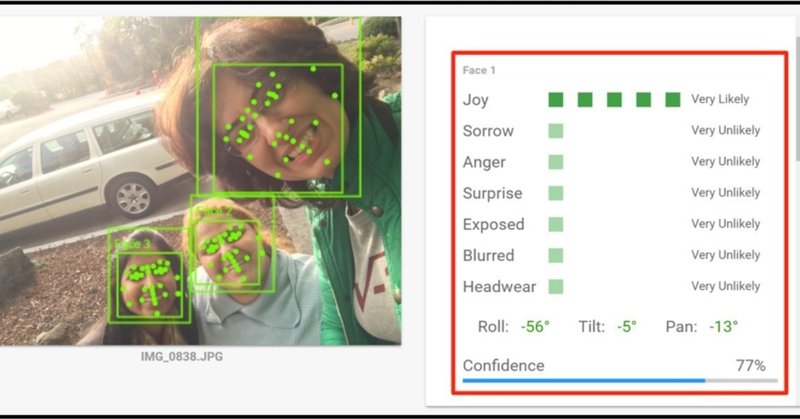
Tinderをpythonで分析してみた〜物体検出編〜

今回すること
プロフィールデータ編、顔写真編に引き続き、今回はラストの物体検出編となります。Google Cloud Vision APIを使用し、以下を検出しました。
1. 写真に写っている物体
2. 写真がスケベであるかを1-5の5段階で評価
学べること
・Google Cloud Vision APIの使い方
・各都市でどんな物体が写真に写っていることが多いのか、または少ないか
・各都市で一番スケベな写真が多い都市はどこか
環境
主に利用したライブラリとなります。
・python 3.7.0
今回使用したプログラミング言語python 3.7.0
・jupyter notebook
プログラムを実行し、結果を記録しながら、分析をするためのツール
・pandas
データの読み込みや統計量の表示など、データ分析に簡単にするためのライブラリ
・matplotlib
グラフ描画ツール
・seaborn
matplotlibの機能をより美しく、またより簡単に実現するためのライブラリ
・Google Cloud Vision API
写真の物体、スケベ検出を使用するためにAPI
対象データ
性別:女性のみ(男性のデータまで分析すると時間とお金がかかるため、今回は女性のみとしました)
年齢:制限なし
対象都市:
全44都市
アジア:東京、ソウル、香港、シンガポール、バンコク、クアラルンプール、ジャカルタ、デリー、ムンバイ
北米:ニューヨーク、ロサンゼルス、シカゴ、ワシントンDC、トロント
中南米:メキシコシティ、サンパウロ、ブエノスアイレス、サンティアゴ、ボゴタ
ヨーロッパ:ロンドン、パリ、ベルリン、マドリッド、ローマ、ミラン、チューリッヒ、ジュネーブ、ウィーン、アムステルダム、ストックホルム、コペンハーゲン、オスロ、ヘルシンキ、ワルシャワ、プラハ
ロシア:モスクワ
中東:イスタンブール、ドバイ、テルアビブ
アフリカ:ヨハネスブルグ
オセアニア:シドニー、メルボルン
件数:各都市ランダムに100人分のデータをサンプルとして使用。よって、各都市の写真の枚数は異なる
Google Cloud Vision APIについて
Googleが提供する画像解析に使用するAPIとなります。詳細については、公式ドキュメントを参照ください。
認証情報登録
こちらを参照し、認証情報の登録を完了させてください。
使い方
こちらを参照ください。
各サービスのサンプルを参照すると確認できるかと思いますが、複数のサービスを同時に指定する方法に対しての記述がありません。
以下、複数のサービスを利用するときの記述法となります。
response = client.annotate_image({
#contentにはファイルのパスが格納されています
'image': {'content': content},
'features': [{'type': vision.enums.Feature.Type.SAFE_SEARCH_DETECTION},
{'type': vision.enums.Feature.Type.LABEL_DETECTION},
{'type': vision.enums.Feature.Type.WEB_DETECTION}]
})検出するカテゴリの選定基準
以下、どちらかを満たしているカテゴリについて紹介します。
・東京が上位、もしくは下位に位置している
・個人的、読者の方が興味ありそうな分野
食べ物を検出
では、ここから本題に入ります。まず手始めに写真に"Food"が含まれている写真を各都市で比較します。利用した昨日はラベル検出です。
df_food = df[df["label_name"] == "food"]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='label_count', data=df_food)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・見ての通り、東京が他を圧倒しています。東京に住む人は最も食の写真を載せたがることがわかりますね。
・上位にはアジアの都市が目立つ
・一方、食べ物の写真が一枚もない都市が4つある
立ち姿を検出
写真に"立っている"人が写っているかを検出します。顔や体の一部分ではなく、全体が写っているかを検出します。
df_standing = df[df["label_name"] == "standing"]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='label_count', data=df_standing)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)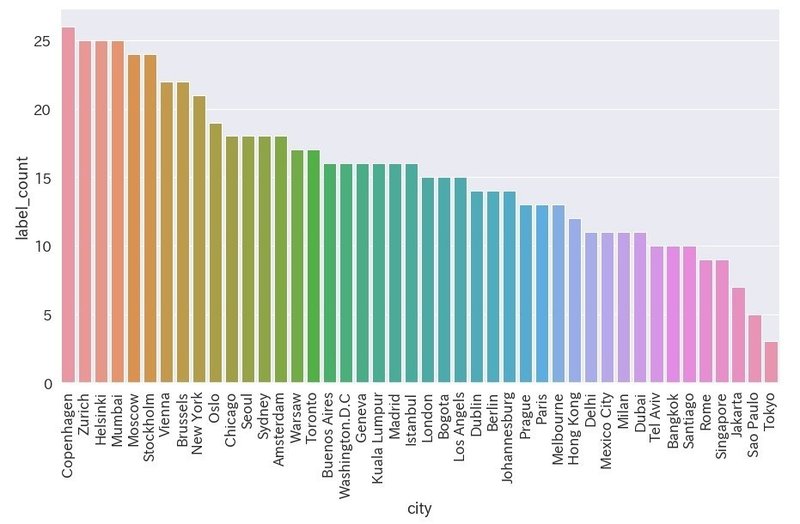
・東京はワースト
・上位は北欧やロシアなど平均身長が高い国が多い
・下位は比較的気温が温かい国が多いように見える
セルフィーを検出
df_selfie = df[df["label_name"] == "selfie"]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='label_count', data=df_selfie)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)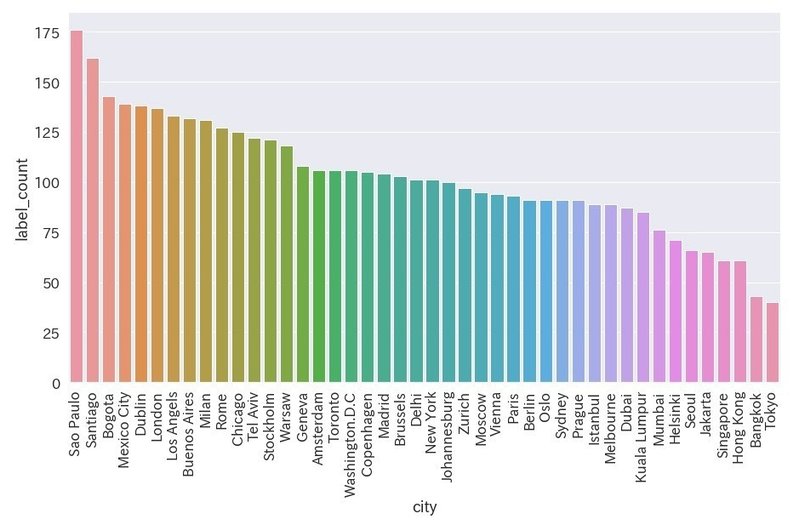
・東京はワースト
・下位はアジアの都市が占める
・上位は南米の都市が占める
白黒を検出
df_bw = df[df["label_name"] == "black and white"]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='label_count', data=df_bw)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・ベルリンが圧倒的に一位
・下位はアジアの都市が占める
・上位はヨーロッパの都市が占める
ブロンドヘアを検出
df_blond = df[df["label_name"] == "blond"]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='label_count', data=df_blond)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)
・上位はダブリン以外、北欧の都市が占める。
・下位はアジア、続いて南米の都市となっている。
・"金髪"、"ブルーアイズ"が代名詞のモスクワはそれほど金髪が多いわけでもない
ロングヘアーを検出
df_longhair = df[df["label_name"] == "long hair"]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='label_count', data=df_longhair)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)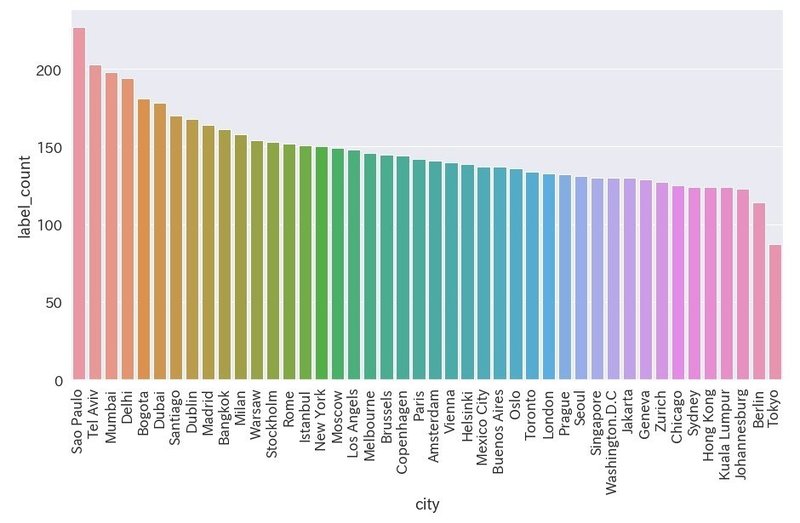
・東京はワースト
・南米、インド、イスラエルの都市が上位を占める
前髪を検出
髪型が前髪ぱっつんである写真を検出します。
df_bangs = df[df["label_name"] == "bangs"]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='label_count', data=df_bangs)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)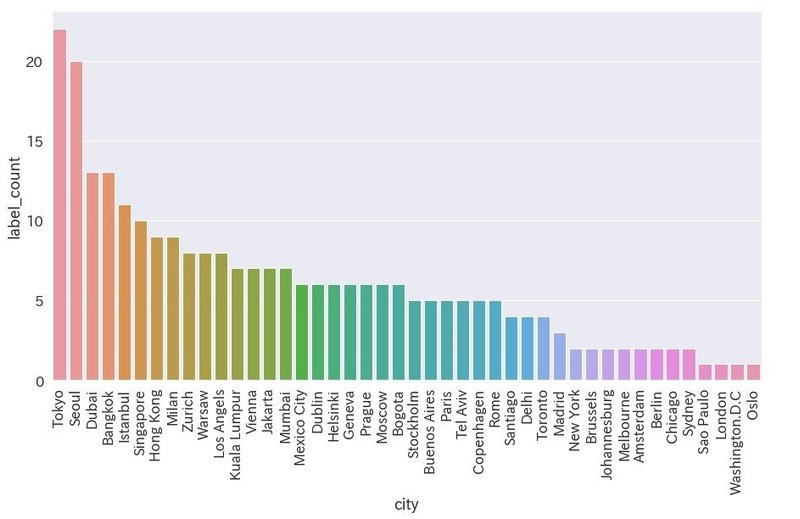
・東京とソウルが他を突き放して1, 2位。
・上位はほぼアジアの都市。
筋肉を検出
df_muscle = df[df["label_name"] == "muscle"]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='label_count', data=df_muscle)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)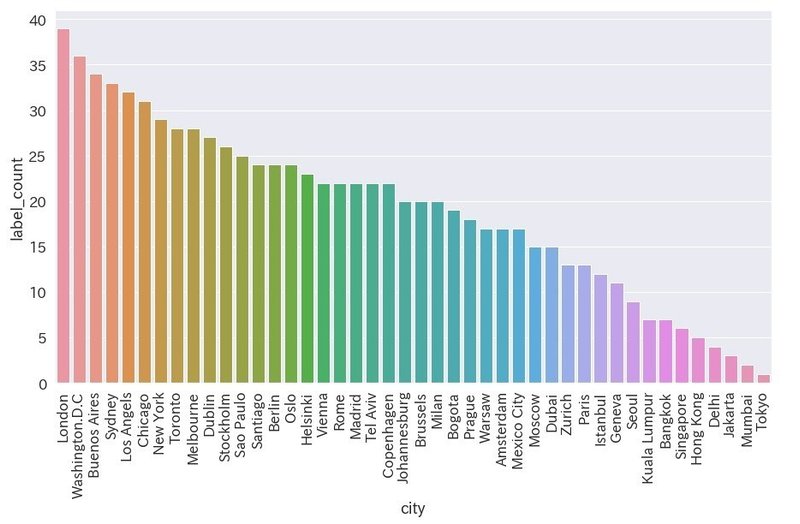
・東京がワースト
・アジアの都市が下位を占める
・英語圏と南米の都市が上位を占める
サングラスを検出
df_sunglasses = df[df["label_name"] == "sunglasses"]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='label_count', data=df_sunglasses)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)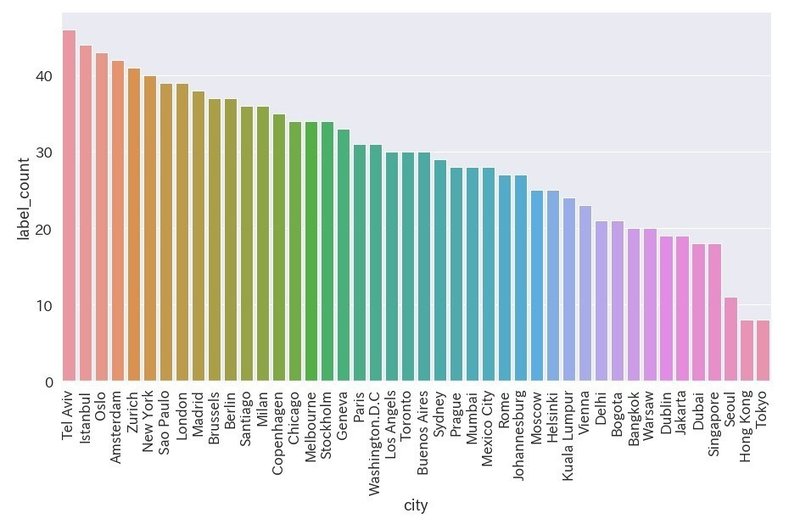
・東京と香港がワースト
・下位はアジアの都市が占める
・上位は非アジアで日差しが強い中東の都市
ドレスを検出
df_dress = df[df["label_name"] == "dress"]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='label_count', data=df_dress)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)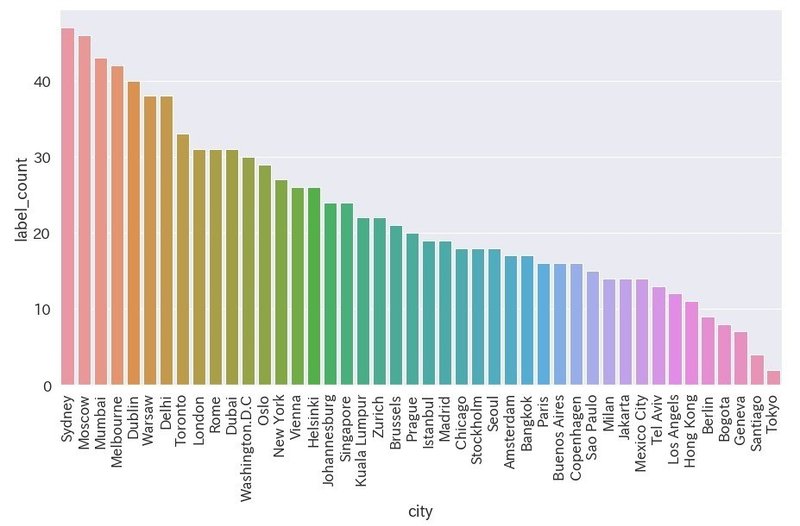
・東京がワースト
・上位の傾向がこのチャートでは掴みづらいが、オーストラリアとインドの都市が上位につけている
水着を検出
df_swimwear = df[df["label_name"] == "swimwear"]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='label_count', data=df_swimwear)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)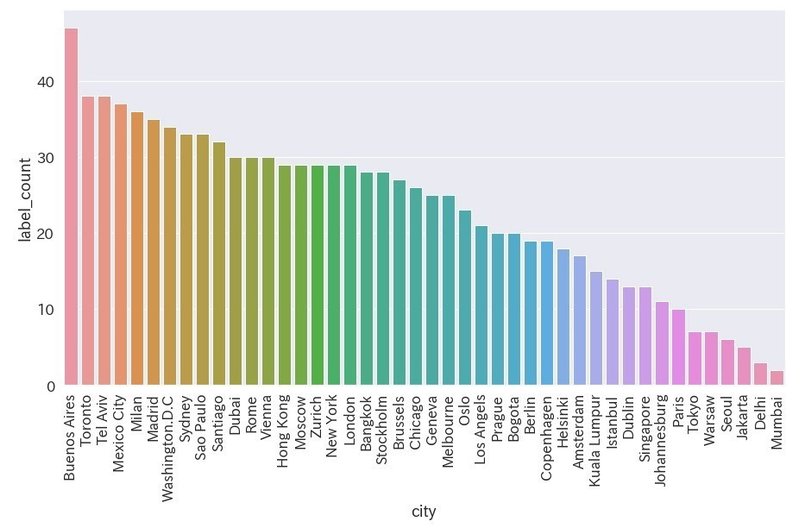
・ブエノスアイレス(アルゼンチン)の女性は水着姿の写真を載せがち
・下位はほぼアジアの都市
下着を検出
df_undergarment = df[df["label_name"] == "undergarment"]
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='label_count', data=df_undergarment)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)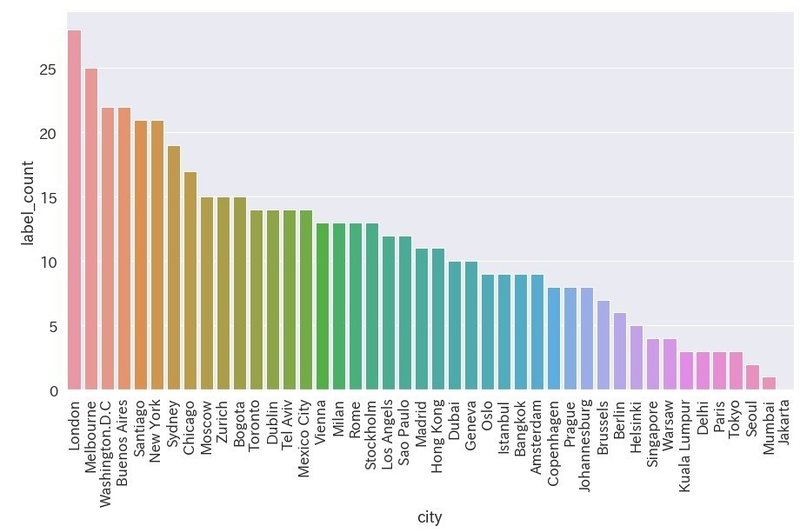
・下位はほぼアジアの都市(パリ以外)
・上位は英語圏の都市が目立つ
写真のスケベ度を算出
最後に、対象の写真からスケベ度を1-5段階評価で算出します。そして都市毎の平均をグラフで表示します。利用した機能はセーフサーチのracyカテゴリとなります。
df_racy = data.groupby(['city']).mean()
df_racy = df_racy.sort_values(['racy'], ascending=False)
df_racy = df_racy.reset_index()
plt.figure(figsize=(15,8))
ax = sns.barplot(x='city', y='racy', data=df_racy)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)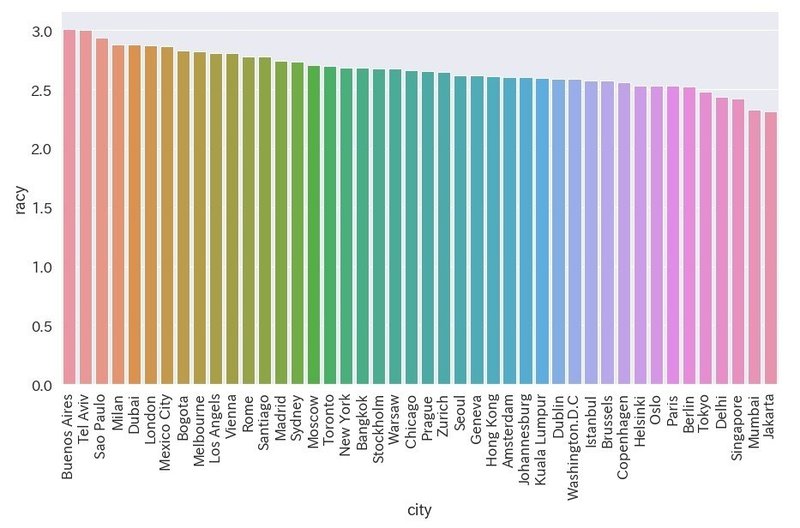
・南米の都市が上位に多い
・アジアのち都市が下位に多い
・ソウルはアジアの一番上位
まとめ
・東京は食に対する興味がある人が多い
・地域毎で掲載する写真に傾向がありそう
・スケベが多そうなアルゼンチンやブラジル、ビーチの近いテルアビブ(イスラエル)に住んだら刺激が多そう
R, Pythonで分析した結果のアウトプットをする場として利用しています。現時点の目標は"就職"することです。興味あること:R、 Python、 英語、そして筋トレです。