
POKE´LLMONをできる限り誰にでもわかるように訳してみた。

ノート初投稿です!
ついに出ました。ポケモン ランクバトルのAI botです😱
このAi botの論文[POKE´LLMON: A Human-Parity Agent for Pokemon Battles ´ with Large Language Models](https://arxiv.org/abs/2402.01118)を元ポケモンガチ勢の血が騒いだのと、ちょうどLLMの勉強してるのもあって、訳して箇条書きでまとめてみました!
直訳ではなく、できる限りポケモン用語でまとめるようにしています!
Abstruct
ランクバトルなどの対人戦で人間と同程度の強さを持つLLM Embodied Agent(※1)だよ。
POKE´LLMONには主に三つの戦略が組み込まれてるよ
1つ目はICRL(In-Context Reinforcement Learning )で、バトルから派生したテキストベースのフィードバックを即座に使用して反復的に最適なアクションを選択していくよ
二つ目はKAG(Knowledge-augmented generation)という外部の知識を取得してハルシネーションに対応し、適切にタイムリーにアクションをしていくよ。
三つ目は、強い相手(不利対面で戦闘を回避したい時に)に、連続でポケモンの交代をし続ける「panic switching」という現象が見られたけど、一貫性のある行動を生成する(Consistent action generation)ことで、緩和できるよ。
ランクバトルにて49%、招待した熟練のポケモンプレイヤーに対して56%の勝率で勝つことができたよ。
私たちの作った実装(POKE´LLMON)とバトルログは使うことができるよ https://github.com/git-disl/PokeLLMon
※1:LLM Embodied Agentとは物理的環境やシミュレーション内で行動する能力を持つLLM
1, introduction
LLMが物理的な世界で自律的に行動できるようになるのが、人工汎用知能(AGI)の世界を目指すための重要なパラダイムだよね。
戦術的バトルゲームはLLMのゲームプレイ能力をベンチマークするのに適してて、有名なポケモンゲームはかなり適してるよね。
ポケモン対戦がLLMの評価のベンチマークに的してるユニークな利点は次の3つ。
1つ目は状態(HPやフィールドの状態など)とアクション(選択する技や交代)をテキストに損失なく翻訳できてること。また、アクションは"4つの技"と"交代"の合計5つで構成されてること。
二つ目はターン制バトルは集中的にゲームをプレイする必要がな推論時間コストのストレスが軽減しやすいこと
3つ目は単純な仕組みの割には複雑なこと。ポケモンは1000種類以上存在し、ポケモンごとに異なる特徴を持っていて、ポケモンの知識と推論能力が必要。
この研究の目的はLLM Embodied Agentが優れたポケモントレーナーになるために必要な要因を追求し、人間と対戦して、その強みと弱みを検討すること
この研究では、バトル状態をテキスト説明に解析・翻訳し、生成されたアクションをサーバーに戻す環境を実装した。
そうすると、「ハルシネーション」や「panic switching」現象の存在を知ることができたよ。
ポケモン対戦でいう「ハルシネーション」は悪タイプにエスパータイプの技を出したり、不利なポケモンに交換したりすることを指すよ。「ハルシネーション」はICRL(In-Context Reinforcement Learning )やKAG(Knowledge-augmented generation)によって軽減したよ。
panic switching は、Chain-of-Thoughtを使った時に謙虚だけど、過度に考えることなく最も一貫したアクションを選び出すことにより、問題を軽減できるよ。ストレスの多い状況になるとパニックが起こるのは人間に似てるよね。
オンライン対戦ではランクバトルでは勝率49%、招待したプレイヤーに対しては56%の勝率があるよ。
「どくどく+自己再生」みたいな害悪戦法には弱いです。
2,LLMs as Game Players
人狼のような「コミュニケーションゲーム」、マインクラフト見たいな「オープンエンドゲーム」、ポケモンのような「戦術バトルゲーム」があって、「戦術バトルゲーム」はLLMのベンチマークに適してるよ
3, Background
ポケモンとは何かやポケモンの対戦に関するルールの説明。日本人にとっては義務教育だと思うので、飛ばします。
4,Battle Environment
バトルエンジンはpokemon showdown(※1)を使ってるよ。
対戦環境は[Sahovic, 2023a](https://github.com/hsahovic/poke-env/ blob/master/src/poke_env/player/ baselines.py.)をもとに実装したよ。
(※1)ポケモンのランクバトルが厳選も努力値もなしでパソコン上でできるサービス。 https://pokemonshowdown.com/
5,Preliminary Evaluation
5.1. Pokemon Battles
ポケモンバトルに関連する課題への洞察を得るために、既存のLLMの能力を評価したよ。
LLMと人間のプレイヤーを対戦させると時間かかるから、時間節約するために、[Sahovic, 2023a](https://github.com/hsahovic/poke-env/ blob/master/src/poke_env/player/ baselines.py.)にて実装されている、heuristic botを採用したよ
最初はbot使うけど、後で対人戦でちゃんと評価するよ
このheuristic botはケモンのステータス、技の威力、およびタイプの有利性/弱点を考慮して最も効果的なアクションを選択するようにプログラムされてるよ
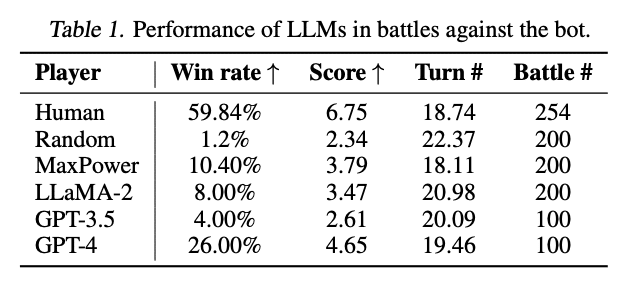
Table1は それぞれのLLMの勝率を表してるよ。
素のLLaMaやGPT-3.5はRandomに毛が生えたような勝率しか出せなかったよ。
Max Powerは一番強いパワーの技を選択し続けるという戦略だよ。
最新のLLMであるGPT-4ですら26%しか勝率ないよ。
5.2. Test of Hallucination
LLMのハルシネーションについても評価してみたよ。
ハルシネーションの評価のために、適切なタイプの相性をLLMが選択できるかを評価してみたよ。

表2は3つのLLMの混同行列で、LLMに対して、あるタイプの攻撃が特定のポケモンのタイプに対してA. 超効果的(2倍以上のダメージ)、B. 標準(1倍のダメージ)、C. 効果がない(0.5倍のダメージ)またはD. 効果がない(0倍のダメージ)かを表してるよ。
LLaMA-2とGPT-3.5は致命的なハルシネーションが起こってるよ。(ほとんどポケモンの相性に関して理解していないように見える)
GPT-4は84.0%の精度で最高の性能を達成していルけど、以前として頻繁に意味のない行動をとってしまうよ。
6,POKE´LLMON
POKE´LLMONについての解説だよ。全体的なフレームワークはFigure5だよ。
POKE´LLMONではICRL(In-Context Reinforcement Learning )とKAG(Knowledge-augmented generation)によって「ハルシネーション」対策してるよ
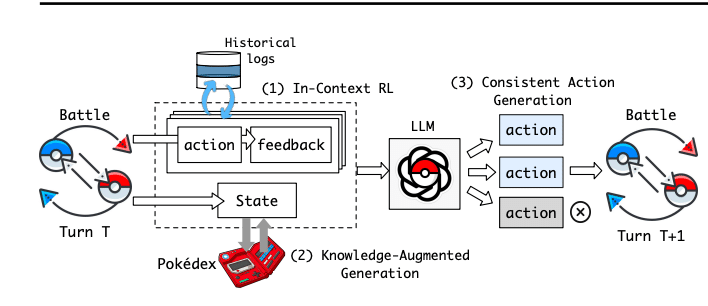
6.1 . In-Context Reinforcement Learning(ICRL)
人間のプレイヤーは、現在の状態だけでなく、次のターンや次の次のターンにわたるポケモンのHPの変化などを、以前のアクションからの(暗黙の)フィードバックに基づいて推測できるよ。
LLM エージェントはフィードバックがないと、何度も同じことを繰り返すよ。(貯水のトリトドンにハイドロポンプを撃ち続ける)
強化学習はアクションを評価するために数値報酬を使うよ。
以前のターンからのテキストベースのフィードバックをコンテキストに組み込むことで、エージェントは反復的かつ即時に「Policy」(※1)を洗練できるようになるよ。これをICRLというよ
具体的には、「1,攻撃技による2ターンに続くポケモンのHPの変化」、「2,攻撃技の有効性(効果抜群/効果いまひとつか)」、「3,素早さによる行動順」、「4,実行された技の実際の効果(ステータス上昇技なのか、HP回復技なのか、状態異常技なのか)」の4つのフィードバックを生成するよ。
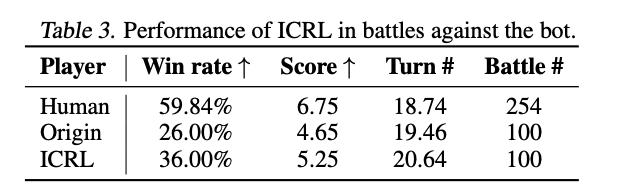
ICRLによって、GPT-4と比べて勝率は10%も増えたよ。
苦手なポケモンに対しては「交代」するようになったよ。
※1 ここでの"policy"は"方針"を意味すると思われる。
6.2 Knowledge-Augmented Generation (KAG)
ICRLでハルシネーションの影響は減らせるけど、フィードバックを貰う前の致命的な結果を引き起こすことがあるよ。(フィードバックのない1ターン目にギャラドスが相手の電気技でやられる的な。ICRLだけでは、1ターン目の選択を評価できない)
このような問題(ハルシネーション)の対策のために、Retrieval-Augmented Generation(RAG)は外部知識を利用して、生成を拡張するよ。
二種類の外部知識を紹介するよ。
1つ目の外部知識はタイプの有利/不利の外部知識だよ。ポケモンと技のタイプ情報をすべて注訳して、LLMエージェントがタイプの有利関係を推測できるようにしたよ。「例:リザードンは草タイプに強いが、水タイプの技には弱い」といった記述を明示的に注約として入れておく。
2つ目の外部知識は、技と能力・特性の効果の外部知識だよ。すべての技と特性などの情報をBulbapedia (bul, 2024b;a)(※1)から得てPokedex(※2)に保存したよ。
バトルフィールド上の各ポケモンについて、その能力と効果はPokedexから取得されるよ
※1 Bulbapedia: https://bulbapedia. bulbagarden.net/wiki/Ability#List_of_ Abilities.
※2 pokedex: https://www.pokemon.com/us/pokedex
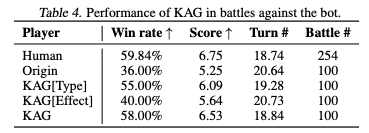
タイプの有利不利(KAG[Type])は勝率を36%から55%に大幅に向上させたよ
技/能力の効果記述も勝率を4%向上させたよ
この二つを組み合わせることでbotに対しては58%の勝率を出せたよ。
外部知識は面白くて「クレッフィ」vs「ドサイドン」のような不利対面でも交換せずに、「でんじふゆう」を選択するなどの選択も選べばれるようになったよ。
KAG(Knowledge-Augmented Generation)??
6.2章のタイトルはKnowledge-Augmented Generationというタイトルだが、
検索してもそのような論文や技法は出てこなかった。ただ、論文本文には
To further reduce hallucination, Retrieval Augmented Generation (Lewis et al., 2020; Guu et al., 2020;
Patil et al., 2023) employ external knowledge to augment generation
とあるし、Retrieval Augmented Generationを使って外部知識を生成するみたいなニュアンスもあるので、RAGを使って蓄えた外部知識のことをKAGと言ってるのかなと思ってます。間違ってたらすいません。
6.3 Consistant Action Generation
既存の研究ではプロンプトエンジニアリングが推論のタスク能力を向上できることを示してたよ。
Chain-of-Thought(Wei et al., 2022)(CoT)、Self-Consistency(Wang et al., 2022)(SC)およびTree-of-Thought(Yao et al., 2023)(ToT)を含む既存のプロンプティングアプローチを評価を評価してみたよ。
CoTでは,エージェントは最初に現在のバトル状況を分析する思考を生成し、その思考に基づいてアクションするよ
SC(k=3)の場合、エージェントは3回のアクションを生成し、最も投票された回答を出力として選択するよ(※1)
ToT(k=3)の場合、エージェントは3つのアクションオプションを生成し、自身で評価した最良のものを選ぶよ。
※1 SC(Self-Consistency)ってCoT + few shot promptingみたいな理解を自分はしてたけど、最も投票された回答って誰が投票するんだろ?論文に例がなかったのでわからなかった。要調査
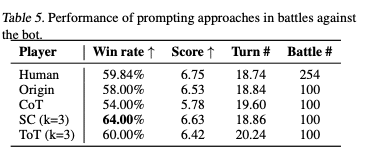
Table 5では三つのプロンプトの手法を比較してみたよ。
CoTは勝率が下がっちゃったよ。
一方で、SCは勝率が上がったよ。
CoTではLLMが強力な相手ポケモン(※2)と対面した時、連続して「交代」する「Panic switing」がみられたよ。

※2 ここでいう「強力なポケモン」とは1,積み技を使ったポケモン、もしくは選択したポケモン全てに対して相性的に有利なポケモンだと思われる。
例:水の一貫性が高いパーティーを選択した時、相手のマリルリに「腹だいこ」を積まれた場合 など?
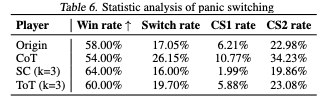
Table6は「Panic switching」の統計的証拠を表してるよ。
CS1は直前の行動が交代だったアクティブな交代の比率、CS2は直近2回の行動のうち少なくとも1回が交代だったアクティブな交代の比率を表してるよ。
CS1の値が高いほど、生成の一貫性が低いといえるよ。
CoTでは連続交代率を大幅に増加させ、SCは逆に減少させてるよ。
CoTによって生成された思考を調べると、パニック感情が含まれていることが観察されたよ。
ストレスフルになる時に、パニックになる人間に似てるよね。
SCによる一貫性のある行動生成は、図5のように複数回独立して行動を生成し、最も一貫性のある行動を選出することで、連続交代率を低下させ、勝利率を向上させるよ。
7,Online Battle
POKE´LLMONは今までは、Botに対する勝率だけど、ついにランクバトルにて人間と対戦したよ。2024年1月25日~26日。
また、15年以上のポケモンゲームの経験を持つポケモントレーナーを一人招待して、一般的な人間との能力も評価したよ
Table 7はランクバトルと招待したプレイヤーと比較したときの勝率だよ
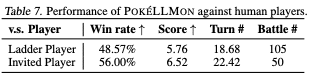
結果としてランクバトルでは50%に近い勝率、招待したプレイヤーに対しては56パーセントの勝率があったよ。
7.2. Battle Skill Analysis
バトルのスキルを評価してみるよ
KAG戦略のおかげで、効果的な技の選択と適切なポケモンへの交代をほとんどミスなく行えたのは良かったよ

図10のように3タテしてやったこともあったよ。(相手に対して適切に技を選択できてる証拠)
POKE'LLMONは人間のような消耗戦術(害悪戦術)も使えるよ。「どくどく + 自己再生」
一方で弱点もあったよ。
POKE'LLMONは短期的な利益をもたらす行動を取りがちであり、長期的な取り組みが必要な人間プレイヤーの消耗戦術(害悪戦術)に対して弱いよ。
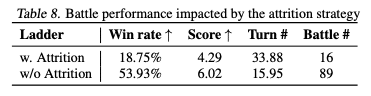
Table 8ではランクバトルにて害悪戦法(w.Attention)と通常の戦法(w/o Attention)との勝率を比較してみたよ。
普通の先方に対しては53%の勝率もあるのに対して、害悪戦法に対しては18%しか勝てなかったよ😭
POKE'LLMONは短期的な利益、例えば一撃で相手を倒す技の優先使用に傾きがちだから、防御を強化して長期的に回復しながらダメージを与えていく消耗戦術には対応できないよ。
だから次のような改善点があると思ってるよ。
1,長期的な目標設定: POKE'LLMONに長期的な勝利ではなく、長期的なダメージ効率や生存時間を評価するように学習させる
2,回復・防御技の活用: 消耗戦術に必要な回復技や防御技の使用状況を分析し、最適なタイミングでの使用を学習させる。
3,対戦相手の行動予測: 相手の行動傾向を分析し、消耗戦術の可能性が高い場合はそれに合わせた戦略を立案するように学習させる
8. Conclusion
本論文では大規模言語モデル (LLM) が人気のポケモンバトルを人間と自律的に戦えるようにしたよ
LLM を用いたエージェントとして初めて、戦略バトルゲームにおいて人間と同等の能力を達成したよ。
POKE'LLMON では 3 つの重要戦略を取り入れたよ。
それはIn-Context Reinforcement Learning(ICRL)とKnowledge-Augmented Generation (KAG)とConsistant Action Generation(要はプロンプトエンジニアリング)だよ。
結果ランクバトルでも勝率が49%もあったよ。
ただ害悪戦法には弱かったし、今後の課題。
まとめ
とうとう出たね。。。
という感想です。
正直まだまだ改善できる余地はたくさんあるので、人間を超えるAIポケモンバトルエージェントが出てくるのは時間の問題だと思ってます。
ただ、技術の進歩を喜ぶ一方、ポケモンのオンライン対戦の環境がbotだらけになるかもしれないので今後はゲーム側でbot対策が必要になってくるかもしれませんね。。
平和で健全なポケモンのオンライン環境が続くことを願ってます。
Reference
[POKE´LLMON: A Human-Parity Agent for Pokemon Battles ´ with Large Language Models](https://arxiv.org/abs/2402.01118)
この記事が気に入ったらサポートをしてみませんか?