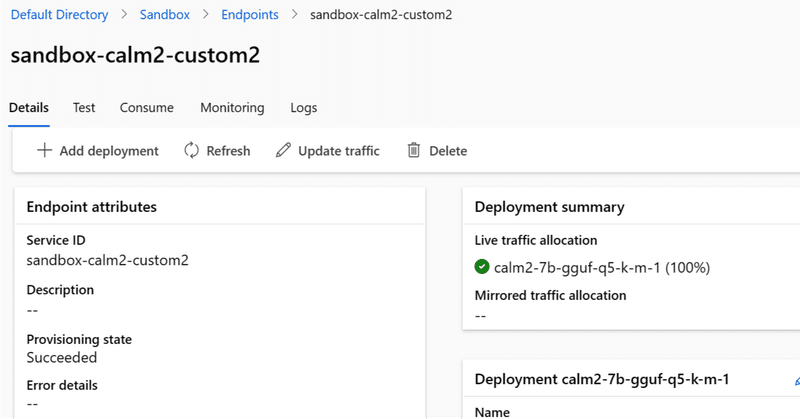
オープンソースなLLM(calm2-7b)のCPU推論エンドポイントをAzureとllama-cpp-pythonでシュッとつくる

こんにちは、https://twitter.com/iryutab という者です。
はじめに
12/05 追記: この方法は、デプロイが有効である間ずっとインスタンスが起動しっぱなしになってしまいます(基本VMです)。一週間少しで数万円に膨れてしまうので、使っていないときには停止させましょう。節約や、実際のプロダクトへの組み込みの際にはアクセスが有る際だけインスタンスを起動する形のContainer Appなどが適していると思うので、こちらも近々動作させて記事化します。
オープンソース(ローカル)LLMの発展は日々凄まじいですが、いざそれを活用して遊ぼうと思うと、デプロイという課題がついて回ります。
2023年11月現在のLLMでは、エッジデバイスで推論できるくらいの大きさのモデルだと性能が微妙ですし、クラウドを使おうにもGPU付きインスタンスの確保は中々困難です。
しかしColabで動かして感心して終わり、というのも勿体ないので、何とかしてクラウドに自分専用の推論APIを立てたいと思います。
※公開後追記※
この記事の内容は「とりあえず」動かすには確かに楽なのですが、24時間マシンが立ち上がってしまうので、流石にコスト面的に明らかにベターな方法があり、実践してみています。手が空いたらそちらの記事も書きますので是非!
注意
筆者はAzureド初心者です。
OpenAIとMSの騒動をきっかけにAzureに興味を持ちアカウント作成をして、その日のうちにこの記事の内容を実践して動作させたため、諸々の実行手順にムダがあったり、アンチパターンを踏んでいる可能性がかなりあります。
「とりあえず動いたよ!」「とりあえずこうすると使えるよ!」程度の情報であること前提でお願いします。
逆に言えば、初めてAzureを触った人がごちゃごちゃ半日いじるだけで動くくらい簡単です。Do try it.
基本のアイディア
Azure上のAI関連プロダクトがまとまった「Azure Machine Learning Studio」(以下AzureML) では、モデルのアップロードからデプロイまで一括して簡単に管理できます。
AzureML上の「モデル」は、一般にはPyTorchなどの重みをMLFlowという形式に変換して扱いますが、実はオリジナルの推論コードと推論環境用のDockerfileを用意すれば、任意のファイル(!)をアップロードし、他のモデルと同様に管理することができます。
そこで、llama.cppで用いられるggufファイルをモデルとしてAzureMLにアップロードし、推論用の簡単なpythonコードをllama-cpp-pythonを使って書き、それを実行するためのミニマルなDockerfileと組み合わせることで、お手軽にggufモデルを動かしてくれるエンドポイントを生やします。
必要なもの
Azureアカウント
https://signup.azure.com/ から作りましょう。
最初アカウントを作ると、200USDぶんのクレジットがもらえます。
この記事では、アカウントの作成・カードの登録などの手順はカバーしません。が、概ね こちらの記事 のとおりです。
動かしたいモデルのgguf変換済みファイル
Hugging faceで公開されているものでも、自分でファインチューンしたものでもLoRAアダプトしたモデルでもおkです。
ただし、事前にllama-cpp-python使ってシュッと推論できるか確かめておくとより良いと思います。
この記事内では Cyberagentさんのcalm2-7b-chatをgguf変換されたモデルを https://huggingface.co/mmnga/cyberagent-calm2-7b-chat-gguf からダウンロードして使用します。
推論用pythonスクリプト
あとで書きましょう。かんたんです。
実行環境用Dockerfile
あとで書きましょう。かんたんです。
手順
1. Azure Machine Learning ワークスペースを作成する
Azure Portalから、「Azure Machine Learning」と検索します。
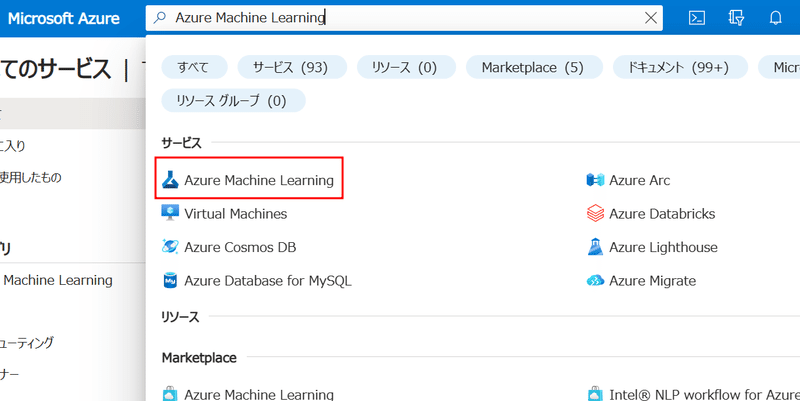
クリックするとワークスペース一覧が表示されます。まだ何も無いはずですので、作成します。
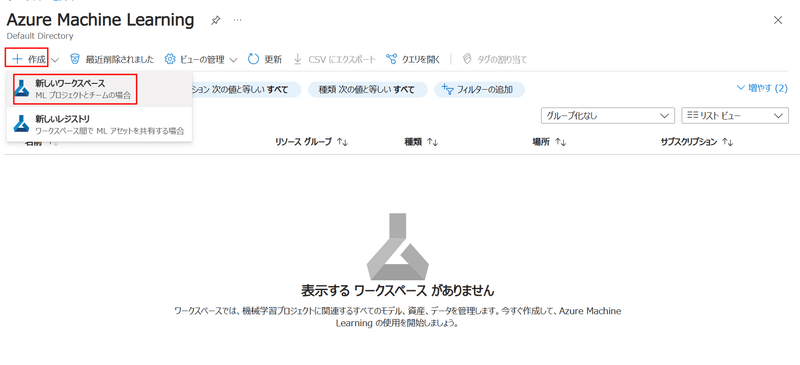
作成画面では、以下のものが必要となります。
サブスクリプション
リソースグループ
名前
リージョン
ストレージアカウント
キーコンテナー
Application Insights
作成していないものもあると思いますが、この画面から新規作成できるので、気にせず名前を決めていきましょう。
上からリソースグループの名前とワークスペースの名前を適当に入力すると、ストレージアカウント以下の名前は勝手に入力してくれますので、そのまま作成してしまいます。
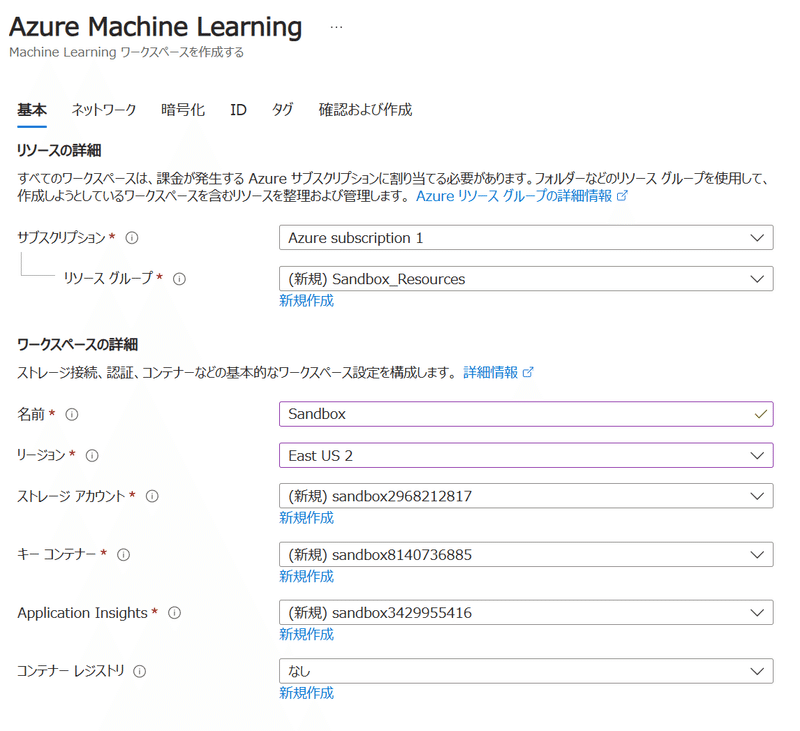
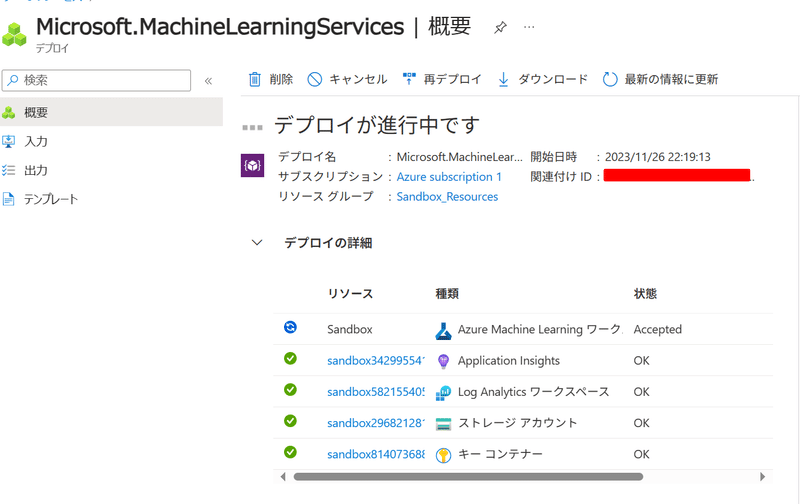

作成ボタンを押すとデプロイが開始され、暫く待つとワークスペースが作成されます。「リソースに移動」を押し…

「スタジオを起動」して、AzureML Studioに移動しましょう。
2. Modelの作成
AzureML Studioを起動すると、このような画面になるはずです。
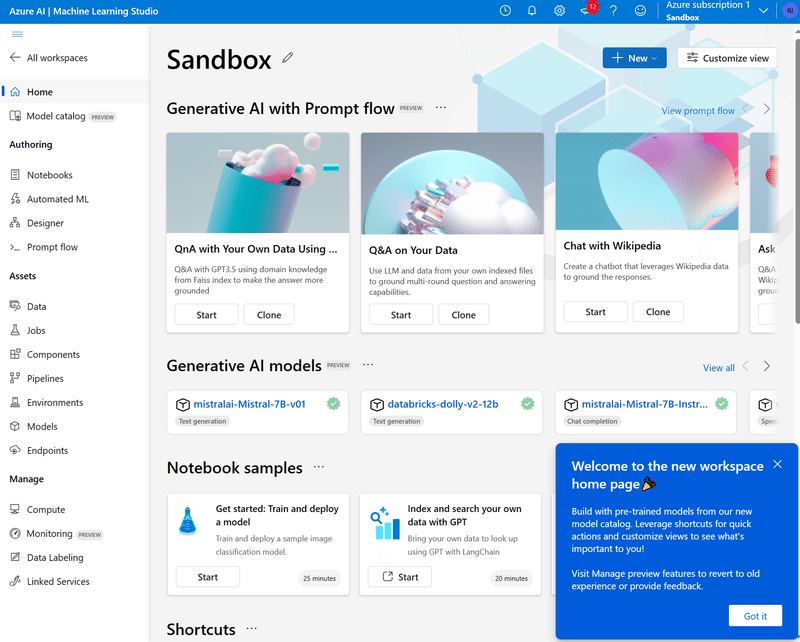
左側メニューより「Models」を選択し、ローカルファイルからモデルをアップロードしましょう。
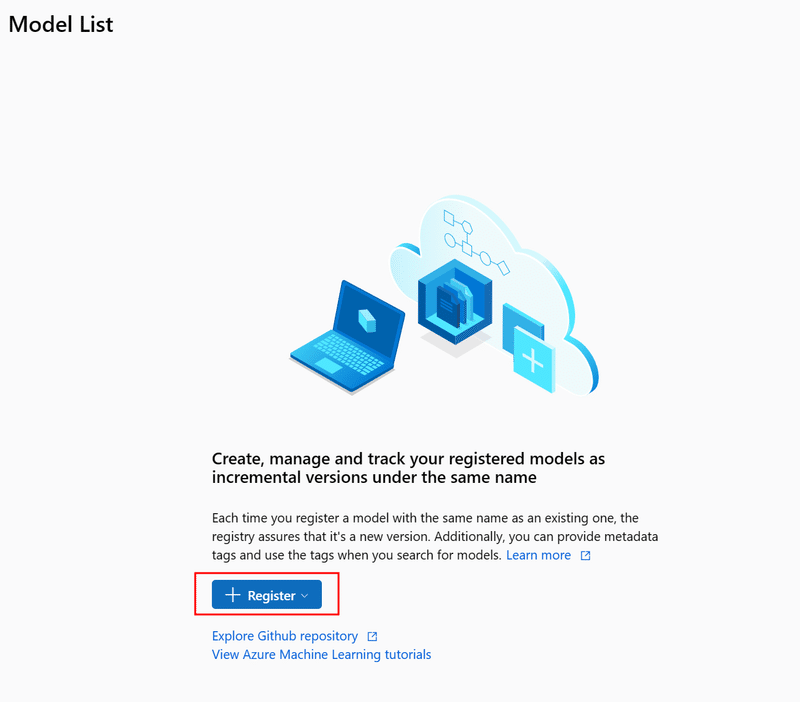
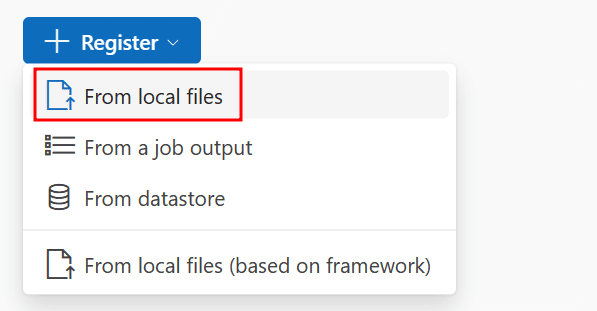
これで開くモーダル上で、「Model Type」で「Unspecified Type」を選択し、「Browse」から予めダウンロードしておいた.ggufファイルを選択します。
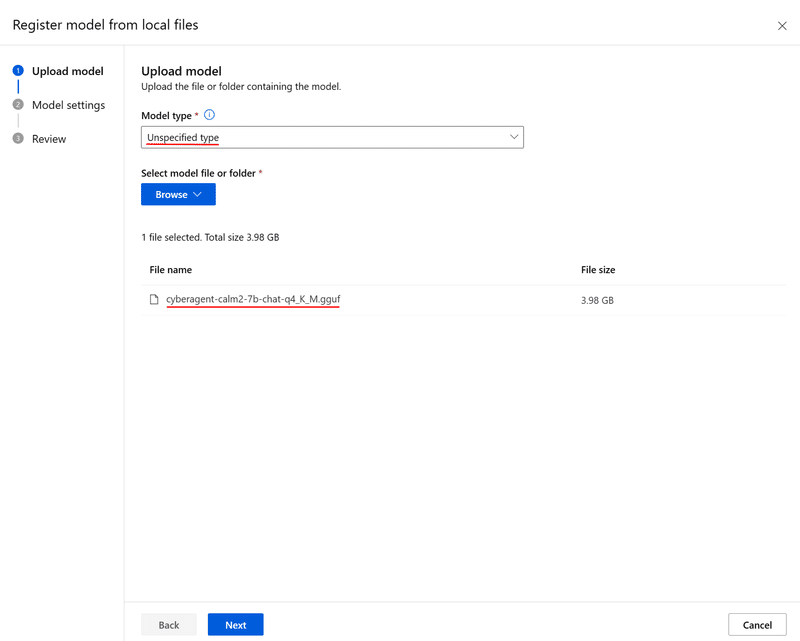
今回は前述の通り、CyberAgentさんのcalm2-7b-chatモデルをmmngaさんが.gguf変換してHugging Faceで公開されているものを利用しています。
「Next」を押下すると、名前や説明などの入力を求められるので適当に入力します。
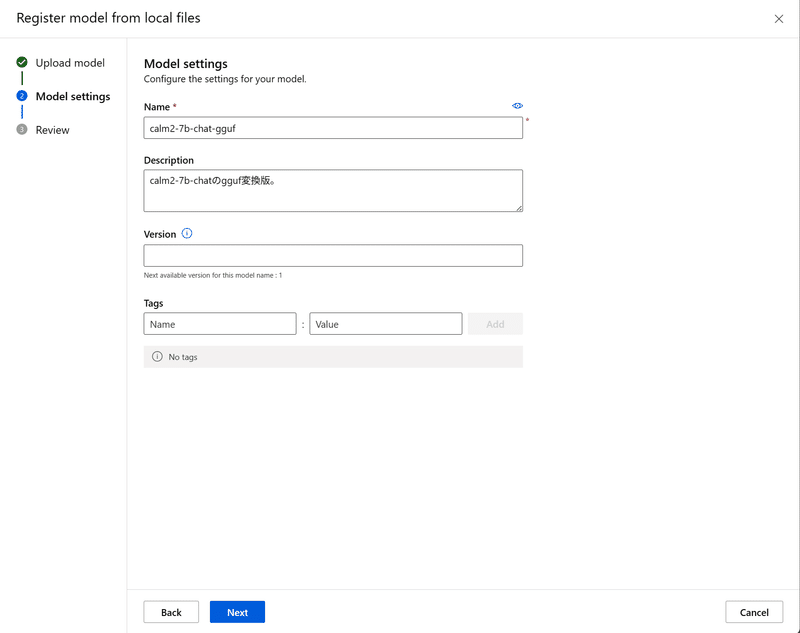
「Next」を押すとレビュー画面が開くので、確認して「Register」しましょう。
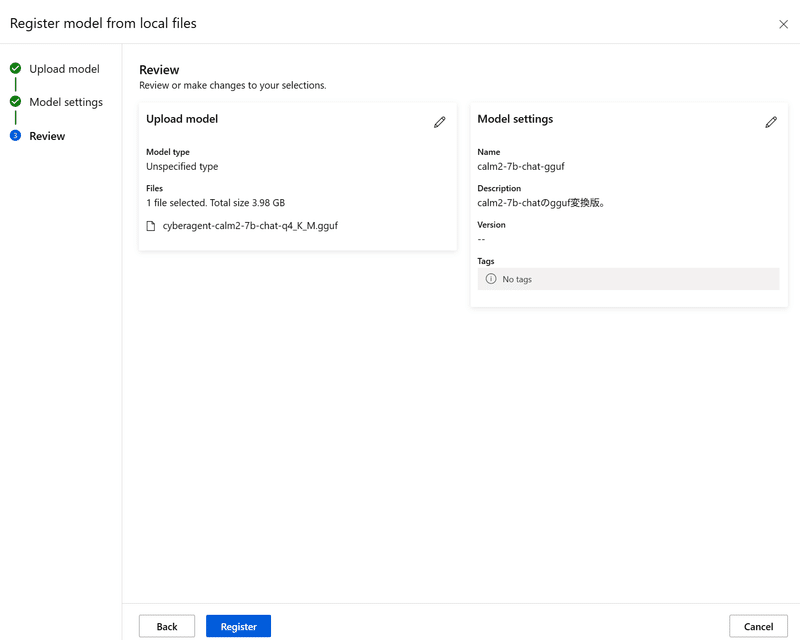
「Register」ボタンを押してからファイルのアップロードが始まるので、それなりに時間がかかります。
完了するとModels一覧にアップロードしたモデルが見えるはずです。
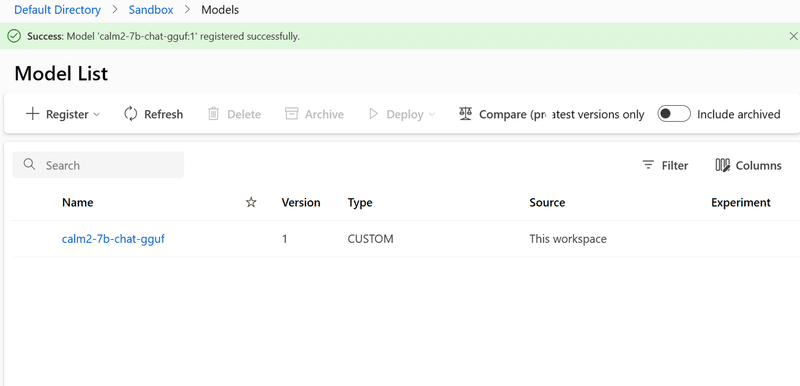
3. Environmentの作成
Environmentは、推論用のコードを実行するための実行環境で、主にDockerfileで構成します。
まず、AzureML Studio 左手メニューより「Environments」を選択します。
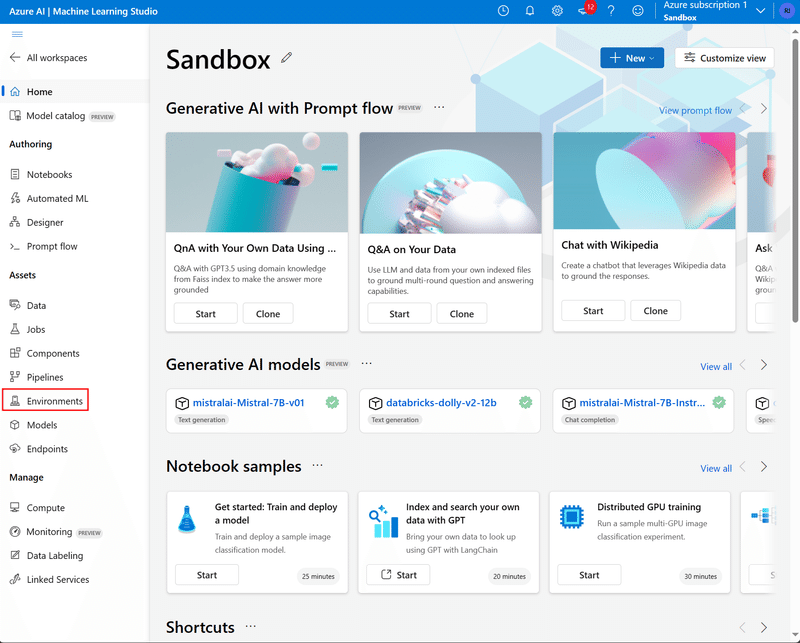
「Custom environments」タブから、「Create」を選択します。

適当な名前を入力し、「Create a new docker context」を選択します。
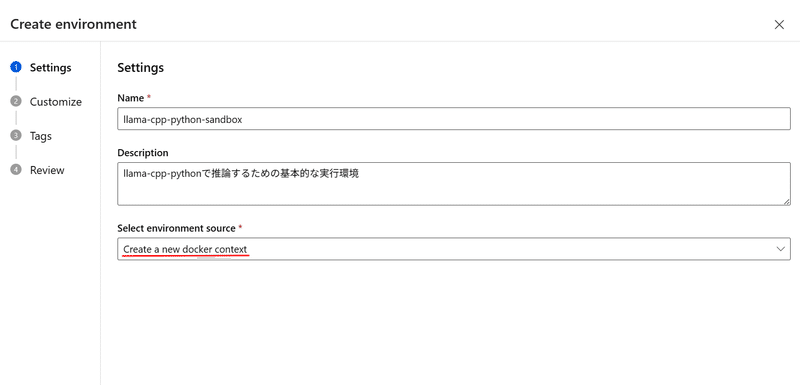
すると、サラッとインラインのDockerfileエディタが表示されます。

基本的には、
1. mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04 イメージをベースに構築すること
2. azureml-mlflow がインストールされていること
がEnvironmentsとしての最低条件のようなので、ここにllama-cpp-pythonを動かすためのコードを追加していきます。
私の場合、最低限のコードとして以下を使用しました:
FROM mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
# llama-cpp-pythonとazuleml-mlflow, azureml-inference-server-httpをインストール
RUN pip install llama-cpp-python azureml-mlflow azureml-inference-server-http
# ワークディレクトリを設定
WORKDIR /usr/src/appllama-cpp-pythonパッケージのインストールはもちろんなのですが、
azureml-inference-server-http パッケージも (何故かテンプレには含まれていないものの) 必要らしく、これの存在を知らずに実行したところこのパッケージが不足している旨のエラーが発生したので追加しています。
コードを書いたので、「Next」を押します。

この内容で問題ないので、Createしてしまいます。しばらく待つと作成が完了します。
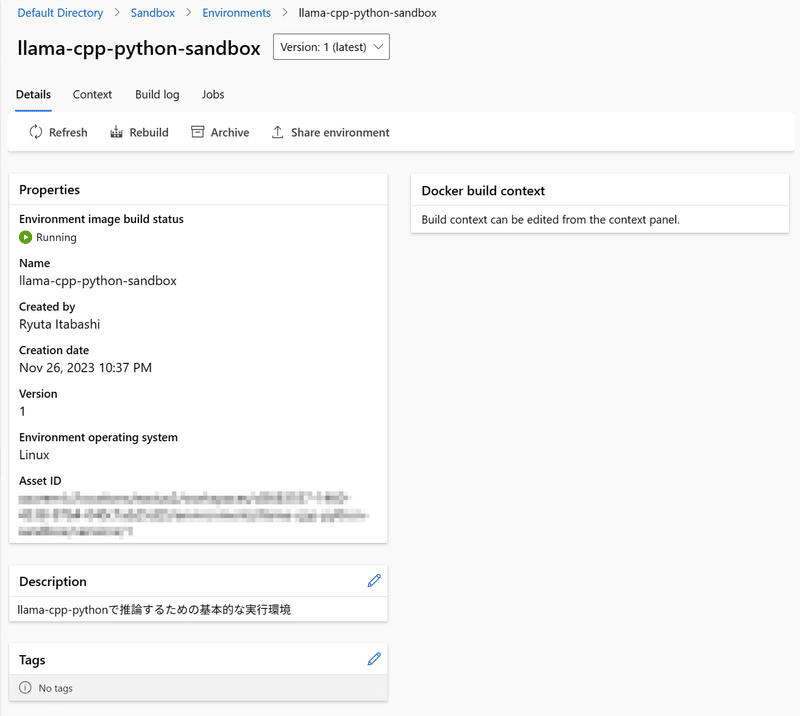
4. score.py (推論用スクリプト) の用意
これで実行環境と推論するモデルが用意されましたが、AzureMLが想定しているMLFlow互換のモデルではないため、オリジナルの推論コードが必要です。
シュッと作ってしまいましょう。まず、Azure公式のExampleを見てみます。
(何故かGithub上のファイルへのリンクを埋め込めないので、生リンク)
https://github.com/Azure/azureml-examples/blob/main/cli/endpoints/online/model-1/onlinescoring/score.py
Exampleのコメントだけ日本語翻訳したものを置いておきます。
import os
import logging
import json
import numpy
import joblib
def init():
"""
この関数は、コンテナが初期化/起動されたとき、通常はデプロイメントの作成/更新後に呼び出されます。
メモリ内でモデルをキャッシュするなど、初期化操作を行うロジックをここに記述できます
"""
global model
# AZUREML_MODEL_DIRはデプロイ時に作成される環境変数です。
# モデルフォルダへのパス(./azureml-models/$MODEL_NAME/$VERSION)です
# モデルのフォルダ名がある場合は、その名前を提供してください
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl"
)
# sklearnモデルに戻すためにモデルファイルを逆シリアライズします
model = joblib.load(model_path)
logging.info("Init complete")
def run(raw_data):
"""
この関数は、エンドポイントの呼び出し毎に実際のスコアリング/予測を行うために呼び出されます。
例では、json入力からデータを抽出し、scikit-learnモデルのpredict()メソッドを呼び出し、
結果を返します。
"""
logging.info("model 1: リクエストを受信しました")
data = json.loads(raw_data)["data"]
data = numpy.array(data)
result = model.predict(data)
logging.info("Request processed")
return result.tolist()というわけでこれをベースに、llama-cpp-pythonを用いた簡単な推論コードを書きます。
import os
import json
import logging
from llama_cpp import Llama
def init():
global llm
try:
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "cyberagent-calm2-7b-chat-q4_K_M.gguf"
)
llm = Llama(model_path=model_path, n_ctx=32768)
logging.info("Model loaded.")
except Exception as e:
logging.error(f"Failed to load model. Work termination. {e}")
raise e
def run(data) -> dict:
data = json.loads(data) if isinstance(data, str) else data
prompt = data.get("prompt")
repeat_penalty = data.get("repeat_penalty")
temperature = data.get("temperature")
if not prompt or repeat_penalty is None or temperature is None:
raise ValueError("Data is missing required fields: 'prompt', 'repeat_penalty', 'temperature'")
answer = llm(prompt, max_tokens=25000, echo=True, repeat_penalty=repeat_penalty, temperature=temperature)
logging.info("Inference done.")
return answer
このファイルをscore.py (名前はお好みで) として保存しておきます。
5. Endpointの作成
AzureMLの左手メニューから、「Endpoints」を選択します。
「Create」を押してEndpointの作成に進みます。

Model選択画面になるので、先程アップロードしたggufモデルを選択し、「Select」します。
諸々設定が出てきますが、適宜名前だけ設定して、あとは触らなくて問題ありません。
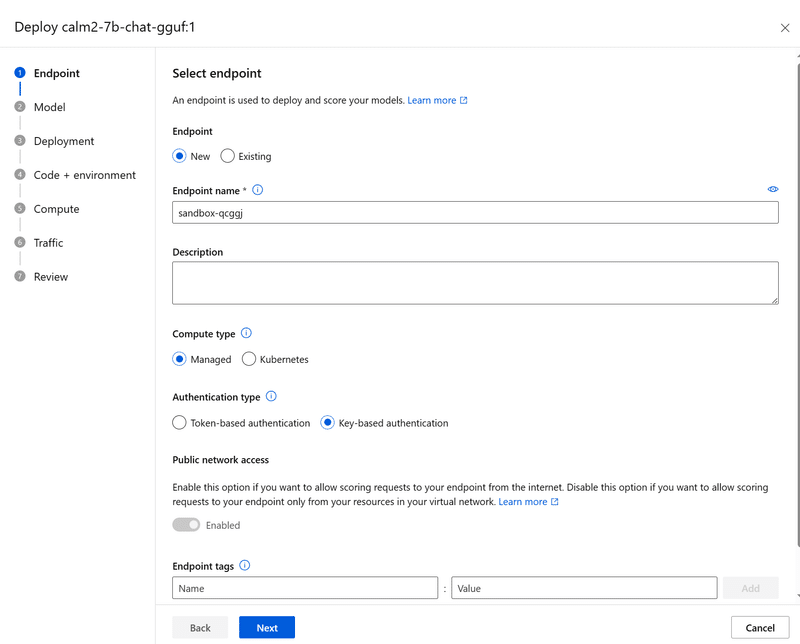
さっき選んだのですが、またModel選択画面です。何もせずNext。
デプロイに関する諸々の設定です。とりあえず動かすだけであれば何もいじらずに進んで問題ありません。
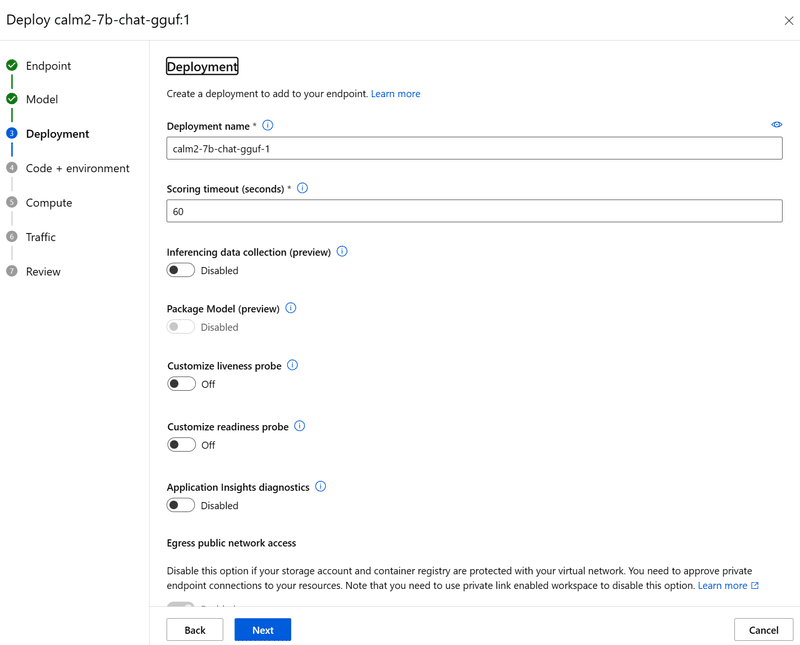
次が重要です。ここで「scoring script for inferencing」に先程用意した推論用のスクリプト、そして「Select environment」でこちらも先程用意した実行環境を選択します。
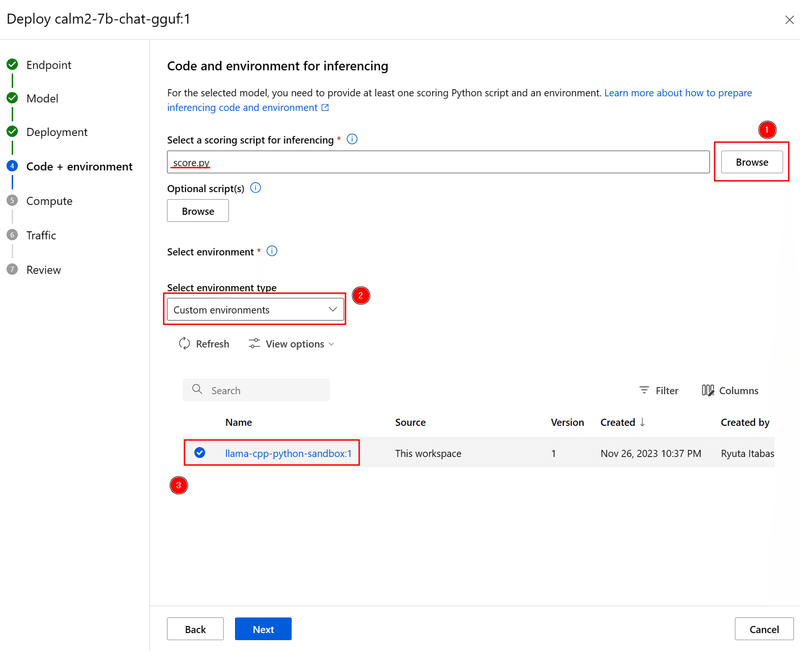
次に、計算資源を選択します。今回の例で使用しているEast US 2リージョンでは、GPUインスタンスはQuotaがないのでそもそも選択できません (他リージョンでも同じかも?)
今回推論する7b, 4bit量子化モデルではStandard_E4s_v3程度で十分かと思いますが、高速にしたい場合やモデルサイズによって適宜何種類か試してみると良いかと思います。
Instance countも、とりあえず自分用に推論するぶんには1台で十分かと思います。
次に、このエンドポイントへのトラフィックのうち、どれくらいの割合をこのデプロイメントに割り当てるかを選択します。が、このエンドポイントには今設定している一つのデプロイしか無いので、必然的に100%になります。そのままNext。

最後にレビューして、Nextでデプロイが開始されます。

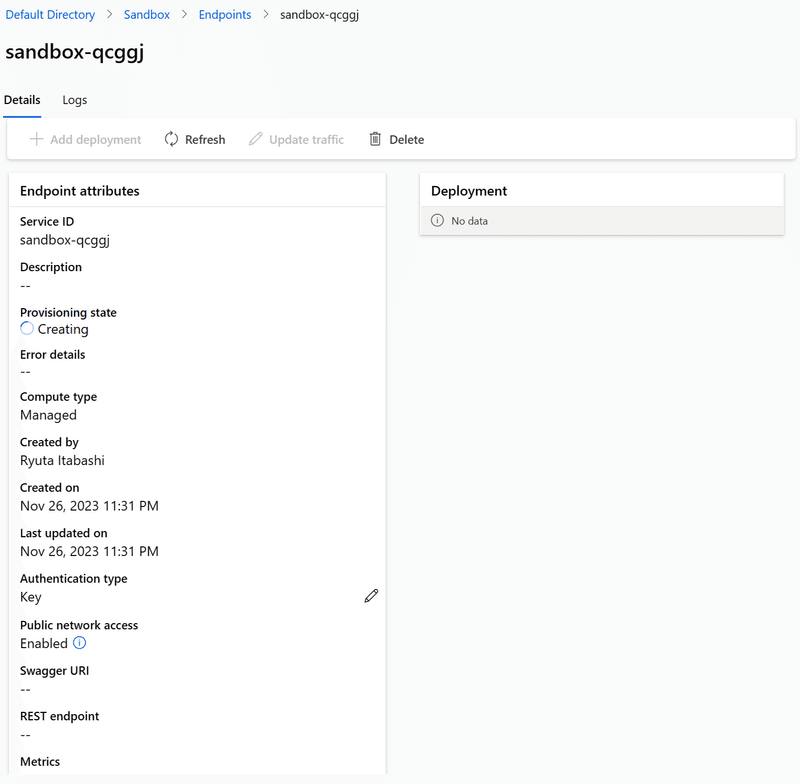
この一連の操作は、内部的に「エンドポイント」と「デプロイメント」の2つを連続で生成してくれます。そのため、エンドポイント一覧に出てきてもデプロイが完了するまでにはそれなりな時間がかかります。
大体10分程度かかるので、紅茶かコーヒーでも淹れてきましょう。
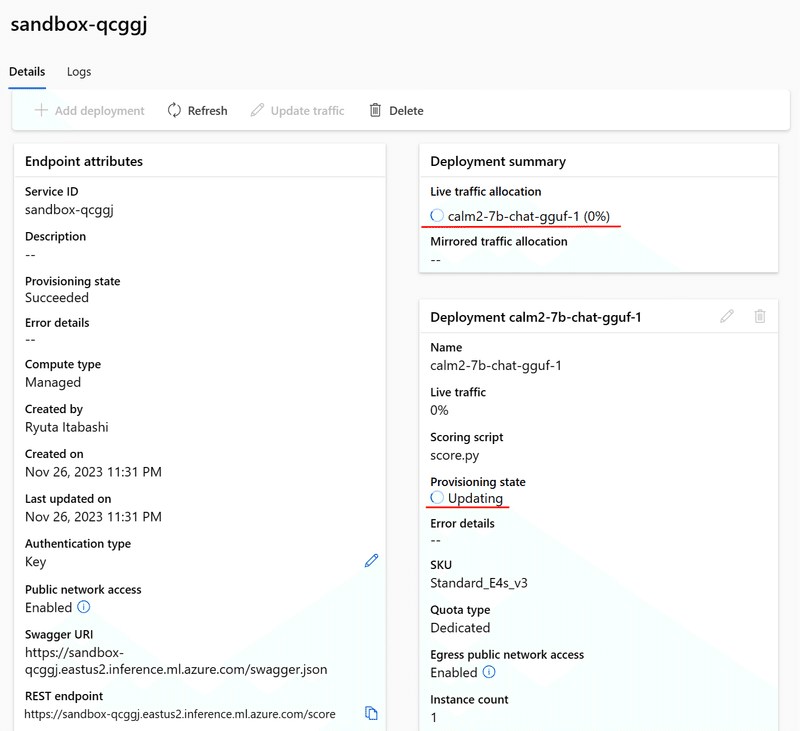
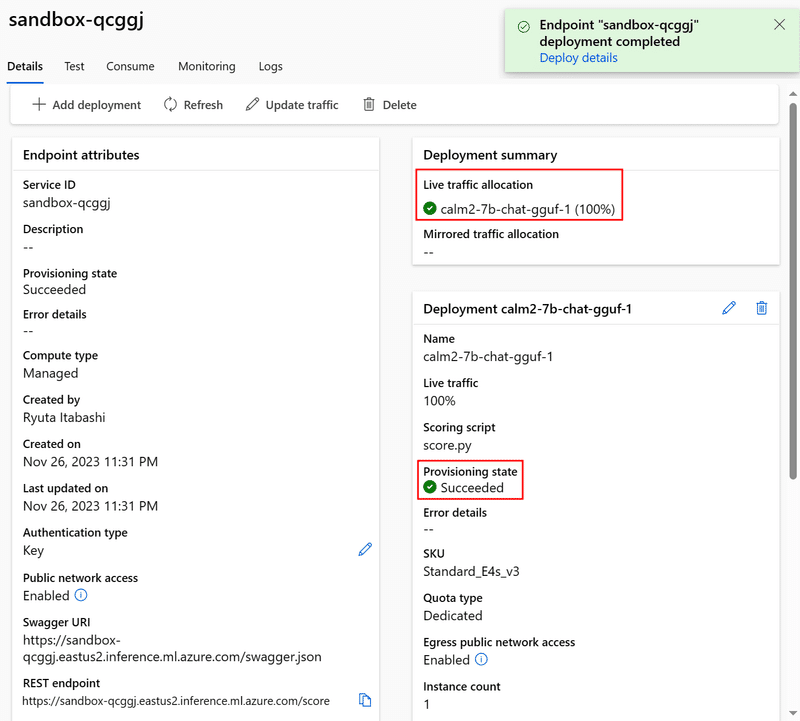
推論させてみる
とりあえずGUIで動作確認
動作確認は、AzureML Studio上からGUIで簡単に可能です。「Test」タブに移動して、データを入力、Testしてみましょう。
実行してみると…
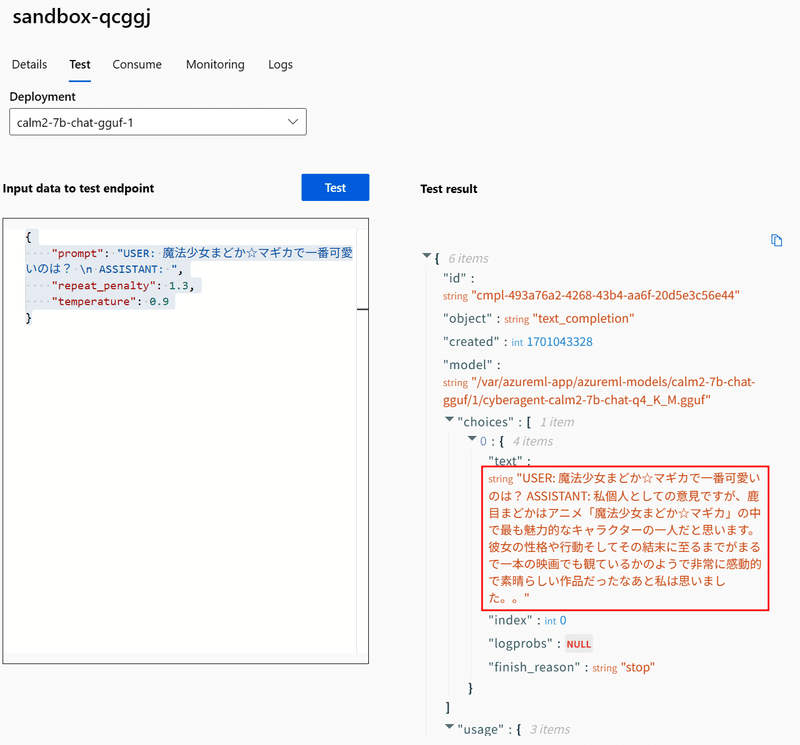
ちゃんと動いています。
PythonでAPIコールしてみる
GUI上で試すだけでも仕方がないので、Pythonから呼び出してみましょう。
実は、デプロイに成功すると勝手にサンプルの推論コードを作ってくれます。「Consume」タブを開きます。

ここで推論用のREST API EndpointとAPIキー、サンプルコードが閲覧できます。
ただしこのままのコードだとデータのフォーマットが含まれていなかったり、レスポンスの生データを返してしまうため、コメントの日本語訳とともに少々変更したバージョンを作成しました。
import urllib.request
import json
import os
import ssl
def allowSelfSignedHttps(allowed):
# クライアント側でサーバー証明書の検証をバイパス
if allowed and not os.environ.get('PYTHONHTTPSVERIFY', '') and getattr(ssl, '_create_unverified_context', None):
ssl._create_default_https_context = ssl._create_unverified_context
allowSelfSignedHttps(True) # 自己署名証明書を使用するスコアリングサービスで必要です。
# リクエストデータはこちら
# 下記の例はJSON形式を想定していますが、エンドポイントが期待する形式に応じて更新される可能性があります。
# 詳細はこちらを参照してください:
# https://docs.microsoft.com/azure/machine-learning/how-to-deploy-advanced-entry-script
data = {
"prompt": "USER: こんにちは、お元気ですか? \n ASSISTANT:",
"repeat_penalty": 1.3,
"temperature": 0.9
}
body = str.encode(json.dumps(data))
# エンドポイントのREST API URLをここに入れてください
url = ''
# エンドポイントに対するプライマリ/セカンダリキーをここに入れてください
api_key = ''
if not api_key:
raise Exception("A key should be provided to invoke the endpoint")
# azureml-model-deployment ヘッダーはリクエストを特定のデプロイメントに強制的に送るために使用されます。
# エンドポイントのトラフィックルールを遵守するためには、このヘッダーを削除してください
headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key), 'azureml-model-deployment': 'calm2-7b-chat-gguf-1' }
req = urllib.request.Request(url, body, headers)
try:
response = urllib.request.urlopen(req)
result = response.read()
# バイト文字列をデコードしてJSONオブジェクトに変換
result_json = json.loads(result.decode('utf-8'))
# 'choices'の中の'text'フィールドを取得
text = result_json['choices'][0]['text']
print(text)
except urllib.error.HTTPError as error:
print("The request failed with status code: " + str(error.code))
# ヘッダーを出力します - リクエストIDとタイムスタンプが含まれており、障害のデバッグに役立ちます
print(error.info())
print(error.read().decode("utf8", 'ignore'))実際にローカルファイルに保存し、実行してみましょう。

内容はともかく、無事に生成されました。
今後できること
さて、とりあえず動きましたが、企業として実運用したり、また個人メイカーのレベルでの利用でも、もう少し改善できる幅があります。
APIキーよりも高度な認証手段
公開するプロダクトでAPIを叩く場合にはあったほうが安心です
スケーリング幅の確保
トラフィック増大時には必要ですね
llama-cpp-pythonを使わず、llama.cppをビルドしたバイナリで直接推論
多分高速化できます
その他高速化・最適化、コスト対策
Azure初心者なのでここは本当に何もわからないのですが、多分かなり改善幅あると思います…
個人でものづくりに利用する範囲として楽しく使えるレベルのデプロイは実現できましたが、もしこの辺りご存じの方いらっしゃいましたら、是非実践記事を公開いただけたらうれしいです。
私はとりあえず、これをスーパーカワイイロボットことAIスタックチャンに組み込んで行こうと思います。

最後までありがとうございました。何かご指摘点などあれば、 https://twitter.com/iryutab までお願い致します。
おわり
この記事が気に入ったらサポートをしてみませんか?