PythonでPairsに登録されている写真にラベル付けをしてみた

今回のテーマ
前に記事にもしたこちらを参照し、今回はPairsに登録されている写真にGoogle Cloud Vision APIを利用しラベル付けをしてみます。
経緯
先日、 AWS re:Invent 2018で発表されたこちらに影響を受け、今回の記事を作成することにしました。TinderではAmazon Rekognitionを利用しているようです。登録されている写真に対しラベル付けを行い、次にそのラベルに関係があるタグ付けを行います。タグが似ている者同士をレコメンドし、マッチングを増加させることが狙いだそうです。
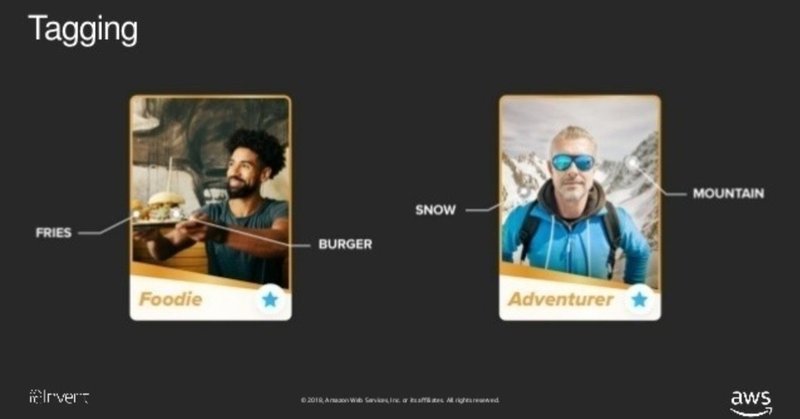
Tinderでは下の写真のようにハンバーガーとチキンナゲットが写真に写っていたらグルメ。雪山が写っていたら冒険家とタグ付けを行っています。

知れること
・写真に写っているものをラベル付けし、なにが写っていることが多いか
・ラベルの組み合わせで多い組み合わせなにか
環境
主に利用したライブラリとなります。
・python 3.7.0
今回使用したプログラミング言語python 3.7.0
・jupyter notebook
プログラムを実行し、結果を記録しながら、分析をするためのツール
・pandas
データの読み込みや統計量の表示など、データ分析に簡単にするためのライブラリ
・matplotlib
グラフ描画ツール
・seaborn
matplotlibの機能をより美しく、またより簡単に実現するためのライブラリ
・Google Cloud Vision API
写真の物体、スケベ検出を使用するためにAPI
使い方については、こちらを参照ください。
対象データ
性別:女性のみ(男性のデータは保持していないため)
年齢:21~38歳の各年齢1000人ずつ
写真枚数:81580枚
写真のラベル情報を取得
写真に写っている物体からラベルを取得します。使い方についてはこちらを参照ください。
取得したラベルを多い順に20個表示
では、どんなラベルが多いのか確認してみましょう。
df_count = user.loc[:, "label1" : "label10"].stack().reset_index()
df_count = df_count.rename(columns={0: 'label_name'})
df_count = df_count.groupby(['label_name']).size().reset_index()
df_count = df_count.rename(columns={0: 'label_count'})
df_count = df_count[df_count['label_name'] != ""]
df_count = df_count.sort_values(["label_count"], ascending=[False])
plt.figure(figsize=(15,8))
ax = sns.barplot(x="label_name", y="label_count", data=df_count.head(20))
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)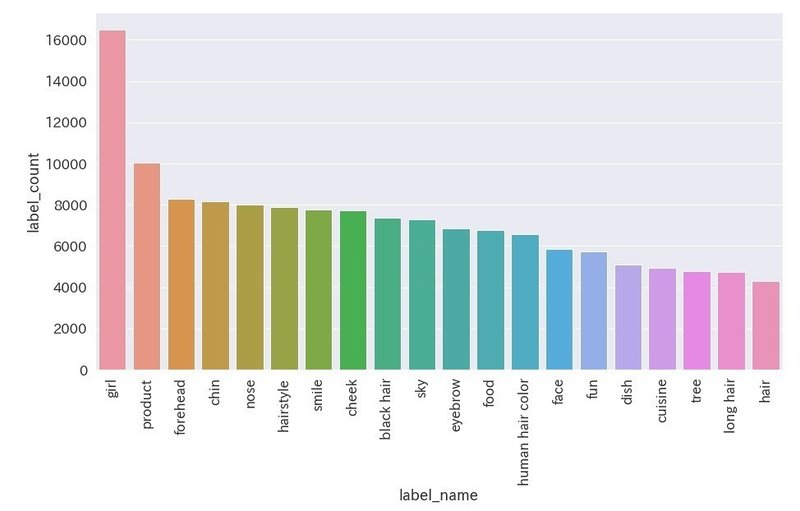
・forehead(おでこ)やhairstyleなど人間のパーツが多い
・productは商品という意味ですが、幅が広すぎでなにを表しているかわからない
・foodやcuisineなど食べ物に関するラベルが多い
ラベルの組み合わせを取得
以下、ラベル情報の全組み合わせを取得し、出現個数をカウントします。
combinations_2 = []
#userには写真から取得したラベル情報が格納されている
for i, row in user.iterrows():
row = row.tolist()
row = [x for x in row if x]
row = sorted(row)
#組み合わせを取得する
label_combi_2 = list(itertools.combinations(row, 2))
combinations_2.extend(label_combi_2)
#組み合わせの出現個数をカウント
c2 = collections.Counter(combinations_2)
c2 = sorted(c2.items(), key=lambda x: -x[1])
df = pd.DataFrame(c2)組み合わせの多い順に20個表示
plt.figure(figsize=(15,8))
ax = sns.barplot(x="combination", y="count", data=df.head(20))
ax.set_xticklabels(ax.get_xticklabels(), rotation=90)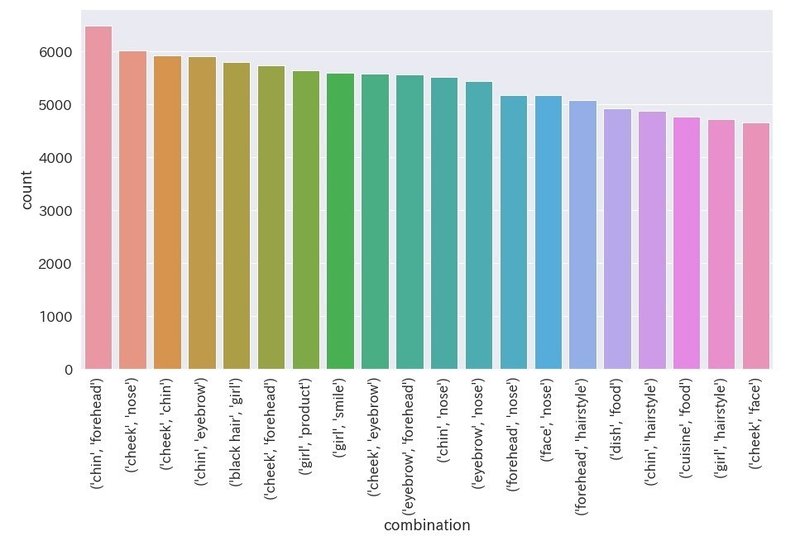
ラベル単独のグラフ同様に人間のパーツを表す組み合わせ、もしくは食の組み合わせが多い結果となりました。
人間のパーツを表すラベルを取り除き、組み合わせを20個表示
今回対象の写真は女性のため、girlやchinなどがラベルで多く存在するのは当然の結果です。よって、これらのラベルを取り除き、グラフを表示します。

人間のパーツを取り除いた結果、食事の組み合わせが多く表示される結果となりました。Pairsの女性は食事が関わる写真を多く載せていることがわかりますね。ちなみにTinderとの違いでいえば、海と水着の組み合わせが圧倒的に少なかったです。個人的にはこの組み合わせは最強だと思うのでこの写真が増えてくれればいいのにと思います。
タグ作成
では、最後にジャンルとしてどんなタグの組み合わせが多いのかを抽出してみました。例えば、('dish', 'food')だったら食事というタグが考えられますよね。
・食事
・海
・植物
・犬、猫などの動物
・スイーツ
・カフェ
・お酒
・観光地
・建築
・山
・自然(海、山以外)
・車
・アート
・コンサート、フェスティバルなどのイベント
・楽器演奏
・コスプレや着物などのコスチューム
Tinderはこのタグが同じユーザー同士でレコメンドをしているようなので、Pairsでもこの機能があったらマッチング率に変化があるかもしれませんね。
まとめ
・人間の体を表すパーツが圧倒的に多い
・上記を除くと、食事に関するラベルが多い
・海の写真はPairs、Tinderに共通して多いが、水着の写真はPairsに少ない
課題
Amazon ComprehendのTopic Modelingを利用し、システム的に行えないかトライしました。しかし、結果としてはうまく分類できませんでした。人の目で一つずつ分けるのではなく、他にもっとスマートな方法があれば教えていただければ、うれしく思います。
参考
プレゼン資料:
プレゼン動画:
AWS re:Invent 2018: [REPEAT] Deep Dive on Amazon Rekognition, ft. Tinder & News UK (AIM307-R)
R, Pythonで分析した結果のアウトプットをする場として利用しています。現時点の目標は"就職"することです。興味あること:R、 Python、 英語、そして筋トレです。