
【ビジネスマン必読書『君主論』全文を統計解析してみました】第4回:具体的な準備手順を公開!

※第4回と第5回では、今回のデータ分析に使用したソフト、使用したロウデータの収集方法の詳細を説明しています。分析の細かい手法に興味がなく早く結果を知りたい方は一足飛びに第6回に進んでいただいて構いません
※また本記事は2019年6月18日時点での情報となります。使用ソフトのバージョンやリンク先存在確認はあくまで執筆時点での最新情報となりますのでご了承ください
世界的古典のウンチクを語れる知性派オトナになりたい人の為のデータ分析と題して、マキャベリの名著『君主論』の全文を解析していくこのシリーズ、今回は事前準備の詳しい手順をご説明しますね。
1:テキストマイニング用のフリーソフトウェアとしてKH Coderをインストールする
テキストマイニング用のツールとしては、現在のところ、立命館大学の樋口先生によって開発されたKH Coderがダントツのオススメと言えそうです。
ユーザーの層が厚いということで信頼性が高い上に、ネット上で実例やノウハウの情報を集めやすいのが利点です。それでいてフリーソフトですから!
《インストール手順(2019年6月時点)》
・KH Coderの公式サイトに入る
・「最新版をダウンロード」をクリックしてください
・ダウンロードされたインストーラーをダブルクリックで起動
・画面の手順に従ってインストール先フォルダを指定し[Unzip]を押す
・インストールが完了するとフォルダが自動生成されています
・そのフォルダの中にある[kh_coder]アイコンをダブルクリックすることでソフトの起動を確認してください
以下のような画面が起動されれば、インストール成功です。
2:分析ソフトしてRをインストールする
KH Coderだけでもかなり詳細なデータ分析が可能ですが、補助ツールとしてRも準備しておきましょう。
今回の話に限らず、データ分析に興味のある方は、ともかくRをインストールして普段から遊び半分で使ってみることをオススメします。何せこんなに高機能なソフトが無料ですし!
インストーラがダウンロードできるミラーサイトはこちらとなります。
またRの補助環境を実装したツールとして、Rstudioもインストールしておきましょう。
※もっとも今回の分析ではRとRstudioあくまで補助ツールとしてのみ使いますので、インストール手順の詳細は割愛します。記事を読んで「KH CoderではできないことをRで実現した」箇所に興味を持ったら、試してみてください。
3:ウィキソースから原文テキストデータを入手する
今回使用するのはマキャベリ『君主論』のイタリア語版となります。
これはWIKISORCEに掲載されている1814年版のものを使用することにします。
上記のWIKISORCEのページに入り、内容を[capitolo01.txt]、[capitolo02.txt]...と、章ごとにテキストファイルにしてローカル端末に保存していきます。今回のテキストはイタリア語で解析するので、文字コードはUTF-8で保存をしておきましょう。
章単位のテキストファイルにしたのは、後で「各章による傾向の違い」を細かく分析する計画があるからです。KH Coderには「複数のテキストファイルを結合して分析」というオプション機能がついているので、素材ファイルが複数になることは問題がありませんし、自分が分析したい単位でファイル分割しておくことはむしろ望ましいと言えます(※もっとも、これは分析者の好みもあるかもしれませんので、あくまで「私の場合のやり方」です)。
また今回の分析では「著作中に登場する人物名」にフォーカスしていくので、序章の冒頭、「NICC. MACHIAVELLI al MAGNIFICO LORENZO DI PIERO DE’ MEDICI.(ニコロ・マキャベリからロレンツォ・メディチ殿に献ぐ)」という一文もデータ内に含みます。なお序章のファイル名は「dedica.txt」としておきます。
できあがった、[dedica.txt]および[capitolo01.txt]~[capitolo26.txt]を、[principe_raw]というフォルダを作ってそこに集めておきます。

このフォルダには素材テキストファイルだけを入れておき、かつ、ここに格納したファイル自体はバックアップとみなして直接編集はしない方針とします。
この段階でも最低限の分析は可能です!ちょっとやってみましょう
あくまでお遊びという程度なら、以下の手順でも、最低限「テキストマイニングっぽい」雰囲気を楽しむことは可能です。
・KH Coderを起動する
・「ツール」>「プラグイン」>「データ準備」>「テキストファイルの結合」と進みます
・先ほど作成した[principe_raw]フォルダを参照します
・今回のテキストはイタリア語なので、文字コード=UTF-8を指定することを忘れないでください
・結合したファイルの保存先を指定します。今回はサンプル出力なので、[sample_analysis]等のファイル名で、一時的に適当な場所に保存しましょう
・続いてKH Coderのメニューに戻り、「プロジェクト」>「新規」と進みます
・さきほど作成した[sample_analysis]ファイルを参照します。言語はイタリア語、辞書はfreeLingを指定し、[OK]を押します
・メニューに戻り、「前処理」>「前処理の実行」と進みます([OK]押下後、少し時間がかかります)
・メニューに戻り、「ツール」>「抽出語」>「抽出語リスト」と進んでください
・以下のように、本文中に使われている単語の頻度リストが表示されれば成功です!
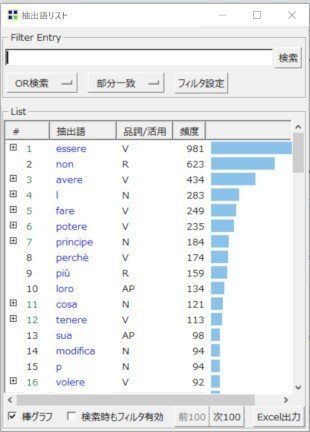
できたー!
・・・と思うのも束の間のこと。このままでは分析には進めません。
まず、最頻出語として出ているessereは、英語でいう[am,are,is]にあたる基本動詞。三番目のavereは英語でいう[have]でイタリア語では過去時制に多用されます。これらが「頻出」なのは当たり前。
他に、人称代名詞(英語でいうIやyou)が入っていたり、前置詞が入っていたり、はては「P」とか「L」とかいった文字一つだけのナゾの「名詞扱い」語が混在していたりしています。
このまま分析ソフトにかけてもめちゃくちゃな結果しか出てこないでしょう。
というわけで、この後、今回の結果で「ダメだったところ」を少しずつ補正していく、データクレンジングの手順に入ります。この手順がいちばんシンドイところですが、外国語好きな方にはたまらない魅力に満ちた作業となるはず!(外国語嫌いの人はできるだけ他人に任せてすっ飛ばしたくなる工程ともいえます)
というわけで次回は、データクレンジングの手順を紹介していくことにしましょう!
子供の時の私を夜な夜な悩ませてくれた、、、しかし、今は大事な「自分の精神世界の仲間達」となった、夢日記の登場キャラクター達と一緒に、日々、文章の腕、イラストの腕を磨いていきます!ちょっと特異な気質を持ってるらしい私の人生経験が、誰かの人生の励みや参考になれば嬉しいです!