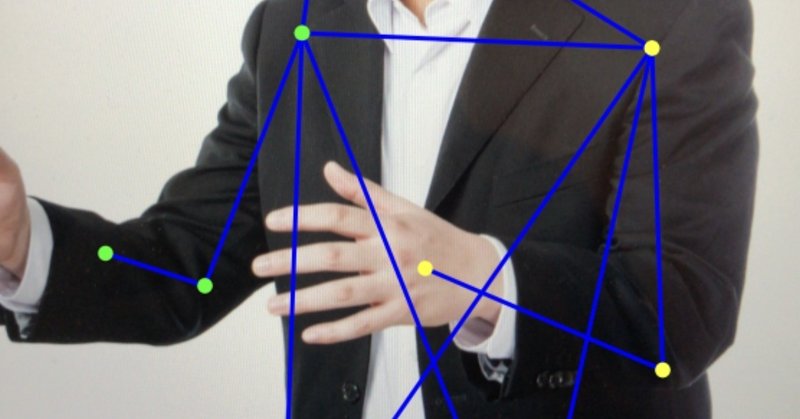
[CoreML]iPhoneで人物の姿勢を推定する

夏季休暇を利用し、CoreML+Kerasを用いてiPhone向けの姿勢推定機能を実装してみました。思いのほか上手く動いたのですが見せる相手がいないのでnoteで成仏させてみようかな~という投稿です。
つくったもの
入力画像から人物の関節位置を推定するDeep LearningモデルをCoreMLを用いてiOS向けに変換し、iPhoneでリアルタイム動作可能な姿勢推定機能を作りました。描画など含め、iPhone8 Plusで10-15fpsで動作します。最近の潮流であるMulti-Personの姿勢推定ではなく、画面内のSingle-Personの姿勢推定を対象としています。
Deep Learningを用いた人物の姿勢推定アルゴリズム
Deep Learningを用いて人物の姿勢(関節の位置座標)を推定するアルゴリズムには大きく分けて2種類の方式があります。
1. 座標回帰による推定
関節の位置座標の値を直接推定する手法です。推定したい関節の数が15箇所であれば、15×(x座標,y座標) = 30の出力ノードを持つニューラルネットワークで構成されます。代表的なアルゴリズムとしてDeepPose[Toshev+2013]が挙げられます。
2. Confidence mapによる推定
信頼度マップの形式で関節の位置を推定する手法です。推定したい関節の数が15箇所の場合、ニューラルネットの出力層はW'×H'×15のテンソルになります。W'×H'のマップがそれぞれ推定したい関節の位置で信頼度の値が強くなるように学習します。マップで推定するため、一つのマップで推定可能な関節の数に制約が無く、複数の人物を同時推定する形に拡張することも可能です。
Single-Personを対象とした代表的なアルゴリズムとしてConvolutional Pose Machine[Wei+2016]が挙げられます。Multi-Personを同時推定可能なアルゴリズムとしてOpenPose[Cao+2017]が挙げられます。OpenPoseは実行速度と精度を兼ね備えており、公開された際には大きな話題になったことが記憶に新しいですね。
姿勢推定モデルの構築と学習
今回の実装では、構造がシンプルで実装しやすい1. 座標回帰による推定に基づく手法を用いました。Confidence mapによる手法は高精度な推定が可能な反面、出力層まである程度の解像度を維持しなければならないため高速化に限界があり、モバイルでの実装に向かないと考えました。
オリジナルのDeep Poseでは座標推定を階層的に行うことで精度を高める工夫がされていますが、今回は1回の推論で推定を行うように簡略化しました。また、画像内での関節の欠損に対応するため、関節が見えているかどうかを判定するためのノードを追加しました。
学習にはKeras2.2.2+Tensorflow1.10.0を使用しました。
モデルの構築
ベースとなるネットワークとしてKerasに標準で定義されているネットワークからInceptionV3を使用することにしました。
#推定したい関節の数
n_joints= 17
# 関節数×x,y座標
n_classes = n_joints * 2
# 面倒なのでKerasで定義済みのネットワークを利用
base_net= InceptionV3(input_shape=(192, 192, 3), weights='imagenet', include_top=False)
# 全結合層に繋ぐための形状変換
x = Flatten()(base_net.output)
# 座標推定用のノード
xreg = Dense(n_classes, activation='relu', name='dense_xreg')(x)
# 関節隠れ判定用のノード
xsig = Dense(n_joints, activation='sigmoid', name='dense_xsig')(x)
# 上記2つの全結合層を出力として設定する
model = Model(inputs=base_net.input, outputs=[xreg, xsig])ロスの定義と学習
関節の隠れに対応するため、ロス関数を定義します。画面内に無い関節は正解として-1などの値を付与することにします。この値をそのまま学習に使ってしまうとうまく推定ができなくなってしまいます。そのため、正解座標がマイナスの値になっている関節は回帰のロス計算から除くことにします。最適化アルゴリズムは、とりあえず適当にAdamを選択しました。
# 画面外にある関節を無視したMean squared error
def masked_mse(y_true, y_pred):
# 正解データが0以上の部分を1.0、その他の部分を0.0とするマスク
mask_true = K.cast(K.greater_equal(y_true, 0), K.floatx())
# MSEの計算にマスクをかける
squared_error = K.sum( K.square(mask_true * (y_true - y_pred)), axis=-1)
masked_mse = squared_error / K.maximum(K.sum(mask_true, axis=-1),1)
return masked_mse
adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.005)
model.compile(loss={'dense_xreg':masked_mse, 'dense_xsig':'binary_crossentropy'}, optimizer=adam, loss_weights={'dense_xreg':0.6, 'dense_xsig':0.4})
# エポックごとに結果を保存するコールバック
mdc = ModelCheckpoint(filepath="hogehoge.hdf5", verbose=1, save_best_only=False)
# データの生成部分train_data_reader()については説明を割愛
model.fit_generator( generator=train_data_reader(), steps_per_epoch=1000, epochs=20, verbose=1, callbacks=[mdc], validation_data=val_data_reader(),
validation_steps=100, class_weight=None, max_queue_size=10, workers=1, use_multiprocessing=False, shuffle=False, initial_epoch=0 )学習画像と正解値のペアを出力する関数(train_data_reader())は、deepposeのchainer実装のリポジトリを参考に作成しました。また、学習データにはMS-COCOを使用しました。この辺りのデータ加工については割愛します。
CoreML形式への変換
学習されたモデルファイルhogehoge.hdf5をcoremltoolsを使ってiOSで実行可能な形に変換します。coremltoolsの使い方についてはチュートリアルが多数公開されているため割愛し、ハマったポイントだけ記載しておきます。
Kerasのバージョン
coremltoolsは2018/08/23時点でKeras2.2系に対応していませんでした。今回はcoremltoolsの実行環境をKeras1.6にすることで問題を回避できました。
独自関数の扱い
ロスに独自の関数を用いたため、書き出したモデルを読み込む際に下記のように明示的に関数を指定する必要がありました。
model = load_model('hogehoge.hdf5', custom_objects={'masked_mse':masked_mse})
iOSアプリの実装
アプリの画像取得部分などはApple公式のサンプルとこちらのリポジトリを参考にさせて頂きました。CoreMLに関連する部分のみコードを記載します。
// モデルの読み込み
// CoreMLモデルは起動時に一回だけ読み込めばよい
class ViewController: UIViewController {
// モデルの読み込み
let model = hogehoge()
....
}// 推論〜結果取得
extension ViewController: AVCaptureVideoDataOutputSampleBufferDelegate {
....
func coreMLRequest(image:UIImage)-> hogehogeOutput {
// モデルへの入力サイズにリサイズし、CVPixelBufferへ変換
let imageSize:CGSize = CGSize(width: 192, height: 192)
let pixelBuffer = image.resize(to: imageSize).pixelBuffer()
// 推論処理
guard let pb = pixelBuffer, let output = try? model.prediction(input_1: pb) else {
fatalError("error")
}
return output
}
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
let uiImage = sampleBufferToUIImage(sampleBuffer: sampleBuffer, with: UIApplication.shared.statusBarOrientation)
let output = coreMLRequest(image: uiImage)
// 関節位置の推論結果
let joints = output.dense_xreg
// 関節の存在有無の判定結果
let jflag = output.dense_xsig
....
}
....
}上記結果をDispatchQueueで描画関数に渡し、描画関数側ではUIBezierPathを用いて推論結果を描画しています。
今後の改善点など
精度について、今回作成したモデルは手先や足先など変化の大きい箇所の推定精度が今ひとつだった印象です。回帰精度を上げるためにCoordConv[Liu+2018]の導入が有効ではないかと考えていますので、次の長期休暇にでも試してみようと思います。
実行速度について、今回はInceptionV3を利用しましたが、ここをより軽量なネットワーク(MobileNetやXceptionなど)に置き換えるだけで1.5〜2倍程度は高速化できるのではないかと思います。
今回は2Dでの姿勢推定でしたが、最近は3Dの姿勢推定アルゴリズムも凄い勢いで研究されています。いずれ3Dもモバイルで動かせるようなアルゴリズムが出てくると夢が広がりますね。
この記事が気に入ったらサポートをしてみませんか?