
【エンジニアの道は果てしない】データ構造の仕様検討

こんにちは。すうちです。
以前コンピュータとプログラムの間で交わす0,1を解釈するルールやデータ構造について触れました。
今回はデータ通信のプログラムを仮定して、前段階でデータ構造をどのように考えるか言語化してみたいと思います(いわゆる仕様検討の話です)。
はじめに
通常開発は要求仕様→仕様検討→設計コーディングの流れがあり、自作や趣味で開発する場合も基本は同じです。
顧客の要求仕様の代わりに自分が実現したい機能を列挙して、プログラムに必要な項目に落とし込みます。
例えば、対象のシステム構成(ソフトウェア階層)やモジュール分割(クラスや関数の定義)、外部や内部のデータ構造や通信制御など検討します。
1.何をどこで実現するか
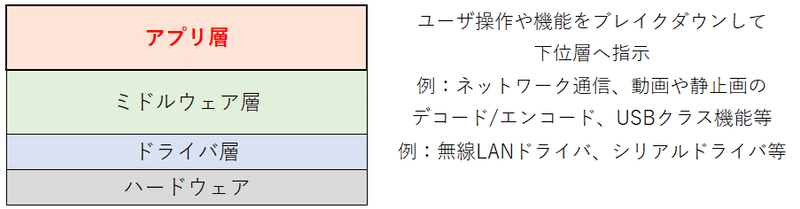
ソフトウェア階層
ソフトウェア開発の階層構造は、階層による役割と担当範囲を明確にして将来的な拡張性や保守性をあげる設計思想です。
ソフトウェア階層は、OS(例:WindowsやAndroid)で定義されたものもあれば、機能単位で決められたものもあります。
例えば、ネットワーク通信で有名なOSI参照モデルも階層構造です。
階層構造を独自に定義する場合、考え方は色々ありますが、例えばユーザ操作と関与するアプリ層、ハードウェアを制御するドライバ層、その中間でアプリ層とドライバ層を橋渡しするミドルウェア層(ドライバの上位機能)などで分けることがあります。
今回の階層は、アプリ層における通信部分を想定しています。
機能仕様
一般的なサービスからユーザ操作によるリクエスト処理を考えると以下でしょうか。
・アカウントのログイン/ログアウト
・ダウンロード/アップロード
-テキスト
-画像
-動画
データ通信は、送信側のリクエストに応じて受信側が処理するクライアント・サーバモデルを前提にしています。
2.データ構造のルール決め
インタフェース(API)
ほぼ機能仕様をそのまま形にした感じですが、
・login(”acount_id”,”password”)
・logout(”acount_id”)
・upload("acount_id", "request_up_data")
・download("acount_id", "request_dl_data")
上記インタフェースと引数(カッコ内)を定義しました。以下は例として、uploadで使用するデータ構造の仕様を検討します。
ヘッダ情報とデータ
まず対象データが特定サービスのものか判断したり、ヘッダの先頭位置を確認するため何らかの識別子は必要です。
処理するリクエストは、UploadやDownload種別や対象データがテキスト、画像、動画など区分ができた方が良さそうです。
また扱うデータの種類は幅広いので、データサイズは可変長にして動画などサイズが大きい場合はサーバの処理負荷も考えて分割転送もサポートします。
これらの前提から、次の様なデータ構造を定義します。
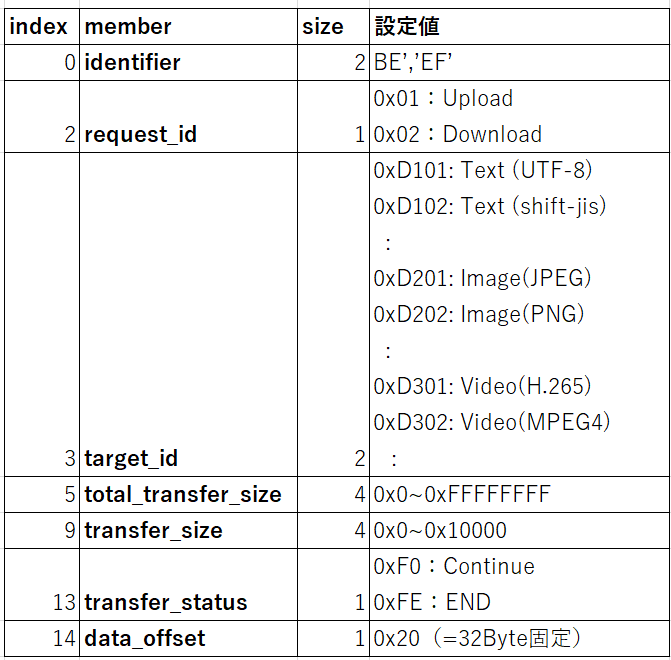
ヘッダ情報の各データ領域
identifier(2Byte)
この領域はIDとしてユニークな値を決めればよいですが、今回は識別子として’0xBE’,’0xEF’の固定2Byteにします。
request_id(1Byte)
リクエストは2種類(Download/Upload)なので領域は1Byte確保します(1Byte=8bitで256種類の表現可能)。ちなみにUploadで使用する場合、この領域は毎回同じ値です。
target_id(2Byte)
リクエストのターゲットは、テキスト、画像、動画の3種類とするとrequest_idと同様に1Byteで足ります。
ただし、例えばテキストは文字コードの種類だったり、画像はPNGやJPEGなど複数フォーマットがあるので、ターゲット毎にもう少し情報を細分化できた方が便利な気がします(直接画像ファイルのヘッダを参照して判断する方法もあります)。
このためtarget_idは上位1byteでターゲット種別、下位1byteでターゲット依存の補足情報を表現できるようにトータル2Byteで考えます。
total_transfer_size、transfer_size(4Byte)
これらの領域は4Byte(32bitなので約4.2GBまで表現可能)割り当てます。ここは実際どこまで使い方を想定するか(制限するか)により議論すべき内容かもしれません。
transfer_status(1Byte)
リクエストしたデータが1回の転送で完了なのか。複数回なのかサーバ側で判断するため転送状態(例えば、0xF0: Continue, 0xFE: ENDなど )を表す領域を1Byte確保します。total_transfer_sizeと併用して異常状態の検知も想定します。
data_offset(1Byte)
ヘッダ領域の後にデータ領域を配置する場合、ヘッダ部分に必要な領域以上(合計14Byte)表現できれば良いので、オフセット領域は1Byteで十分です(0~256までオフセット表現可能)。
各データ領域の配置
以下、検討したデータ構造の一覧です
3.送信側と受信側で同じルール適用
リクエストしたデータを正しく処理するには、当然ながら送信側と受信側で同じルールを共有する必要があります。
例えば、ユーザアプリのバージョンUPが必要なのは、不具合修正だけでなく、機能追加で前述のようなデータ構造の変更が関係する場合も考えられます。
最後に
今回ソフトウェア開発の一部ですが、データ構造に特化して仕様検討の例を挙げてみましたが、何か参考になれば幸いです。
本来は仕様検討後に実装やテストして仕様の妥当性を確認する話も書きたかったのですが時間が足りませんでした。またその話は(別の形も含め)機会を見つけて書きたいと思います。
以下、余談です。
最近の開発は小規模なソフトウェアであっても、例えばUSBやI2C通信が必要な場合マイコンで提供されるミドルウェアやドライバを使うことがほとんどです(全て0から作ることは少ない)。
その背景はソフトウェアの規模が大きくなり、自社で全て開発するのは時間的にもコスト的にも厳しく、汎用品を利用して開発効率を上げたりソフトウェア資産を有効活用する目的があります。
一方、OSなどの共通プラットフォームやライブラリを使うことで発生する問題もあります。
少し前に話題になったlog4jの脆弱性はそれを使っているソフトウェアが多いため影響範囲が広く問題になった例です。
過去に独自仕様が乱立した時代からソフトウェアの標準化や共通化の動きが始まり、それによって生まれたメリットは大きいと思いますが、近年のセキュリティ面では攻撃対象が絞れる点ではデメリットにもなっているかもしれません。
最後まで読んで頂き、ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?