
一般物体認識YOLOv3のモデル構造

はじめに
一般物体認識とは、画像中の物体の位置を検出し、その物体の名前を予測するタスクになります。以前に下記の記事を書きましたが、そこでも扱ったようにYOLOv3は一般物体認識のモデルの中でも有用な手段のひとつです。今回はこのYOLOv3の中身をポイントとなるところに注目して、見ていきたいと思います。
YOLOv3: An Incremental Improvement
モデルの外観
YOLOv3のネットワークの外観は以下のようになります。入力の画像に対して出力は縦横が13x13、26x26、52x52の3種類のテンソルが3つ出力となります。このサイズは入力の416x416をそれぞれ(1/32)、(1/16)、(1/8)としたものになります。また、各セルは[3x(4+1+80)]のサイズのベクトルになっており、[(3週類のpriorのサイズ)x((横位置tx, 縦位置ty, 横幅tw, 縦幅th), 物体の存在確率 Objectness score, 各クラスの所属確率)]に対応します。priorのサイズというのが分かりにくい点ですが次項で説明します。
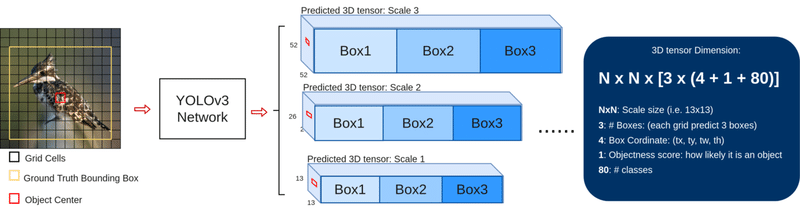
priorの利用
YOLOv3では事前情報として、「データセットにどのくらいのサイズの画像があるか」という情報を使っています。その情報は正解ラベルのバンディングボックス幅をk-meansによって9つのクラスタリングを実行して得ています。この9つを3つずつ各サイズの予測テンソルに割り当てます。このサイズが前項で登場したpriorのサイズとなります。このpriorからのオフセットを計算する(priorのサイズを基準にどれだけの大きさかを決める)ことで、予測するバンディングボックスのwidthとheightが決定されます。学習のときは、正解データのバンディングボックスとの重なり(IOU)が最も大きいpriorサイズのboxのObjectness scoreを1とします。
このpriorのサイズはCOCOデータセットをクラスタリングして得たものなので、オリジナルのデータセットで学習を行なうときは、データセットごとにクラスタリングしてpriorのサイズを求めるのが適切です。また、各boxに与えるサイズの数やscaleの数などもデータの性質によって精度への影響の与え方は変わってくるのではないかと思います。
予測の計算
予測するバンディングボックスは出力テンソルの(tx, ty, tw, th)を用いて以下のように処理が行われます。
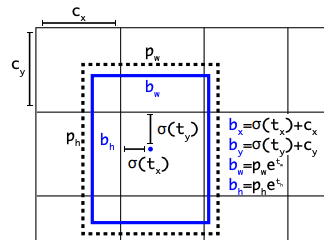
図参照: YOLOv3: An Incremental Improvement
ボックス中心のbw、bhはtx、tyからそれぞれ計算されます。cはそのセルまでの距離でtx、tyはシグモイド関数を通してそのセル内のどこに位置するかを出力しています。また、pw、phは先程のpriorのサイズを表していて、それに対してどれくらい大小するかを底がeの指数関数で計算しています。
ネットワークアーキテクチャ
YOLOv3のネットワークアーキテクチャを以下に示します。Scale1、Scale2、Scale3がそれぞれ52x52、26x26、13x13を表しています。UpsamplingしてConcatするような構造になっており、少々複雑ではあります。

損失関数
損失関数は以下のようになります。

式参照: YOLOv3 loss function
x、y、w、hのバウンディングボックスの大きさに関わる項は二乗誤差が使われ、classの項はcross entropyです。obj (objective score)の項はオブジェクトがセルの中に存在するかどうかで2つ項に分かれています。

実装例 Pytorch
・eriklindernoren/PyTorch-YOLOv3
・ayooshkathuria/pytorch-yolo-v3
・DeNA/PyTorch_YOLOv3
損失関数の設計がそれぞれで少し異なるところもあります。
1から実装する実装の仕方を解説してある記事もあります。
・How to implement a YOLO (v3) object detector from scratch in PyTorch: Part 1
まとめ
以上で、YOLOv3の説明は終わりますが、細かいところを見たい場合は上に挙げたコードを読むと分かると思います。あとは、解説記事も分かりやすいので興味があれば読んで見るとよいと思います。
最後に
私が所属している株式会社ACESでは、Deep Learningを用いた画像認識技術を中心に、APIによるアルゴリズムパッケージの提供や、共同研究開発を行なっています。特に、ヒトの認識・解析に強みを持って研究開発を行っておりますので、ご興味のある方は、ぜひお問い合わせください!
【詳細・お問い合わせはこちら】 acesinc.co.jp sharon.jp
◆画像認識アルゴリズム「SHARON」について
ヒトの行動や感情の認識、モノの検知などを実現する画像認識アルゴリズムを開発しています。スポーツにおけるパフォーマンス分析やマーケティングにおけるヒトの心の動きの可視化、ストレスなどの可視化による健康状態の管理を始めとするAIアルゴリズムを提供しています。
この記事が気に入ったらサポートをしてみませんか?