RAG DAY1 Tutorial

「 LLMに専門的な知識を持たせてぇ」
ChatGPTを代表としたLLMがビジネスで使われるようになり、様々なチャットボットが開発されてきました。
しかし、そういったChatbotをビジネスで使用するには「社内独自のマニュアルやルール」、「医学・薬学などの専門知識」、「LLMが知らない最新のニュース」などLLMが知らない知識を答えてほしいというニーズが生まれてきます。
しかし、fineTuningは知識を覚えさせるのが難しく、LLM全体の事前学習は並の会社には手に負えるようなものではありません。
そんな中で、外部知識を検索してその検索結果を元にLLMに回答させる手法である"RAG"は最近注目されてきて、様々な手法やテクニックが日々論文などで発表されています。
そこで、今後RAGが来るのではと思い本腰を入れて、色々論文や参考文献を読んで勉強進めてきました。
勉強を始めて2週間。RAGの理解が自分の中で進んできたので、数日に分けてRAG周りの様々な技法やテクニックをソースコードに落とし込んでいきます!
DAY1でやること
・RAGの全体像の紹介
・LangChainを使ったRAGの実装チュートリアル
RAGとは
RAGとは外部知識を検索してその検索結果を元にLLMに回答させる手法で
検索して(Retrieval)、プロンプトに情報を追加して(Augmented)、生成する(Generation)の略称をとってRAG(ラグ)と呼ばれています。
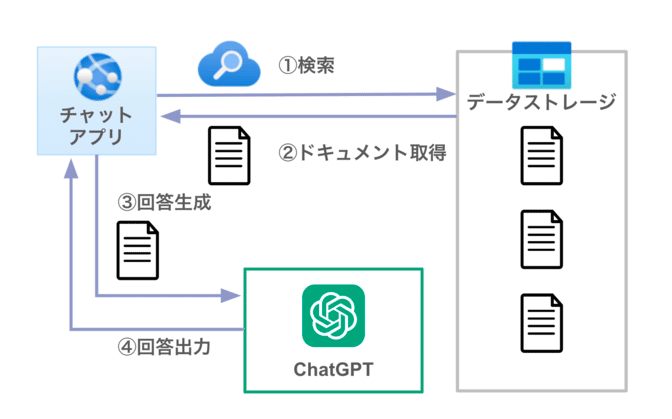
RAGの仕組みを簡単に説明すると、まず質問に関連しそうな情報をデータストレージとなるvectorstoreから検索しドキュメント取得します。
そのドキュメントをcontextとしてLLMに渡して、LLMはそのドキュメントを元に回答します。これが一連のRAGの流れとなります。
RAGの流れ
参考:Q&A with RAG
コード実装に行く前に、もっと細かくRAGの処理の流れを見ていきます。
Vectorstoreの構築
まずRAGでQAボットを作るには、データストレージとなるvectorデータベースを作成する必要があります。
Vectorstoreを構築するために、次の四つの手順を踏みます。

Load:外部知識として持っておきたいドキュメントをloadします。
Split:LLMのinputサイズ(トークン数)は無限ではないので、ドキュメントを分割しておく必要があります。
Embed:分割されたテキストデータを ベクトル化 します。
Store:ベクトル化されたデータを保存します。
検索と回答の生成

Retrieve:質問に関係するドキュメントの検索をします。ドキュメントの検索にはベクトルのコサイン類似度などの類似度測定法を使用します。
Generate:質問とRetrieveで取得したデータを含むプロンプトを使用して質問に回答します。
LangChainでRAGを実装していく
言葉で見ていくよりも早速LangChainを使ってRAGを構築していきます
今回はChatgptで作成した社内ドキュメントを模したドキュメントを複数作成したので、DirectoryLoaderで読み込んでいきます。
ソースコードやdatasetはgithubにあるので、そこから確認きます。
Document Loader
from langchain_community.document_loaders import DirectoryLoader
loader = DirectoryLoader("社内wikiデータセット/架空ブラック社内wiki/社内共通/", glob="**/*.txt",recursive=True)
raw_docs = loader.load()
print("ドキュメントの数:",len(raw_docs))
print(raw_docs[0])ドキュメントの数: 5
page_content='# 社宅・寮管理規程\n\n## 第1条(目的)\n\nこの規程は、社員の居住のために会社が所有する社宅または寮および会社名義で借り上げた社宅または寮の管理運営に関する事項を定めたものである。\n\n## 第2条(入居資格)\n\n社宅への入居資格は、配偶者または同居する家族がいる社員とする。\n\n寮への入居資格は、独身者であって自宅から通勤困難な社員とする。\n\n## 第3条(入居への申し込み)\n\n1. 社宅または寮への入居を希望する社員は「社宅・寮入居申込書」に必要事項を記入の上、所属長を経由して漆黒 花太郎へ申し込むものとする。\n\n2. 社宅または寮への入居を許可された社員は、直ちに「社宅・寮入居誓約書」を会社に提出しなければならない。\n\n## 第4条(借上社宅・寮)\n\n社宅または寮への入居希望があるにもかかわらず、入居可能な社宅または寮がない場合は、民間の賃貸住宅を社宅または寮として借り上げることがある。\n\n## 第5条(借上社宅・寮の手配)\n\n借上社宅または寮の手配は会社が行い、家主との間に契約を締結する。\n\n## 第6条(借上社宅の間取り)\n\n借上げ社宅または寮として利用する住宅の間取りは次の区分による。\n\n子がいる場合:3DK\n\n配偶者のみの場合:2DK\n\n独身者:1K\n\n前項の規程に関わらず、扶養家族等の人数により間取りを変更することがある。\n\n## 第7条(借上社宅・寮の家賃限度額)\n\n借上げ社宅または寮の家賃限度額は、次の通りとする。\n\n子がいる場合:100000円\n\n配偶者のみの場合:50000円\n\n独身者:0円\n\n前項の家賃限度額を超過した場合、その超過分については入居者が負担する。\n\n## 第8条(社宅の使用料)\n\n会社所有の社宅または寮の使用料は次の通りとする。\n\n社宅:120000円\n\n寮:80000円\n\n中途入居、中途退去の場合で1か月に満たないときは、日割計算による。\n\n## 第9条(入居資格の喪失)\n\n社宅入居者が次の各号のいずれかに該当した場合は、入居資格を喪失し、会社が定める期日までに社宅から退去するものとする。\n\n1. 退職\n\n2. 会社に無断で定められた入居者以外の者を居住させた場合\n\n3. その他この規程に違反し、会社が社宅に入居させることを妥当でないと認めた場合\n\n入居者は社宅を退去する場合の現状回復の義務を負うものとする。\n\n## 第10条(禁止事項)\n\n社宅入居者は会社の事前の承諾なくして次の各号に定めることを禁止する。\n\n1. 社宅の転貸をすること\n\n2. 定められた以外の者を同居させること\n\n3. 社宅を他の目的に使用すること\n\n4. 社宅の増改築、模様替え、施設及び敷地の現状を変更すること\n\n## 第11条(損害賠償)\n\n社宅入居者が故意または過失により、建物を破損または建物の全部若しくは一部を滅失させたときは、入居者の負担により修理修繕し、またはその損害を賠償するものとする。\n\n## 第12条(施行)\n\nこの規程は令和04年04月12日から施行する' metadata={'source': '../datasets/company_documents_dataset_1/規定及び規則/社宅管理規定.txt'}LangchainのDocument Loaderは.txtファイルをはじめWebページ・pdfなどからドキュメントを読み込みができます。
Loaderから生成されるDocumentインスタンスには、ベクトル化されるドキュメントの元であるpage_content属性と、filter検索などで使用できるmetadata属性を持ちます。
LangChainのLoaderには次のようなLoaderがあります。
・CSVLoader
・DirectoryLoader
・UnstructuredHTMLLoader
・JSONLoader
・UnstructuredMarkdownLoader
・PyPDFLoader
Text Split
LLMのinputサイズ(GPT3.5 Turboは4097トークン)の問題などで、Loadしたテキストをそのまま使うのは難しいので、テキストを分割します。
テキスト分割と言えば、簡単に聞こえますが、RAGの構築する上で一番重要な要素にもなります。
というのも例えば、
今日のご飯はお味噌汁。明日のご飯はオムライス。という文章があったとして、これを分割した時に
文章1:今日のご飯はお味噌汁。
文章2:明日のご飯はオムライス。となればいいのですが、分割がうまくいかないと次のようになってしまい意味が伝わりません。
文章1:今日の
文章2:ご飯はお味
文章3:噌汁。明日のご
文章4:飯はオムライス。LLMに文章を渡すときは意味が伝わる一つの文章としてコンテキストに渡す必要があります。
今回は、MarkdownHeaderTextSplitter + RecursiveCharacterTextSplitterの二つを使ってテキストを分割します。
コードは次のようになります。
from langchain.text_splitter import MarkdownHeaderTextSplitter,RecursiveCharacterTextSplitter
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on,
return_each_line=False,#行ごとに分割するか
strip_headers = False #headerを削除するか
)
docs = []
for raw_doc in raw_docs:
source = raw_doc.metadata["source"]
spilited_docs = markdown_splitter.split_text(raw_doc.page_content)
for doc in spilited_docs:
doc.metadata["source"] = source#metadataにフォルダのパスを加える
docs = docs + spilited_docs
markdown_splited_docs = docs
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 300,#チャンクサイズ
chunk_overlap=50#重複を許容するチャンクサイズ
)
docs = text_splitter.split_documents(docs)
for doc in docs:
print("【page_content】")
print(doc.page_content)
print("【metadata】")
print(doc.metadata)
print("-"*180)
print("markdown分割後のドキュメントの数:",len(markdown_splited_docs))
print("RecursiveCharacterTextSplitterで分割後のドキュメントの数:",len(docs))【page_content】
# 社宅・寮管理規程
## 第1条(目的)
この規程は、社員の居住のために会社が所有する社宅または寮および会社名義で借り上げた社宅または寮の管理運営に関する事項を定めたものである。
【metadata】
{'Header 1': '社宅・寮管理規程', 'Header 2': '第1条(目的)', 'source': '../datasets/company_documents_dataset_1/規定及び規則/社宅管理規定.txt'}
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
【page_content】
## 第2条(入居資格)
社宅への入居資格は、配偶者または同居する家族がいる社員とする。
寮への入居資格は、独身者であって自宅から通勤困難な社員とする。
【metadata】
{'Header 1': '社宅・寮管理規程', 'Header 2': '第2条(入居資格)', 'source': '../datasets/company_documents_dataset_1/規定及び規則/社宅管理規定.txt'}
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
省略
markdown分割後のドキュメントの数: 92
RecursiveCharacterTextSplitterで分割後のドキュメントの数: 102outputから元々は5つだったドキュメントが最終的には102個に分割されているのがわかります。
今回はMarkdownHeaderTextSplitterを使っていて、Markdownのヘッダーごとに文章を分割するようにしています。
また、その後再帰的な分割ができるRecursiveCharacterTextSplitterを使い、大きすぎる文章をさらに分割するように工夫しています。
再帰的な分割とはchunk_size引数で指定したトークン数になるまでseparators引数で指定した文字で順番に分割していきます。
separators引数ではデフォルトでは["\n\n", "\n", " ", ""]が指定されていて、
"\n\n"で分割して、まだchunk_size以下にならなかったら次は"\n"で分割する
といった処理です。
また,metadataに情報の取得元となる'source'を追加しました。
metadataは自分でカスタマイズすることが可能です。
Embedding
from langchain.vectorstores import Chroma
from langchain.embeddings.openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(persist_directory="./vecstore/index", documents=docs, embedding=OpenAIEmbeddings())分割したトークンをベクトル化してvectorstoreとして保存します。
OpenAIEmbeddingではデフォルトでは"text-embedding-ada-002モデル"が使用されます。
何のモデルでベクトル化するかはRAGの精度を左右させます。
OpenAIでは次のようなEmbeddingモデルを提供しています。
当然EmbeddingモデルはOpenAI以外からの選択肢もたくさんあり、Huggingfaceなどで探すことができます。
Hugging faceのEmbeddingモデルはHuggingFaceEmbeddingsなどでload可能です。
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-base")また、ベクトルを保管するのにvectorstoreを利用しています。
chroma,FAISS,lanceなどのvectorstoreがありますが、今回はChromaを使ってます。
また引数でpersist_directory="./vecstore/index"と指定していますが、これによって、vectorstoreを指定したpathに保存することができます。
OpenAIのembdingの場合、ベクトル化にお金がかかるので、一度ベクトル化して同じものを使うならば、保存しておくことをお勧めします。
similarity_search
ちゃんとベクトルで検索できるか確認しましょう。
question = "社長の名前"
vectorstore = Chroma(persist_directory="./vecstore/index", embedding_function=OpenAIEmbeddings()) #vectorstoreを読み込み
result_docs = vectorstore.similarity_search(question,k=3)
for doc in result_docs:
print(doc)page_content='### 社長 \n漆黒 花太郎(しっこく かたろう)' metadata={'Header 1': '株式会社架空ブラック 会社情報', 'Header 2': '会社概要', 'Header 3': '社長', 'source': '../datasets/company_documents_dataset_1/マニュアル/会社情報.txt'}
page_content='## 社長のプロフィール \n### 名前 \n漆黒 花太郎(しっこく かたろう)' metadata={'Header 1': '株式会社架空ブラック 会社情報', 'Header 2': '社長のプロフィール', 'Header 3': '名前', 'source': '../datasets/company_documents_dataset_1/マニュアル/会社情報.txt'}
page_content='# 第4条(役職手当) \n## 1. 役職手当は、次の金額とします。 \n部長:50,000円 \n課長:10,000円' metadata={'Header 1': '第4条(役職手当)', 'Header 2': '1. 役職手当は、次の金額とします。', 'source': '../datasets/company_documents_dataset_1/規定及び規則/給与規則.txt'}社長の名前に関連しそうなdocumentが取れているのがわかります。
similarity_searchではコサイン類似度を使って類似するドキュメントを検索しています。
Search and Generate
やっと下準備ができたので、ドキュメントを検索して、そのドキュメントをもとにChatGPT3.5で回答します
from langchain.retrievers import RePhraseQueryRetriever
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.callbacks import get_openai_callback
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
question = "社長の名前は?"
prompt = PromptTemplate(
input_variables=["context","question"],
template="""以下の参考用のテキストの一部を参照して、Questionに回答してください。もし参考用のテキストの中に回答に役立つ情報が含まれていなければ、分からない、と答えてください。
{context}
Question: {question}
Answer: """
)
llm = ChatOpenAI(model_name="gpt-3.5-turbo",temperature=0)
llm_chain = LLMChain(llm=llm, prompt=prompt)
vectorstore = Chroma(persist_directory="./vecstore/index", embedding_function=OpenAIEmbeddings())
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever,
chain_type="stuff",
return_source_documents=True,
verbose=True,
chain_type_kwargs={"prompt":prompt})
with get_openai_callback() as cb:
result = qa_chain({"query": question})
print("【質問】:",result["query"]," 【回答】:",result["result"])
print("")
print("【回答に使用したドキュメント】")
if result.get('source_documents'):
for source in result['source_documents']:
print(source)
print("")
print("【トークン数】")
print(cb)> Entering new RetrievalQA chain...
> Finished chain.
【質問】: 社長の名前は? 【回答】: 漆黒 花太郎(しっこく かたろう)
【回答に使用したドキュメント】
page_content='### 社長 \n漆黒 花太郎(しっこく かたろう)' metadata={'Header 1': '株式会社架空ブラック 会社情報', 'Header 2': '会社概要', 'Header 3': '社長', 'source': '../datasets/company_documents_dataset_1/マニュアル/会社情報.txt'}
page_content='## 社長のプロフィール \n### 名前 \n漆黒 花太郎(しっこく かたろう)' metadata={'Header 1': '株式会社架空ブラック 会社情報', 'Header 2': '社長のプロフィール', 'Header 3': '名前', 'source': '../datasets/company_documents_dataset_1/マニュアル/会社情報.txt'}
page_content='# 第4条(役職手当) \n## 1. 役職手当は、次の金額とします。 \n部長:50,000円 \n課長:10,000円' metadata={'Header 1': '第4条(役職手当)', 'Header 2': '1. 役職手当は、次の金額とします。', 'source': '../datasets/company_documents_dataset_1/規定及び規則/給与規則.txt'}
page_content='### 従業員数 \n約50名' metadata={'Header 1': '株式会社架空ブラック 会社情報', 'Header 2': '会社概要', 'Header 3': '従業員数', 'source': '../datasets/company_documents_dataset_1/マニュアル/会社情報.txt'}
【トークン数】
Tokens Used: 247
Prompt Tokens: 225
Completion Tokens: 22
Successful Requests: 1
Total Cost (USD): $0.0003815outputのように質問に対して、回答ができているのがわかります。
コードの重要な点を見ていきます。
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever,
chain_type="stuff",
return_source_documents=True,
verbose=True,
chain_type_kwargs={"prompt":prompt})RetrievalQAとはRAGの構築を簡単にできるようにするためのモジュールです。
引数にcontextを元に質問に答えるためのllmや文章検索の結果であるretrievalを渡すだけで簡単にRAGが構築できます。
retriever = vectorstore.as_retriever(search_kwargs={"k": 4})rertieverとはベクトルストアから類似度に基づいてドキュメントを検索するためのオブジェクトです。langchainではretrieverオブジェクトを使って文章検索を簡単に行うことができます。
引数のsearch_kwargs={"k": 4}は取得するドキュメントの数の指定です。
社内ドキュメントなどはk:10くらいは必要だと言われています。
with get_openai_callback() as cb:Tokens Used: 247
Prompt Tokens: 225
Completion Tokens: 22
Successful Requests: 1
Total Cost (USD): $0.0003815コールバックを指定するとllmで使用したコストやトークン数を確認することができます。
RAGの様々な技法と全体像
ここまでが基本的なLangChainを実装したRagの実装でした!
これだけでもある程度の文章検索はできるのですが、精度的には5割行けばいい方で、まだビジネスで使い物になるとは言えません。
とはいえ、LLMに専門知識を持たせたいと思う人はたくさんいて、
精度を良くするための様々な手法が生み出されています。
こちらは昨今のRAGの技法をまとめてくださっているものです。
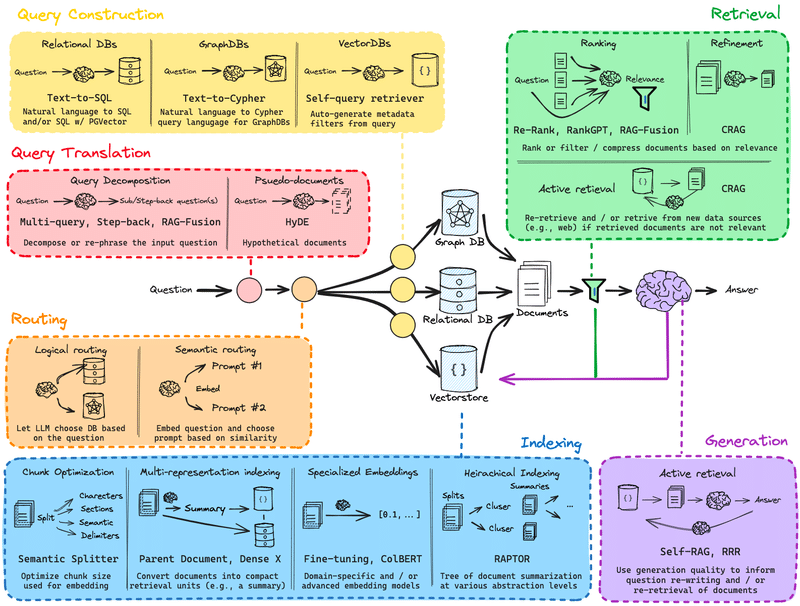
次回からは、ここにある様々な技法をソースコードに落とし込んで試していきたいと思っています!
ここまで読んでくださった方ありがとうございました!
Reference
LLMアプリケーション開発のためのLangChain 後編⑤ 外部ドキュメントのロード、分割及び保存
https://github.com/langchain-ai/rag-from-scratch/blob/main/rag_from_scratch_1_to_4.ipynb
この記事が気に入ったらサポートをしてみませんか?