
層に着目したLLMの口調の学習について

こちらは【第3回】生成AIなんでもLT会の登壇内容のnoteです。
👇【第3回】生成AIなんでもLT会のリンクはこちら
👇登壇資料はこちら(PDF化した時にサイズ変更があり、少しバグっているようです。)
はじめに
LLMのファインチューニングをしていると、ふと「学習した情報ってどこに保存されているんだろう?」と思うことはありませんか?
LLMの知識がどこに保存されているのかというお話は、議論されていて「全結合層に知識が保存されている」という仮説などあります。
またZennでは以下のような事実の学習に関する実験記事もあったりします。
LLMの文脈だと、「知識の学習」と「形式の学習」は別物とすることが多く、前者は上記のように注目されがちですが、後者は相対的に注目度が低いです。
自分のお気持ち的にはLLMのファインチューニングにおいて「学習した情報がどこに保存されるのか」を確かめたいものの、それはあまりにも難しいです。
よって今回は「どの層だったらLLMのファインチューニングってうまくいくの?」という問いを立てて実験したいと思います。
手法
モデル
モデルはrinna株式会社が開発した3.6 Bのrinna/japanese-gpt-neox-3.6bを採用しました。
本モデルはMITライセンスで公開されています。(2024年3月10日時点)
データセット
データセットは、以下のdollyの語尾を「ござる」としたデータセットも用います。
本家のdollyデータセットと同じく、本データセットもCC BY-SAライセンスで公開されています。(2024年3月10日時点)
本データセットを用いたファインチューニングの目的は、モデルの出力に「ござる」を含ませることとしました。(厳密に今回の目的を、文末を「ござる。」にすることとは定義していません。なぜなら、モデルの出力が「~~~ござるよ。」のように「ござる」の変化形?で出力されたとしても、学習の目的を満足していると判断したためです。)
ファインチューニング
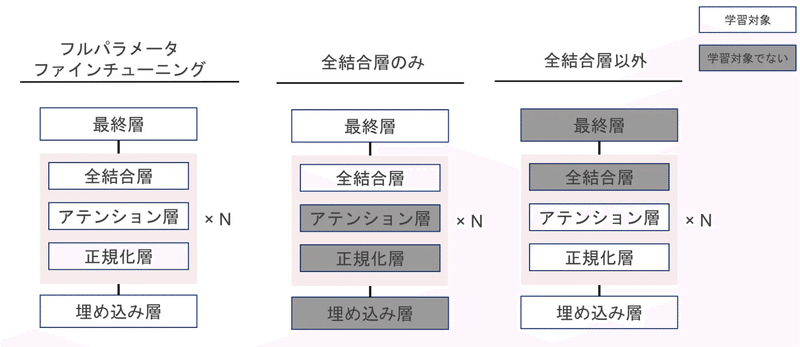
まず層の種類によってファインチューニングの性能が変わるかどうかを調べます。
先述したように知識の学習には全結合層が重要である仮説があるので、今回の口調(ござる)の学習でも全結合層が重要であるかを調べます。具体的には「全結合層のみ」「全結合層以外」の重みのそれぞれを学習させます。
またLLMのモデルの最終層にも全結合の構造が用いられているため、今回は最終層の全結合層の重みも更新します。
次に層の位置によってファインチューニングの性能が変わるかどうかを調べます。今回は「入力に近い層」「出力に近い層」「ランダムな層」の3種類をファインチューニングします。上記3つはすべてモデルの重みの5%,10%になるように層を抽出しています。
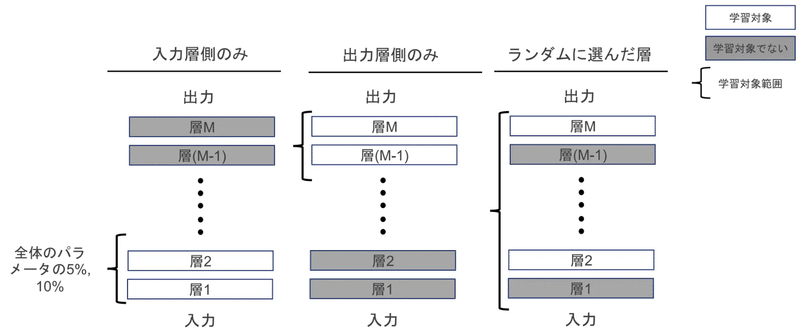
深層学習系の研究に携わっている方はピンときている方も多いとは思いますが、着想は転移学習のそれと同じです。ですので、「層の後半部分を学習するとうまくいきそうである」というのは、直感的に感じることです。そして層の前半部分やランダムにしたらうまくいかないんじゃないか?と筆者は予想していました。
上記のファインチューニング関係のプログラムはZennでコードを公開しています。
Flash AttensionとDeepSpeed使って学習をしています。
今回訓練データセットの数は4,000とすると、フルパラメータファインチューニングは30分~40分ほどで終わります。
学習データセットは経験則より1,000くらいあれば足りるだろうと思ったのですが、思いの外学習できておらず、数を4,000にしました。
評価指標
今回は、「出力にござるが含まれている割合」として「ござる率」を定義しました。
モデルの出力が複数文であった場合でも、どこかに「ござる」という文字列が含まれていれば正例としています。
結果
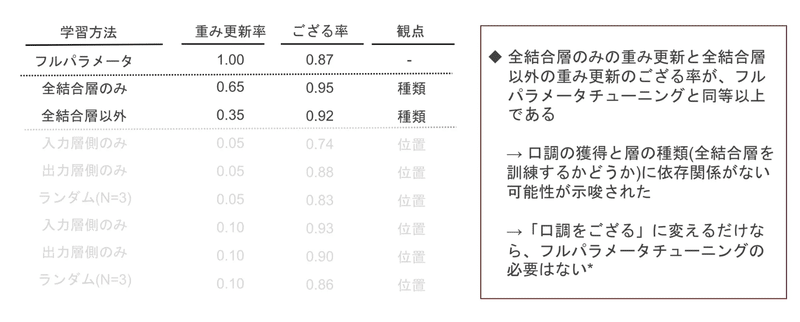
層の種類に着目した結果
以下のように層の種類に関係がなく、「ござる」という口調を獲得できることがわかりました。
層の位置に着目した結果
以下のように層の位置に関係がなく、「ござる」という口調を獲得できることがわかりました。
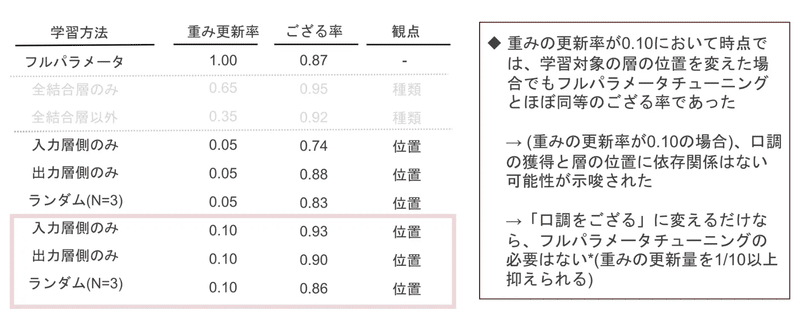
(ランダムの結果はN数=3で、とても少ないので細かい数字にはそれほど信憑性はないものの、全体の傾向を掴むという観点では一定の役割を果たしていると思われます。)
さいごに
概ね層の種類や層の位置はあまり関係がなく、「ござる」という口調を獲得できることがわかりました。
ただ注意していただきたいのは、本結果はあくまで一モデル、一データセット、一学習条件での結果でしかなく、問題設定においては上記の結果が担保されない可能性もあります。(特にタスクを難しくするとどうなるのかは、個人的に気になるところです。)
また今回はファインチューニング後の「ござる率」に着目しましたが、汎化性能はどうなっているか、破壊的忘却は起きているのかどうかには言及していないので、結果の取り扱いには注意が必要です。
今後の展望として、本noteの続きとして「層に着目したファインチューニングによる汎化性能の調査」を(本noteが好評であれば)あげる予定です。また今回は単純なファインチューニングに焦点を絞っていますが、PEFT系のファインチューニングでも層に着目した調査をし、報告したいと思っています。
さらに今回は重みの勾配や変化率等のナイーブな解析はしておりません。本来であれば、並行して解析をしっかりやるべきなのですが、次回以降に回したいと思います。
長々とお付き合いありがとうございました。
この記事が気に入ったらサポートをしてみませんか?