
Amazon Bedrockでできること分かりやすくまとめてみた

先週のことですが、2月22日開催のAmazon Innovateに参加してきました!
色々とAWSの生成AIに関して学べたので、備忘録的にAWSのフルマネージドの生成AIプラットフォームであるAWS Bedrockについて分かりやすくまとめていこうと思います。
AmazonBedrockとはなんぞ?
大手 AI 企業が提供する高性能な基盤モデル (FM) を単一の API で選択できるフルマネージド型サービス!
AIスタートアップやAmazonが開発した幅広いFM(Foundation Model)からビジネスに合った生成AIを選択できるよ(ただしOpenAIのGpt3.5やGpt4は使えない)
AWSの既存サービスや機能(Amazon SageMakerおよびSageMaker Pipelinesなど)を使って、簡単にアプリケーションと統合し、デプロイできるよ!
生成AIの課題である「責任あるAI」「コンプライアンス」に配慮!amazon bedrockにあげたデータは学習に使われないし、データの通信時・保管時は全て暗号化されてて安心!
Amazon Bedrockの機能
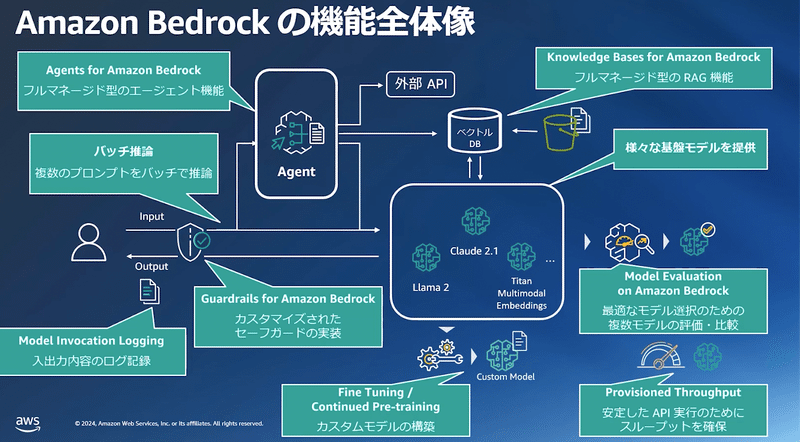
複数の基盤モデルを呼び出し可能なAPI
独自データでのカスタマイズ機能(Fine Tuning)
高いデータセキュリティとコンプライアンス
Agentにより、複雑タスクを分解して実行
Knowledge baseでのRAG機能
Previsioned Throughputによるキャパシティの予約
複数のモデルの評価・比較するための機能を提供
Guardrailsによる、不適切なトピックや個人情報の出力を抑制する機能
Amazon Bedrockで利用できるモデル(一部紹介)
2024/02/27現在の最新のモデルの紹介です。
Claude2.1
洗練された対話、クリエイティブなコンテンツ生成、複雑な推論、コーディング、詳細な指示などで使えるAnthropic開発のモデル。
最新のCalude2.1では20万トークン(約 15 万語、資料 500 ページ超)のコンテキストウィンドウが利用可能!
英語と他の複数言語に対応
Anthropic 社の先進的な安全性研究に基づいており、憲法 AI などの技術を用いて構築されています。ブランドリスクを軽減するように設計されている。
Amazon Titan
Amazonが提供する高性能基盤モデル
高性能の画像モデル、マルチモーダルモデル、テキストモデルにより、コンテンツ作成、画像生成、検索エクスペリエンス、レコメンデーションエクスペリエンスなどさまざまな用途で使える。
データから有害なコンテンツを検出して除去し、不適切なユーザー入力を拒否し、モデル出力をフィルタリングすることで、AI の責任ある使用をビルトインでサポート
検索精度の向上とパーソナライズされたレコメンデーションの改善
独自のデータで微調整して、モデルをカスタマイズできる
stable diffusion XL 1.0
Stabability AI が提供する、最も高度なテキストから画像への変換モデル
3.5B のパラメータベースモデルステージと 6.6B のパラメータアンサンブルパイプラインを備えた、画像生成用 SOTA オープンアーキテクチャが使用されている
最新のStable Diffusion XL 1.0では、プロンプトのトークンの上限 77 個。
Llama2
Meta社が開発したOSSのLLM。
対話型アシスタントチャットやテキスト分類、感情分析、言語翻訳などの小規模なタスクに適している
対応言語は英語のみ
最大トークンは4000
70 億から 700 億のパラメータの範囲で、事前にトレーニングされ、微調整された大規模言語モデル (LLM)
Jurassic
AI21 のジュラシック LLM
質問への回答、テキスト生成、検索、要約など、企業向けの高度なテキスト生成タスクで使用可能
最新バージョンのJurassic-2 Ultraは最大トークンは8192。
英語、スペイン語、フランス語、ドイツ語、ポルトガル語、イタリア語、オランダに対応
各モデルの料金
こちらから現在の正確なモデルが確認できます。
Playground
bedrockのGUI上で簡単に基盤モデルの処理を確認できる機能です。
上記で紹介した、Claude,Amazon Titan, Stable Diffusionなどを簡単に試すことができます。


推論時にパラメータを調整することができます。
例えばchatのパラメータで最もよく調整するのが下記です。
Temerature:低いほど確実な単語のみ採用する
Top P: 出現確率が高い順に並べ合計 P になるまで採用
Top K: 出現確率が高い上位 N 個から採用する
Length: 出力長を制限
Stop sequences: この文字列が出たら生成を停止する
Bedrock API
その名の通りBedrockのAPIです。
次のようなコードで簡単にbedrockの機能を使うことができます。
このコードではamazon.titanモデルを使ってblogを書いてもらってます。
# If you'd like to try your own prompt, edit this parameter!
prompt_data = """Command: Write me a blog about Pokemon.
Blog:
"""
try:
body = json.dumps({"inputText": prompt_data})
modelId = "amazon.titan-tg1-large"
accept = "application/json"
contentType = "application/json"
response = bedrock_runtime.invoke_model(
body=body, modelId=modelId, accept=accept, contentType=contentType
)
response_body = json.loads(response.get("body").read())
print(response_body.get("results")[0].get("outputText"))
except botocore.exceptions.ClientError as error:
if error.response['Error']['Code'] == 'AccessDeniedException':
print(f"\x1b[41m{error.response['Error']['Message']}\
\nTo troubeshoot this issue please refer to the following resources.\
\nhttps://docs.aws.amazon.com/IAM/latest/UserGuide/troubleshoot_access-denied.html\
\nhttps://docs.aws.amazon.com/bedrock/latest/userguide/security-iam.html\x1b[0m\n")
else:
raise error結果はこちらです。
Pokemon has been a cultural phenomenon for over 25 years, captivating millions of fans around the world. The franchise began with the release of Pokemon Red and Blue in 1996 and has since grown to include a vast array of games, movies, TV shows, and merchandise.
At its core, Pokemon is a role-playing game where players travel through a fictional world, collecting and training various Pokemon species to battle against each other. Each Pokemon has its own unique abilities, strengths, and weaknesses, and players must strategically choose their team to overcome challenges and complete quests.
One of the most appealing aspects of途中で文章が途切れてしまってますが、文章は作成できています。
apiのチュートリアルはAmazon Innovateのチュートリアルがすごく分かりやすかったので、参考にしてください
Model Custamization
2023年11月28日よりBedrockでFine tuningとContinued pretraining(プレビュー)ができるようになった。
参考:Amazon Bedrockでモデルをカスタムして偉大なミュージシャンを降臨させた(?)話
Fine tuning
FinetuningはLLMを特定のタスクに特化させるケースで使われる手法。
特定のタスクとは、例えば、「LLMが選択肢から選ぶようにする」、「語尾に'にゃん'をつけるようにする」など。
Finetuningはラベル付きデータを使って学習させる。学習データは比較的少量での学習が可能
対応モデル:Meta Llama 2, Cohere Command Light, Amazon Titan Text
Continued pretraining
持ち合わせていない知識、例えば特定の業界での用語や慣習、常識などを新しい知識として覚えさせることに特化した学習方法。
例えば、金融業界の用語に関する知識などを追加させたいユースケースで、その場合、財務レポートとアナリストレポートを学習データとして追加する必要があります。
学習にはラベルは必要ないが、比較的大量のデータが必要なようです。
事前トレーニングの継続に備えて、今度も、データセットを JSON Lines 形式に変換し、Amazon S3 にアップロードしてあります。ラベル付けされていないデータを扱っているので、各 JSON 行にはプロンプトフィールドのみが必要です。最大 100,000 件のトレーニングデータレコードを指定でき、通常は少なくとも 10 億個のトークンを供給すると有効性が確認できます。
対応モデル:Amazon Titan Text
料金について
下記で料金が発生します。
学習:料金はモデルによって学習時に処理されるトークン数(学習データ全体のトークン数×エポック数)
モデルのストレージ容量:モデルごとに月単位で料金が発生
またModel customizationで作成したカスタムモデルは、後述のProvisioned Throughputでのみ利用可能なので注意
その際、Provisioned Throughputをコミットメント期間無しで利用できるのは1モデル・ユニットまでだそうです。
Knowledge Base for Amazon Bedrock
Amazon Bedrockで簡単に検索拡張生成 (RAG) を実装する機能!
RAGとは外部に保存した知識(ナレッジベース)をLLMが検索できるようにする仕組みのことで、下記図のように、Amazon bedrockがベクトルDB(ナレッジベース)から関連する情報を取得して、LLMに渡して回答を生成することで、LLMの知らないことでも、回答できるようになります。
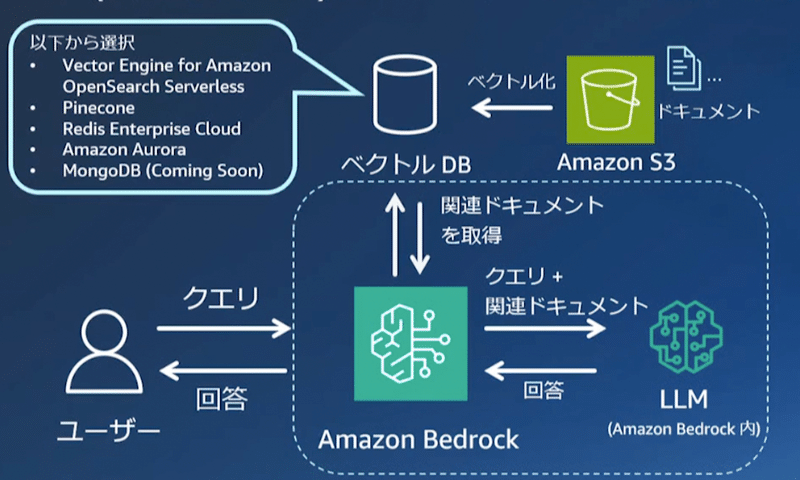
ナレッジベースの作成の流れ
簡単に流れだけ紹介。
1,回答生成時に参照させたいドキュメントのファイル一式を、S3にデータソース(図中のData Source)として登録
2,ドキュメントをチャンクに分割(Splitting int chunks)
3,埋め込みモデル(Embedding Model)を用いてベクトル変換(Generating Embeddings)
4,その結果をベクターDBに保存

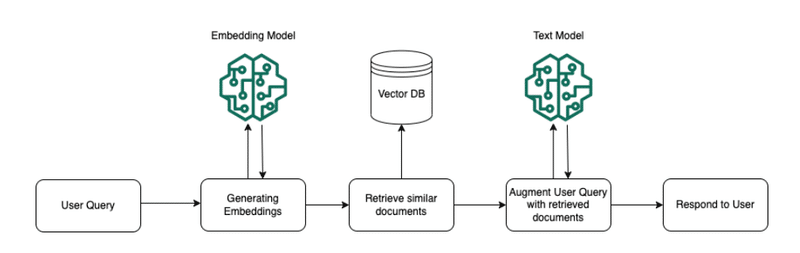
質問から回答の流れ
1,ユーザの質問(User Query)を受け取ったら、前処理に使ったのと同じ埋め込みモデル(Embedding Model)を用いて質問をベクトル変換(Generating Embeddings)
2,質問文のベクトルと前処理で構築したベクターDBにあるベクトルたちと比較し、質問文に近いドキュメントを取得(Retrieve similar documents)
3,文章モデル(Text Model)は、この引き当てられたドキュメントとユーザの質問文を拡張して(Augment User Query with retrieved documents)、ユーザへの応答を生成し、返す(Respond to User)
Bedrock Knowledge baseの価格
Knowledge base自体に料金はないですが、Embedding処理や質疑応答時に使用したLLMモデルの入出力トークン数によって課金されます。
Agent for Amazon Bedrock
処理を自分で判断して実行(オーケストレーション)してくれるエージェントを作成する機能。
次のようなことができます。
ユーザーの入力の意図を汲み取り、必要であればAPIを呼び出して、その結果を元に回答を生成する
用意された Knowleage base を検索して、その結果を元に回答を生成する

例えば、今日の天気を答えてくれるchatbotの生成アプリを構築する場合、
生成AIは今日の天気を知る必要があります。
そうなると、今日の天気を知る必要がありますが、Agent for Amazon Bedrockを使うことで、「今日の天気を教えて」と言ったユーザーの質問を理解して、事前に登録された適切なAPI(今回の場合天気予報 API)を呼び出し、今日の天気を取得ができるようになります。
Agentが使うAPI(実際にはLambda)はAction groupという単位で簡単に登録することができます。
サポートされてるリージョン:US East (N. Virginia),US West (Oregon)
サポートされてるモデル:Claude v2.0
Model Evaluation on Amazon Bedrock
複数の基盤モデルをコードなしで比較・評価することができる機能です。
評価方法は自動評価(Automatic Evaluation)と人間評価(Human Evaluation) の二種類から選択できて、自動評価の場合、要約などのタスクを選択しビルトイン、もしくは自前のデータセットで評価します。人手評価の場合、自前のチームか AWS にお願いして人を集めてデータセットに対し評価することができます。


Guardrails for Amazon Bedrock
基盤モデルの不適切な入出力をブロックして、責任あるAIの構築を手助けする機能です。
ファインチューニングされたモデルを含む全てのAmazon Bedrock上のモデルに適用可能です。
次のようなガードレールを定義できます。
拒否トピック:その名の通り特定のトピックの拒否。拒否したいトピックや説明が必要なトピックをあらかじめ指定しておくことで、「そのトピックについては説明できません」といった定型的なレスポンスを返させることができます。
コンテンツフィルター:憎悪、侮辱、性的、暴力のカテゴリにわたって有害なコンテンツをフィルタリングするための閾値を設定できるコンテンツフィルタ
Pllリダクション:ユーザー入力とFM応答に含まれる個人識別情報 (PII) を検出できます。ユースケースに応じて、PIIを含む入力を選択的に拒否したり、FM応答のPIIを編集したりできます。たとえば、コールセンターで顧客とエージェントの会話記録から要約を生成しながら、ユーザーの個人情報を編集ができる。(Comming soon)
ワードフィルター:おそらく特定のワードを省くことができるフィルター。(Comming soon)
言語:英語コンテンツのみ
サポートされてるリージョン:US East (N. Virginia),US West (Oregon)
Provisioned Throughput
Bedrockの料金体系の一つです。
Bedrockの料金体系は次の2つに分けられます。(fine tuningは一度除いています)
On-Demand
使用した分だけ料金が発生
テキストの場合トークン数、画像の場合は画像毎数枚に料金が発生
Provisioned Throughput
モデル・ユニットごとに1時間あたりで料金が発生
コミットメント期間に応じて料金が変動する仕組み(無し、1ヵ月、6ヵ月)
特定のベースモデル、または後述するカスタムモデル用に予約されたスループットをモデル・ユニットとして購入可能
ベースモデルはカスタムされていないモデルという意味
モデル・ユニットは、1分間に処理される入力または出力トークンの最大数によって測定される一定のスループットを提供
通常のOndemandの場合は1分あたりのリクエスト数およびトークン数に上限があります。
Provisioned Throughputではあらかじめ、モデルユニット(1分間に処理可能な入出力トークン数)を購入することで一定のスループットを確保します。
これによりトラフィックが急増に増加した場合でも一定のスループットを確保できます。
購入は1ヶ月または6ヶ月のコミット期間付きで購入できます。
こちらは少し古いですが、料金の参考値です。

対応モデルはAmazon Titan ,Claudeのみとなります
バッチ推論
複数のプロンプトを非同期にバッチ推論することができます。
定期的なオフラインでの推論やRAGなどの用途での埋め込みベクトルの一括作成で使えます。

終わりに
amazon bedrockでできることについてまとめました!
OpenAIのGPT4が強すぎてそれが使えないのが、けっこう大きなデメリットですが、GPT4レベルのスペックが必要ない生成AIシステムの構築だったら、当然他のAWSのシステムと連携しやすいので、良いサービスだなと思いました。
時間があればもっと色々ハンズオンやっていきたいと思ってます。
参考
Amazon Bedrockでモデルをカスタムして偉大なミュージシャンを降臨させた(?)話
OpenAIのGPTシリーズとBedrockのClaudeをコスト比較してみた
Amazon BedrockのKnowledge baseで簡単にRAGを構築
この記事が気に入ったらサポートをしてみませんか?