
FX自動売買/機械学習のサンプルコード(LightGBMモデルの学習とバックテスト)

この記事では、FX自動売買において機械学習モデルの学習とバックテストを行うためのサンプルコードを掲載しています。
LightGBMとは
LightGBMは、勾配ブースティング決定木 (Gradient Boosting Decision Tree, GBDT) を実装した機械学習ライブラリの一つです。高速で精度が高く、大規模なデータにも対応できるため、多くの機械学習問題で広く用いられています。今回は、このモデルをFXの自動売買に応用してみるという試みの紹介です。
概要は以下の記事が参考になります。是非合わせてご覧ください。
機械学習×FX自動売買
この記事では、この機械学習モデルについて、
・Python(Google Colab)でLightGBMモデルの学習を行う
・学習したモデルを用いてPython(Google Colab)でバックテストを行う
方法をご紹介します。
FX自動売買の機械学習モデルを作成する上で必要なコードを初歩的なところから詳細まで丁寧に記載するように心がけています。
Inputデータの準備
まず、MT5を起動して「表示」→「銘柄」と進みます。
MT5からtickデータのダウンロード
以下のように「ティック」タブで「情報呼出」を行い、「ティックをエクスポートする」をクリックしてtickデータをダウンロードします。
期間を「2023.03.01 00:00:00 - 2023.04.01 00:00:00」と指定すると、2023年3月の1ヶ月分のティックデータがダウンロード出来ます。この際、ファイル名を「GBPJPY_tick_202303.csv」としておきます。

同様にして、202201~202303までの15ヶ月分のデータをダウンロードしてください。
※tickデータはサイズが大きいので、1ヶ月ごとのダウンロードを推奨しています。
MT5からbarデータのダウンロード
続いて「チャートバー」タブで「情報呼出」を行い、「バーをエクスポートする」をクリックしてbarデータをダウンロードします。
barデータはそんなにサイズが大きくありませんので、期間を「2013.01.01 00:00:00 - 2023.04.01 00:00:00」と指定して必要な期間だけ1つのファイルにデータを保存します。
それぞれ以下のファイル名で保存します。
H1(1時間足):「GBPJPY_H1.csv」
M15(15分足):「GBPJPY_M15.csv」
M5(5分足):「GBPJPY_M5.csv」
M1(1分足):「GBPJPY_M1.csv」

tickデータをGoogle Driveに保存
上記でダウンロードしたtickデータをGoogle Driveのtickフォルダに以下のように保存します。

※画像は202303のみですが、202201~202303までの15個のcsvファイルを保存します。
barデータをGoogle Driveに保存
上記でダウンロードしたbarデータをGoogle Driveのbarフォルダに以下のように保存します。

Google Colabの事前準備
ここからは、Google Colabで行う処理です。
Googleドライブのマウント
以下のコードを実行することで、ColabからGoolge Driveにアクセスすることが可能になります。
from google.colab import drive
drive.mount('/content/drive')ライブラリのインポート
必要なライブラリをインポートします。ここでは一つ一つの詳しい解説は省略します。後の工程で各コードを実行するために必要なライブラリをまとめてインポートするようにしています。
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
from tqdm.notebook import tqdm
import numba
from numba.typed import List
import os
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
import joblib
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import lightgbm as lgb
from sklearn.metrics import accuracy_score, f1_score年月リストの作成方法
ループ処理を行うために、年月のリスト(YYYYMM_list)を作成しておきます。
# 2022年〜2023年までの年月のリストを作成
YYYYMM_list = []
for year in range(2022, 2024):
for month in range(1, 13):
YYYYMM_list.append(f"{year}{month:02d}")
# 15ヶ月間に絞る(この場合、2022年1月〜2023年3月まで)
YYYYMM_list = YYYYMM_list[:15]この処理により、以下のようなリスト(YYYYMM_list)が作成されました。
['202201', '202202', '202203', '202204', '202205', '202206', '202207', '202208', '202209', '202210', '202211', '202212', '202301', '202302', '202303']
Inputデータ(csvをpklに変換)
まずは、csvファイルをpandasのDataFrameに変換してpklファイルとして保存します。これによりpandasでインプットデータが扱いやすくなります。
tickデータの変換方法
YYYYMM = '202303'
df = pd.read_table('/content/drive/My Drive//tick/GBPJPY_tick_'+YYYYMM+'.csv')
df['time'] = pd.to_datetime(df['<DATE>']+ ' '+ df['<TIME>'])
df = df.set_index('time')
df = df.rename(columns={'<BID>':'bid','<ASK>':'ask'})
df = df[['bid','ask']]
df.to_pickle('/content/drive/My Drive/tick/GBPJPY_tick_'+YYYYMM+'.pkl')実行結果


15ヶ月分のループ処理方法
上記は、202303のみを変換するコードでしたが、以下のループ処理を行うことで15ヶ月分のcsvデータを一気に変換可能です。
for YYYYMM in tqdm(YYYYMM_list):
df = pd.read_table('/content/drive/My Drive/tick/GBPJPY_tick_'+YYYYMM+'.csv')
df['time'] = pd.to_datetime(df['<DATE>']+ ' '+ df['<TIME>'])
df = df.set_index('time')
df = df.rename(columns={'<BID>':'bid','<ASK>':'ask'})
df = df[['bid','ask']]
df.to_pickle('/content/drive/My Drive/tick/GBPJPY_tick_'+YYYYMM+'.pkl')先ほどの処理で2022年1月から2023年3月までの年月リスト(YYYYMM_list)を作成していましたので、15ヶ月分のpklデータがGoogleドライブに保存される処理になります。
barデータの変換方法
続いて、barデータの変換も行います。最初にashi_listというリストを作成して、1分足(M1)、5分足(M5)、15分足(M15)、1時間足(H1)の4つについてループ処理を行います。
ashi_list = ['M1', 'M5', 'M15', 'H1']
for ashi in tqdm(ashi_list):
df = pd.read_table('/content/drive/My Drive/bar/GBPJPY_'+ashi+'.csv')
df['time'] = pd.to_datetime(df['<DATE>']+ ' '+ df['<TIME>'])
df = df.set_index('time')
df = df.rename(columns={'<OPEN>':'Open','<HIGH>':'High','<LOW>':'Low','<CLOSE>':'Close'})
df = df[['Open','High','Low','Close']]
df.to_pickle('/content/drive/My Drive/bar/GBPJPY_'+ashi+'.pkl')実行結果

テクニカル指標の計算
続いて、準備したbarデータにテクニカル指標を追加します。
barデータの読み込み
まずは、先ほど作成したbarデータ(.pkl)を読み込みます。
df_M1 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_M1.pkl')
df_M5 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_M5.pkl')
df_M15 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_M15.pkl')
df_H1 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_H1.pkl')pandas_taのインストール
テクニカル指標計算のために、pandas_taというライブラリを使用します。Google Colabにはインストールされていませんので、以下のようにインストール処理を行います。
!pip install pandas_tapandas_taのインポート
続いて、インポート処理です。Ta-Libというライブラリに似ていますが、コードの書き方等は異なっていて別物です。
import pandas_ta as taテクニカル指標計算関数
テクニカル指標計算用の関数としてcalc_indicatorsを定義します。
def calc_indicators(df):
#四本値の取得
open = df['Open']
high = df['High']
low = df['Low']
close = df['Close']
#テクニカル指標の計算
MA = ta.sma(close, timeperiod=14)
DMP = ta.adx(high, low, close)["DMP_14"]
DMN = ta.adx(high, low, close)["DMN_14"]
ATR = ta.atr(high, low, close, timeperiod=14)
#テクニカル指標の格納
df['ATR'] = ATR
df['MA'] = MA
df['DMP'] = DMP
df['DMN'] = DMN
return dfなお、DMPはDMIの+DI、DMNはDMIの-DIを表します。また、各テクニカル指標の内容は以下の記事で解説しています。合わせてご覧ください。
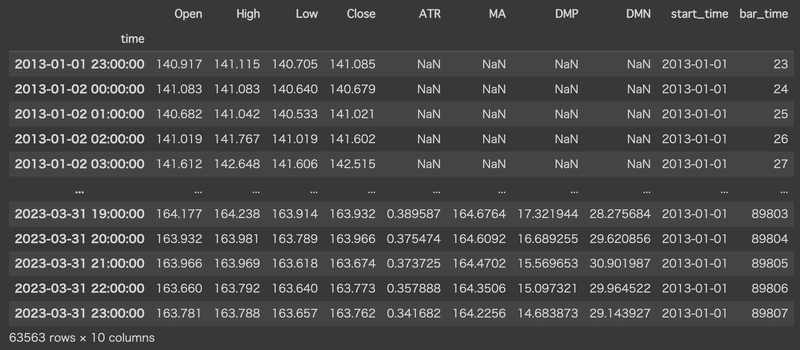
テクニカル指標とbar_timeの追加
先ほど読み込んだdf(データフレーム)形式のbarデータに、テクニカル指標とbar_timeを追加します。
start_time = datetime(2013, 1, 1, 0, 0, 0, 0)
df = df_H1
df = df.dropna()
df = calc_indicators(df)
df = df.reset_index()
df['start_time'] = start_time
delta = (df['time'] - df['start_time']).dt
df['bar_time'] = (df['time'] - df['start_time'])//timedelta(minutes=60)
df = df.set_index('time')
df.to_pickle('/content/drive/My Drive/bar/GBPJPY_H1_ii.pkl')
df = df_M15
df = df.dropna()
df = calc_indicators(df)
df = df.reset_index()
df['start_time'] = start_time
delta = (df['time'] - df['start_time']).dt
df['bar_time'] = (df['time'] - df['start_time'])//timedelta(minutes=15)
df = df.set_index('time')
df.to_pickle('/content/drive/My Drive/bar/GBPJPY_M15_ii.pkl')
df = df_M5
df = df.dropna()
df = calc_indicators(df)
df = df.reset_index()
df['start_time'] = start_time
delta = (df['time'] - df['start_time']).dt
df['bar_time'] = (df['time'] - df['start_time'])//timedelta(minutes=5)
df = df.set_index('time')
df.to_pickle('/content/drive/My Drive/bar/GBPJPY_M5_ii.pkl')
df = df_M1
df = df.dropna()
df = calc_indicators(df)
df = df.reset_index()
df['start_time'] = start_time
delta = (df['time'] - df['start_time']).dt
df['bar_time'] = (df['time'] - df['start_time'])//timedelta(minutes=1)
df = df.set_index('time')
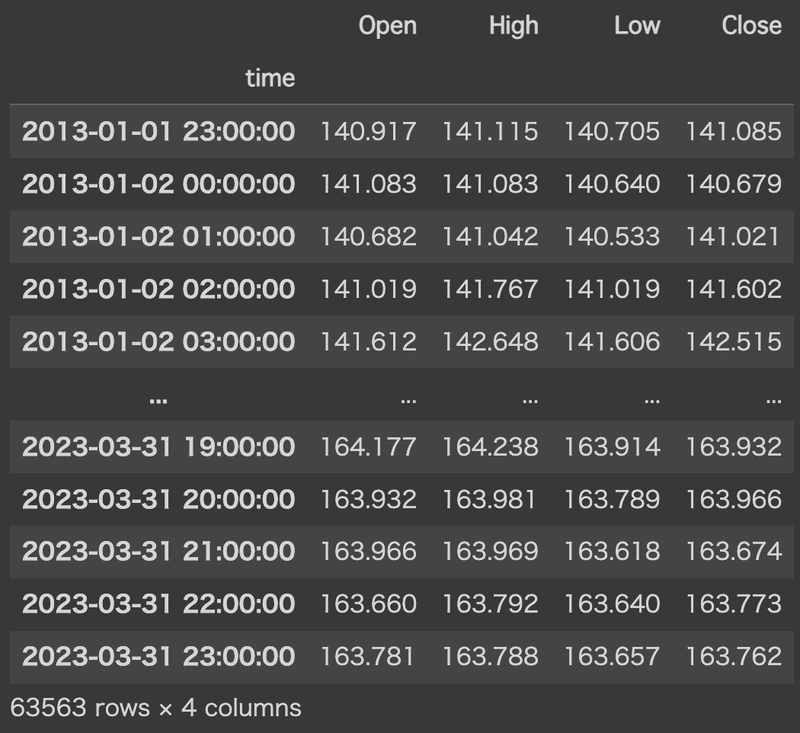
df.to_pickle('/content/drive/My Drive/bar/GBPJPY_M1_ii.pkl')bar_timeというのは、2013年1月1日の0時を基準とした経過時間を整数で表したものです。
例えば、以下の実行結果(GBPJPY_H1_ii.pklの例)であれば、
・2013-01-01 23:00:00→23時間後
・2023-03-31 20:00:00→89,807時間後
といった形です。
後ほど、tickデータとbarデータを連結するために使用します。
実行結果
tickデータにテクニカル指標を追加
ここからは、tickデータにもテクニカル指標を追加する処理です。
barデータの読み込み
まずは、先ほど作成したテクニカル指標とbar_timeを追加したbarデータ(.pkl)を読み込みます。
df_M1 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_M1_ii.pkl')
df_M5 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_M5_ii.pkl')
df_M15 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_M15_ii.pkl')
df_H1 = pd.read_pickle('/content/drive/My Drive/bar/GBPJPY_H1_ii.pkl')tickデータにbar_time追加
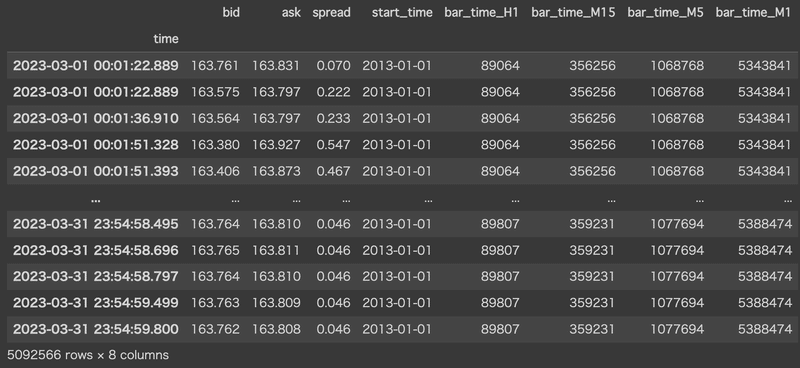
続いて、tickデータにもbar_timeを追加します。datetime形式(2013-01-01 23:00:00など)の時間を、各時間足ごとの整数値に変換することによってマッチングさせやすくします。
start_time = datetime(2013, 1, 1, 0, 0, 0, 0)
for YYYYMM in tqdm(YYYYMM_list):
df = pd.read_pickle('/content/drive/My Drive/tick/GBPJPY_tick_'+YYYYMM+'.pkl')
df = df.fillna(method='ffill')
df['spread'] = df['ask'] - df['bid']
df = df.reset_index()
df['start_time'] = start_time
delta = (df['time'] - df['start_time']).dt
df['bar_time_H1'] = (df['time'] - df['start_time'])//timedelta(minutes=60)
df['bar_time_M15'] = (df['time'] - df['start_time'])//timedelta(minutes=15)
df['bar_time_M5'] = (df['time'] - df['start_time'])//timedelta(minutes=5)
df['bar_time_M1'] = (df['time'] - df['start_time'])//timedelta(minutes=1)
df = df.set_index('time')
df.to_pickle('/content/drive/My Drive/tick/GBPJPY_tick_a_'+YYYYMM+'.pkl')以下の通り、それぞれの時間足を基準としたbar_timeをセットしました。
有料部分の内容
これまで準備してきた内容を用いて、以下の処理を行います。
機械学習用データの作成
それぞれのデータに追加したbar_timeをキーとして、tickデータにbarデータで計算したテクニカル指標を追加するのですが、それと同時に、機械学習の目的変数yを定義して追加して、以下のようなデータを作成するためのコードを掲載しています。

テクニカル指標(MA, DMI, ATR)を追加しています。見やすくするために少し表示を削っていますが、DMIについては1分足(M1)〜1時間足(H1)をそれぞれ追加して使用するロジックになっています。MAは1分足(M1)を、ATRは1時間足(H1)をそれぞれ使用します。
buyモデル用の目的変数(buy_y)とsellモデル用の目的変数(sell_y)をそれぞれ分けて追加しています。buyモデルというのは、buy(ロング)ポジションのみを考えるモデルで、sellモデルというのは、sell(ショート)ポジションのみを考えるモデルです。
より具体的には、1分足を用いて何分後(何レコード後)に利確目標に到達するかを計測しています。ロスカット基準よりも先に利確目標に到達した場合はbuy_y=1となり、到達までにかかった時間(レコード数)がbuy_ytで示されます。
機械学習の二値分類について
機械学習の二値分類とは、入力データを2つのクラス(たとえば「0」と「1」)に分類するタスクを指します。上記のように設定すれば、「利確目標に達する」と「ロスカットされる、または引き分け」のどちらになるかをモデルは入力データに基づいて予測します。
一方、三値分類(または多クラス分類)は、入力データを3つ以上のクラスに分類するタスクを指します。たとえば、「利確目標に達する」、「ロスカットされる」、「引き分け」の3つのクラスのいずれに該当するかを分類する場合などが考えられます。三値分類の場合、出力は「0」、「1」、「2」のようにyを3つのクラスに分類する必要があります。
今回は、buyモデルとsellモデルを分けて、それぞれの勝ちパターンのみを予測する二値分類を想定して話を進めます。
その他、機械学習以外の部分は、ADM-EAのロジックをベースにしています。詳細は以下の記事で解説しています。合わせてご覧ください。
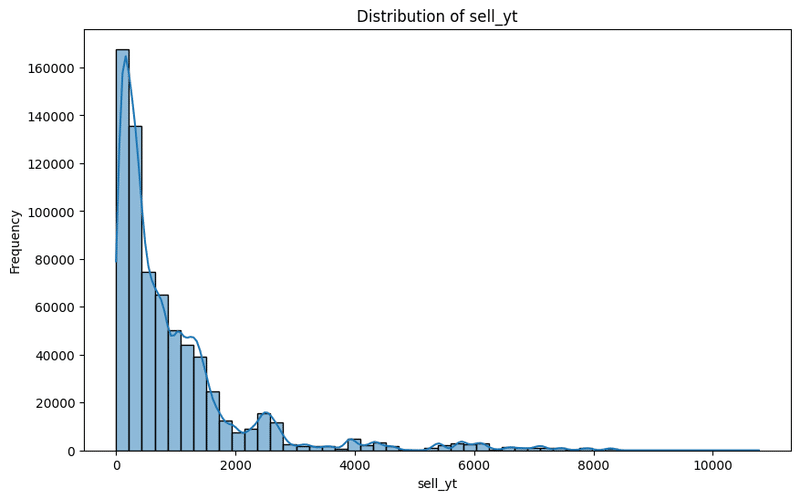
目的変数yの分布の確認
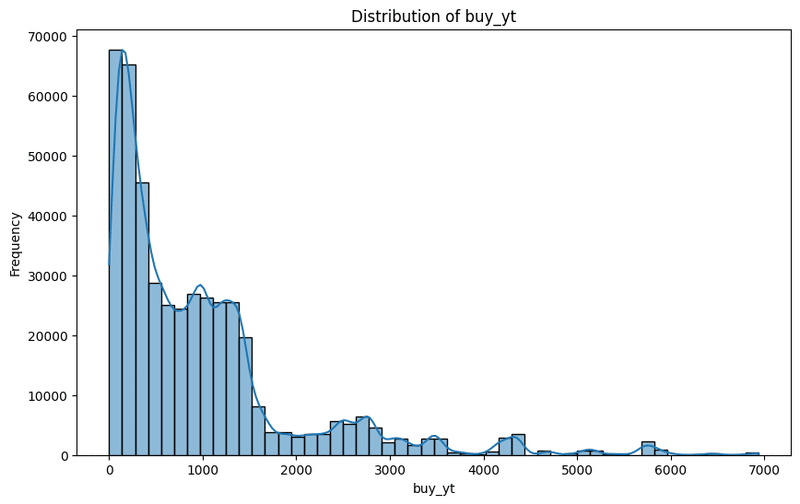
作成した目的変数yについて問題なく設定できているか分布を確認するコードもご紹介しています。
以下はbuy_ytおよびsell_ytの分布ですが、単位は"分"と考えて良いので、ポジションを持ってからクローズするまでの時間が大体720分以内(半日以内)で、24時間(1440分)以上かかるようなケースはそれほど多くないことが確認出来ます。
利確幅やロスカット幅の設定によっては全然ポジションをクローズしないということも考えられるので、取引頻度や平均ポジション保持期間を観察するのに利用します。
学習用のtickデータの調整
機械学習において、学習用のデータが多いことは一般的には有利とされています。ただし、用意したtickデータは2023年3月の1ヶ月分だけでも5,092,566レコードと非常にデータサイズが大きいです。1年間分のデータで学習するだけでも非常に時間がかかってしまいますし、スペックによってはメモリ不足で実行完了出来ないということもあり得ます。
そこで、tickデータを一定の条件で絞って学習用のデータを切り取ってサイズを落とす調整を行う方法をご紹介しています。
LightGBMの学習方法およびバックテスト方法
有料部分では、
・Google ColabでLightGBMの学習を行う方法
・学習したモデルを用いてGoogle Colabでバックテストを行う方法
をそれぞれ具体的なサンプルコードを掲載して説明しています。
具体的には、以下のようにGoogle Driveのmodelフォルダに学習したbuyモデルとsellモデルをそれぞれ保存し、それを呼び出すためのサンプルコードも掲載しています。

バックテスト結果の確認方法
以下のようにLigtGBM(機械学習モデル)による予測を取り入れなかった場合と予測を取り入れた場合の損益グラフを比較する方法もご紹介しています。


パフォーマンス指標の確認方法
以下のように、総損益、プロフィットファクター、取引数、勝率といったパフォーマンス指標を計算して、LightGBMによる予測を取り入れなかった場合と取り入れた場合で比較する方法をご紹介しています。


なお、この結果は、2022年1月〜2022年12月の1年間のデータで学習して、2022年10月〜2023年3月の6ヶ月間でバックテストを行った結果です。
LightGBMによる予測を取り入れた結果、取引数が限定されて勝率が上昇していることがわかります。
ただし、上記の通り2022年10月〜2022年12月については学習した期間とバックテスト実施期間が重なっていることにご注意ください。答えのあるデータで学習してバックテストを行えば、結果が良好になるというのはある意味当然です。その確認も含めて行っています。
全てのコードを掲載した.ipynbファイルのダウンロード
この記事でご紹介している全てのコードを掲載した.ipynbファイル(Google Colabで実行可能なファイル形式)をダウンロード可能にしています。記事のコードのコピペで上手くいかない場合等にご活用ください。基本的には、そのままGoogle Colabで実行可能かと思います。
なお、ここまでに説明している無料部分のみのファイルは以下からダウンロード可能です。
LightGBMの学習とバックテスト(無料版).ipynb
注意点
当記事で掲載しているコードはGoogle Colab上での実行を想定しています。また、取引シミュレーションを行うバックテスト用のコードです。そのままでは実際のFX取引に使用出来ません。
当記事ではあくまで機械学習のサンプルコードを掲載しているのみで、そのまま使用して精度の高い結果が得られることを保証するわけではございません。学習やモデルの精度を高める取り組みをご自身で行っていただく必要があります。
エラー等が発生しないことを確認しておりますが、状況が変わり実行が出来なくなってしまう可能性もございます。
紹介している画像等と全く同じ結果が出ることを保証するものではございません。
ここから先は
¥ 3,000
よろしければサポートお願いします。いただいたサポートは今後の記事の執筆に活用させていただきます。