
Rによるwebスクレイピングとテキストマイニングで朝ドラのタイトルを分析してみた

Rでスクレイピングとテキストマイニングを使って、1961年に放送が始まり59年目を迎える朝ドラのこれまでのタイトルを分析してみました。
なお、いつもギリギリに起きるタイプだったので朝ドラはほとんど観たことはないのですが、サイト構造として非常にスクレイピングしやすそう、かつデータ量もそこまで多くなく扱いやすいと考えたため使用しました。(n=102)
RMeCabをインストールする
install.packages("RMeCab", repos = "https://rmecab.jp/R", type = "source")
RMeCabは昨年の研究していた際に使用していましたが、久しぶりに使用しようとすると再インストールが必要でした。
バージョンがR4.0.0にアップデートされたからみたいです。
library(RMeCab)
res <-RMeCabC("すもももももももものうち")
unlist(res)インストールされたかlibraryで呼び出して検証してみました。正常であれば、「すもももももももものうち」を以下のように品詞分解してくれます。
![]()
webスクレイピングを行う
install.packages("rvest")
library("rvest")
drama <-read_html("https://www.nhk.or.jp/archives/asadora/chronology/broadcast.html")
rvestのパッケージをダウンロードしたら、read_htmlにスクレイピングを実行したいページのURLを指定します。(普通にコピペするだけ)
install.packages("dplyr")
library(dplyr)
titles <-drama %>% html_nodes("div[class='wrap']") %>% html_text()
しかしこれではページのすべての情報を取得してしまっているため、必要箇所のみを取り出すべくhtml_nodes()で文字列の部分のみ指定します。
文字列はChromeの検証で探します。
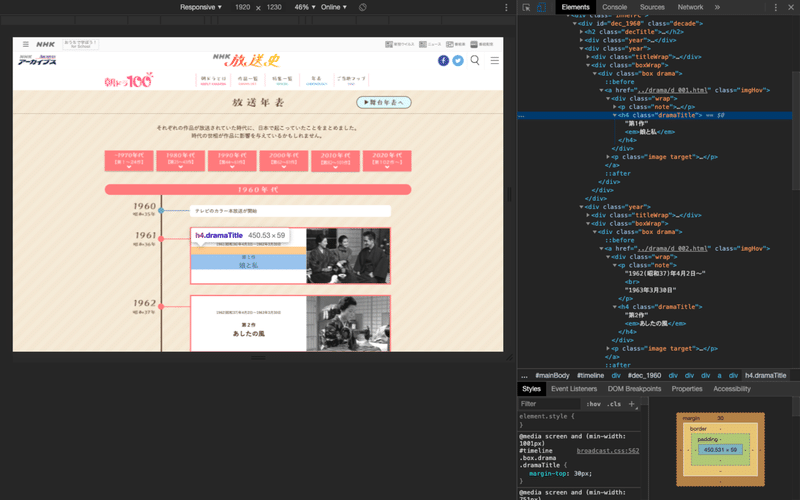
テキストを確認する
スクレイピングで取得したテキストを確認するためにmagrittrパッケージをインストールします。
install.packages("magrittr")
library(magrittr)
titles %>% extract(1)ここで、[1] "1961(昭和36)年4月3日~1962年3月30日 第1作娘と私"
と返ってきたため、タイトルだけを取得してきたつもりが、放送期間を含んでしまっていることに気づきました。
title <-drama %>% html_nodes("h4[class='dramaTitle']") %>% html_text()
library(magrittr)
title %>% extract(1)サイトの構造を確認し直し、<h4>タグの中にタイトルが入っていることを確認し、改めて<h4>タグの中身のみをtitleと定義し直します。
RMeCabで形態素解析にかける
library(RMeCab)
title %>% extract2(1) %>% RMeCabC() %>% unlist()RMeCabを使用して上記を実行し、テキストを単語に分解します。それぞれの語の品詞属性がベクトルの各要素の名前として以下のように表示されます。

webスクレイピングで取得したデータを一覧で保存する
上記では1つのタイトルごとに形態素解析にかけられますが、この後すべてのタイトルをすべて形態素解析にかけた結果を求めたいので、取得したデータの一覧を1つのファイルとして保存する必要があります。
print(title,type="txt") //タイトルを一覧で確認する
write.csv(title, "C:title.csv") //タイトル一覧をcsv形式でダウンロードする頻度表を作成する
上記で保存したファイルにdocDF()を適用します。
tit <- docDF("ファイルの~所在地~C:title.csv",type=1,pos=c("名詞","形容詞","動詞"))
write.csv(tit, "C:tit.csv")ファイルの所在地は手打ちで記述するのが面倒なので、macユーザーはドラッグ&ドロップで入力しちゃいます。
結果を見る
作成した頻度表から品詞を指定して取得します。
tit %>% filter(POS1 == "動詞") %>% head(20) //動詞の頻度表の上から20語を取得できます
tit %>% filter(POS1 == "形容詞") %>% head(10) /形容詞の頻度表の上から10語を取得できます一方、名詞の場合、数字などの適切ではない形態素が多く含まれてしまうため、品詞詳細分(POS2)を「一般」や「固有名詞」にする方が良さそうでした。
tit %>% filter(POS1 == "名詞",POS2 %in% c("一般")) %>% head(10) 分析結果と感想
スクレイピングからのそのデータを使用したテキストマイニング(MeCabによる形態素解析)をやってみるという目的は達成できました。
しかし、朝ドラはこれまでのタイトルにあまりかぶりがなく、面白いと思えるような結果を得ることはできませんでした、、
n=102でかつタイトルということで語数が少なかったことが原因かと思われるので、次はもう少し文字総量の多いものに取り組みたいです。
参考文献
サポートは「書籍購入」や勉強のための「活動費」に充てさせていただき、またnoteで還元したいと思います!!!よかったらポチッとよろしくお願いします🦉