
正則化とは? -機械学習モデルの 過学習を防ぎ、予測精度を最適化する

正則化はモデルが訓練データに過剰に適合することを防ぎ、新しいデータに対する予測精度を高めるための重要な手法らしい。
いままでなんとなくやっていたLightGBMの正規化パラメータ設定についてChatGPTに教えてもらったのでメモします。
正則化とは?
L1正則化(Lasso):不要な特徴量の重みを0にして影響を減らす。
L2正則化(Ridge):特徴量の重みを小さくしモデルの複雑さを減らす。
Elastic Net:L1とL2のバランスを取り、データの特性に応じて最適なモデルを構築する。(主に線形モデルで利用)
正則化パラメータの調整
過学習なら、正則化パラメータを増やしてモデルの複雑さを減らす。
過小適合なら、正則化パラメータを減らしてモデルにより多くの情報を捉えさせる。
実践的な例:ボストン住宅価格データセット
以下のグラフは、ボストン住宅価格データセットにRidgeとLasso正則化を適用し、正則化パラメータ(Alpha)の異なる値に対する平均二乗誤差(MSE)を観察するものです。
Alphaの値が0.01付近でMSEが最小になることを示しています。これは、この範囲内で適切な正則化の強度を選択することが、過学習を防ぎながらモデルの一般化能力を最大化するための検討の出発点となります。
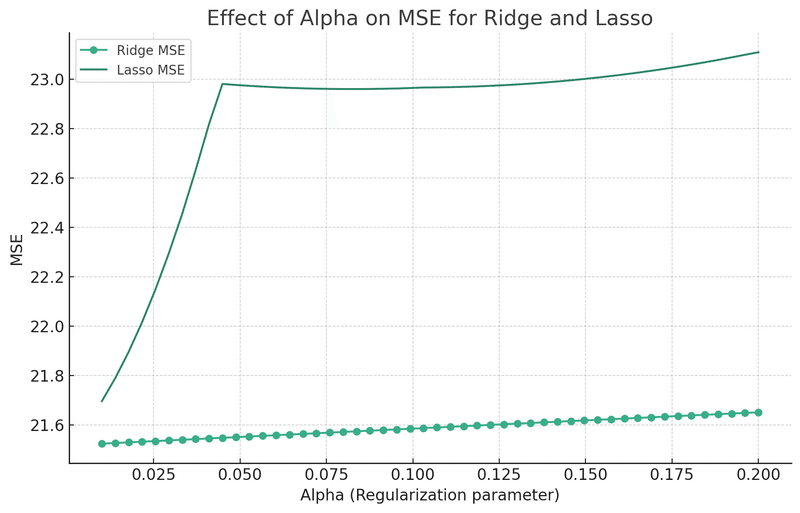
最適なAlphaの選択には、MSEの最小値だけでなく、モデルの一般化能力や解釈性も考慮する必要があります。したがって、クロスバリデーションやビジネス上の要求など、さまざまな側面を総合的に考慮して最適な値を選択することが重要です。ハイパーパラメータの探索には、Optunaやグリッドサーチなどの手法が役立ちます。
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Ridge, Lasso
from sklearn.metrics import mean_squared_error
import numpy as np
import matplotlib.pyplot as plt
# データの準備
boston = load_boston()
X_train, X_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.3, random_state=42)
# Alphaの範囲を設定
alphas = np.linspace(0.01, 0.2, 50)
# MSEを計算
ridge_mses, lasso_mses = [], []
for alpha in alphas:
ridge, lasso = Ridge(alpha=alpha), Lasso(alpha=alpha)
ridge.fit(X_train, y_train)
lasso.fit(X_train, y_train)
ridge_mses.append(mean_squared_error(y_test, ridge.predict(X_test)))
lasso_mses.append(mean_squared_error(y_test, lasso.predict(X_test)))
# グラフを描画
plt.figure(figsize=(10, 6))
plt.plot(alphas, ridge_mses, label='Ridge MSE')
plt.plot(alphas, lasso_mses, label='Lasso MSE')
plt.xlabel('Alpha')
plt.ylabel('MSE')
plt.title('Effect of Alpha on MSE')
plt.legend()
plt.show()
この記事が気に入ったらサポートをしてみませんか?