などが変わっているのが分かります。強度5になると口元や目線がやや大きく変わっています。手に持っている花も髪になってしまったため強度を上げればいいわけではないかもしれません。

別バージョンの画像を作成
別バージョンの画像を作成とは生成された画像を元に類似の要素や構図を持つ画像を生成する機能です。ローカルにおけるバリエーションのシードのようなものです。

特に設定はなく上部のメニューから赤枠のボタンを押すだけです。生成が完了すると普通サイズの場合、このようにオリジナルと3枚の画像が生成されます。

拡大
強調よりも画像に変化を与えずに画像の解像度を上げる機能です。ローカルにおけるその他(Extra)とほぼ同じ機能です。拡大後の解像度は左下に表示されます。普通サイズでは4倍の大きさになるようです。

こちらにも追加の設定はありません。赤枠を押すと拡大できます。どのくらいの解像度になったかは絵の左下に表示されます。

ベース画像として使用する
ベース画像として使用するとは現在表示されている画像をもとにして新たに画像を作る機能です。赤枠のボタンから使えます。

赤枠を押すとプロンプト入力欄がこのように変わります。画像に出ている「i2i」は画像から画像を作る初歩的な方法です。(コントロールツールを使用するは次の項で解説します)
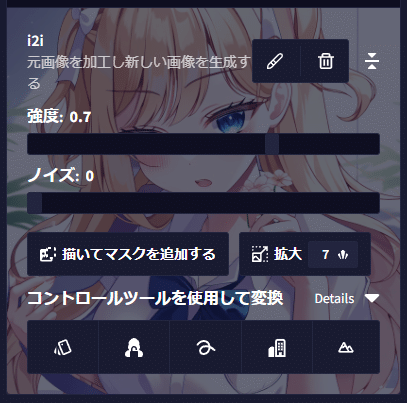
設定としては「強度」と「ノイズ」があります。主に画像の要素を変更するのは「強度」の方です。ただ0.7以上に大きくしてしまうと元画像から変わりすぎてしまうので「ノイズ」を調節するといいでしょう。
強度を0.7に固定し、ノイズを0~0.2まで変化させた例がこちらになります。

ただ、狙ったような変更はできないのでコントロールツールやインペイントを使うことをお勧めします。
コントロールツールの使い方
コントロールツールには以下の五つの形式があります。
()の中はローカルでの名前
・線画を抽出する「カラースワップ」(Lineart)
・奥行情報を取得する「フォームロック」(Depth)
・落書きのような大まかな輪郭線を抽出する「スクリブラー」(Scribble)
・直線を抽出する「ビルディングコントローラー」(MLSD)
・物体ごとに色分けする「ランドスケーパー」(Segmentation)
23年11月24日現在V3でのコントロールネットモデルは登場していません。ですので使う場合はV2モデルが推奨です。
V3に比べればやや劣りますので今回は線画を抽出する「カラースワップ」だけ紹介します。「ベース画像として使用する」を選択後、コントロールツールを使用して変換の一番左を選択します。
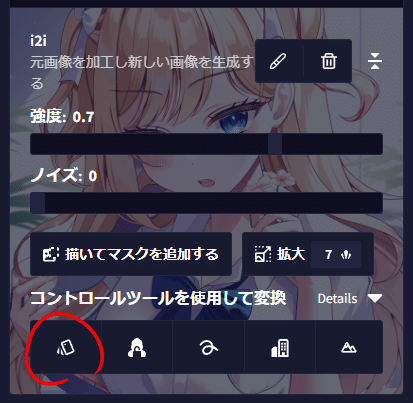
選択すると次のような画面になります。各ボタンは下の画像を参照してください。ツールの影響度は生成画像にどれだけ抽出した線画を意識させるか決めます。ただ1以外だとあまりうまくいかないようです。

また、線画を抽出する前の画像と比較したり、調整メニューを表示をONにするとさらに詳細な設定を表示できます。
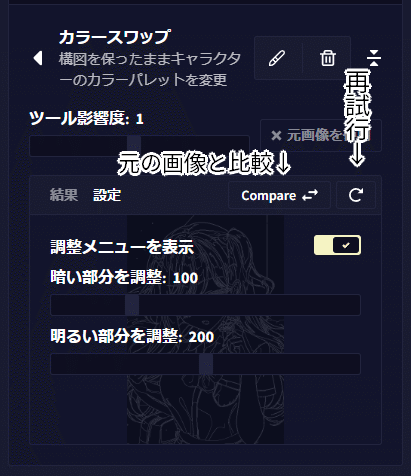
何個か数値をお試ししました。多くの場合、初期値でも問題ないように思えます。しかし、数値を上げると暖色系の柔らかい色になることが多いようです。

画像を編集
画像の編集では簡易のペイントツールです。ただ、無料のペイントソフトよりも機能が少ないので使うことはお勧めしません。

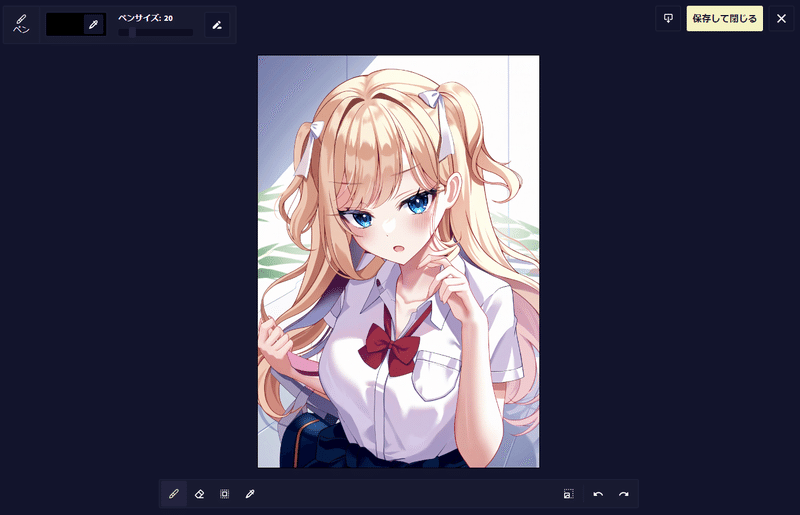
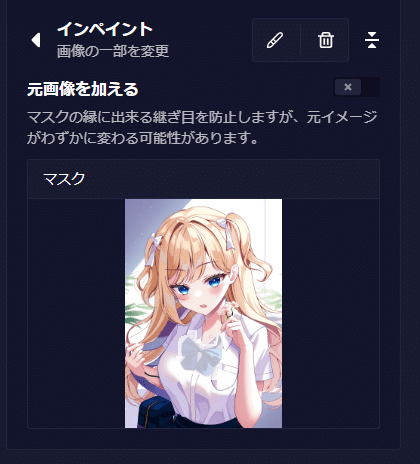
画像をインペイントする
画像の特定の要素を変えるにはインペイントがおすすめです。赤枠を選択するとインペイントで画像のどこを変えるか指定できます。

編集画面はこのようになっています。まず左上のペンサイズでマスクを描くペンのサイズを指定します。水色の枠でマスクを描き、消しゴムマークの紫の枠で消します。黄色の枠で取り消しとやり直しができます。
今回はリボンの色を変えてみたいので青いリボンを変えてみたいと思います。リボンの部分にマスクを塗りましょう。少し大きめに塗るのがコツです。塗り終わったら保存を押します。

保存するとプロンプトの下がこのように変わります。ここでプロンプトに「red ribbon」を加えます。
そのまま生成のボタンを押すとこのようにリボンが赤に変更されます。

下のメニュー
メニューの下の方はこのようになっています。クリップボードのアイコンは他のペン員とソフトに画像を張り付けるときに使用します。画像を保存は画像をダウンロードしてPCやスマホなどに保存するボタンです。
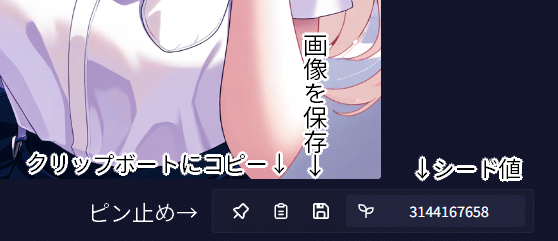
ピン止めとは画像を生成している際にいい画像があったとき一旦その画像がどこに行ったか分からなくならないようにしておく機能です。画像をピン止めすると次のような画面になります。ピン止めを解除する場合はゴミ箱マークを押してください。
ふたばのマークはシード値をコピーする機能です。コピーするとこのようになります。プロンプトの変化量が小さければ似た構図の画像を出すので微調整するときに使用したりもします。

NovelAIの一次創作で学習元と被ることはあるのか?
NovelAI V3はSDXLで学習され非常に高い性能を誇っている反面、画風や特定キャラクターを模倣できることで知らず知らずのうちに既存の作品と被ることがあるのではないかと心配している人もいるかと思います。
私が今までの調査や自作モデルをNovelAIと同じ方法でトレーニングしていた時に実際に検証して確証が得られたデータをもとに以下のような点を知ってもらいたいと思います。(二次創作はそもそも手描きでも親告罪の著作権違反の可能性があるためここでは省きます)
・拡散モデルの中に学習画像は入っていない。
よく聞く話かもしれませんがstableDiffusionは約50億枚を超える画像から学習しているにもかかわらず、2GB程度(SDXLでは6GB程度)に収まっています。この中に学習画像を一枚一枚おさめられていると考えることはできません。実際に画像生成AIが学習しているのは画像の特徴量(ベクトル)に過ぎず、学習元の画像は一枚も入っていません。
・学習された時と全く同じキャプションを入れても一致する画像は出てこない。
私が自作モデルをトレーニングしていた時、類似性のある画像を出力するかどうかを学習時に画像とペアにしたキャプションを一字一句同じプロンプトに入れることでテストしていました。結果ですが一枚たりとも類似性のある画像を発見することはできませんでした。
・一致する絵を出すほど過学習ならすでに発散(ノイズが混じった画像を出すこと)が始まる。
画像生成AIモデルは学習画像を一枚も記憶していませんが類似する画像を出さないわけではありません。DreamBoothなどがそれにあたります。ただし、NovelAIのような大規模学習の際に学習元と一致する画像を出すのはほぼ不可能です。なぜならそのような段階に行く前に専門用語で発散(ノイズが混じった画像を出すこと)が始まるからです。
下の画像は実際にそのような例が起こった時の様子です。多くの場合色味がおかしくなり始めさらに進むと二枚目の右側のように完全に崩壊してしまいます。


・一致するほど過学習ならほぼ全てのプロンプトは無視される。
補足して学習元と一致するほど模倣できるのならプロンプトはほぼ無視されます。NovelAIが様々なプロンプトに対応できているのであれば過学習ではないことが分かります。
また私が作家名+学習されたであろう画像の近似プロンプトで実際に検証した際の結果も貼りますがやはり過学習は確認されませんでした。
やはり、似せようとするのは人間の努力によるものであり一次創作での被りを気にする必要性は無いと言えます。
NAIV3が作家名で画風が寄るといわれてるので作家名+学習されたであろう画像の近似プロンプトで出力してみました。
— かたらぎ@イベント開催中 (@redraw_0) November 16, 2023
左:朔月八雲さん
右:荻poteさん… pic.twitter.com/i3Wh6kdk58
あとがき
NovelAI初心者教本・改を読んでいただきありがとうございます。ほんとはプロンプト辞典を一緒に載せる予定でしたが間に合わず、次回別の記事で公開予定です。お楽しみに~!
この記事が気に入ったらサポートをしてみませんか?