
LLMと仲良くなろう:LLMの個性を知って連携する ~桃太郎ってどんな話~

研究開発本部 塩見誠
はじめに
本稿では、我々が開発しているエッジデバイス上で動作するCE-LLMの回答精度を改善するためのアプローチについて紹介します。CE-LLMは複数のLLMがユーザーからの質問に応じて選択したり、連携したりして回答を生成する特徴があります。
今回は、その前段階としてLLMのプロンプト理解における個性を把握して、連携の可能性を探ってみます。
LLMの個性とはどういうこと
LLMの特徴は、学習内容と学習量に依存してきまる回答の正確さや、信頼性などが、最初に浮かぶことですが、LLMとそれなりに付き合ってきたみなさんならこんな経験があるはずです。
ChatGPTなどのLLMを使用していて、「言いたいことがうまく伝わらない」と感じたり、「LLMは本当に私の言っていることを理解しているのだろうか?」と疑問に思ったことはありませんか?LLMに対して意図を伝えるための手段として、プロンプトエンジニアリングという技術が存在します。しかし、その前段階として、「そもそもLLMは私たちのプロンプトをどの程度理解しているのか?」という問いについて、本稿で解説します。これにより、「なるほど、それがLLMの個性なのか」と感じていただければ幸いです
実験
今回の実験では、LLMに童話「桃太郎」をベースにした簡単なお題を予備知識として与え、その内容について質問します。これまでに紹介したRAG(Retrieval-Augmented Generation)やファインチューニングは、LLMに知識を与えて期待する出力を導くための重要な技術ですが、これらは正解を導くためのもので、与えた予備知識をどれだけ人間的に理解しているかという話とは別です。今回は、予備知識に基づいて答えるのではなく、与えられたお題をどれだけ深く理解しているかを、直接LLMに尋ねます。実験1では、2つのLLMに対して、同じ質問を投げかけて、その回答を比較します。実験2では、実験1で得られた、それぞれのLLMの回答の良いところに着目して、その回答を統合し、その結果について考察します。
実験1 LLMの個性を確認する
今回使用するLLM
LLM1:ChatGPT API (モデル: GPT-4) GPT-4 (openai.com)
LLM2:elyza/ELYZA-japanese-Llama-2-7b-instruct · Hugging Face
今回使用する一つ目のLLMは、皆さんおなじみのChatGPT(GPT-4)です。GPT-4は2023年3月15日よりOpenAIで利用可能となり、現在では世界中に爆発的に利用者が広がっています。OpenAIではGPT-4の特徴として、「日常的な会話ではGPT-3.5とGPT-4の違いは微妙で、その違いはタスクの複雑さが一定の閾値を超えたときに現れる」と述べており、プロンプト理解が進んでいることが期待されます。
もう一つのLLM、ELYZA-japanese-Llama-2-7bは、Llama2を基に日本語能力を拡張するために追加の事前学習を行ったモデルです。ELYZA独自の高品質指示データセットを用いた事後学習を行い、複数ターンの対話にも対応できる小規模ながら期待できるLLMとなっています。詳細はこちらのブログをご覧ください。
今回のシステムプロンプト
システムプロンプト:
あなたは、優秀なライターであり、提示されたテーマを指定された立場から200文字以内で簡潔にまとめることができます。指示に従って文章を書いてください。
お題:ある日、川で洗濯をしていた老婦人が大きな桃を見つけ、夫と共にそれを食べようと切った瞬間、桃から元気な男の子が現れる。彼らはその子を「桃太郎」と名付け、愛情をもって育てた。成長した桃太郎は鬼が村を困らせていることを知り、鬼退治を決意。母親からもらったきびだんごを使ってキジ、サル、犬を仲間にし、四人で鬼島に向かった。彼らは団結し、鬼たちを退治。平和を取り戻した村に帰還した。
このお題は桃太郎に基づいて作成しました。これをせずに単に、プロンプトで「桃太郎について教えて」と指示すると、”元々LLMがどれだけ桃太郎という話を知っているのか”という学習による知識の比較になってしまい、プロンプトの理解度を公平に比較できません。そのため、システムプロンプトとして最小限の開始ラインを設定しました。
今回のユーザープロンプト
ユーザープロンプトとしては、お題に関する質問を与えます。
今回検討したのは、次の6つの質問です。つまり、お題を様々な観点から再構成するための質問であり、お題を知っているだけでは十分でなく、その意味を理解していることが重要です。
今回は、この中から質問2と質問3を例として説明します。その他の質問に対する答えに興味があれば、最後の付録を読んでください。
下記に、用意した6つの質問を示します。太字になっている質問が本文で紹介する質問です。
お題の内容を説明してください。
お題を老夫婦目線からのお話にしてください。
お題を鬼目線からのお話にしてください。
お題を桃太郎目線からのお話にしてください。
お題を犬目線からのお話にしてください。
お題に出てくるきびだんごに意識があったら、きびだんごはなにを思っていたか書いてください。
観察方法
用意したシステムプロンプトとユーザープロンプトを用いて、桃太郎を題材にしていろいろと質問してみました。桃太郎のお題を様々な観点で再構成してもらうことによって、LLMが与えられたプロンプト(お題)をどのように理解しているかという個性を見ていきます。
ただし、LLMの回答は一定ではなく、同じプロンプトでも常に同じ回答をするわけではありません。また、固定した回答を得るように設定(temperature=0)すると、LLMの可能性を見逃すおそれもあります。したがって、同じプロンプトを複数回与え、その回答の中からお題に対する理解が見えてくるような回答をピックアップして観察しました。この記事を読んで同じ質問をしても必ずしも同じ回答になるわけではないことをご了承ください。
なお、実際のプロンプトと生成パラメータの例を付録に記載しています。
図1に、今回の実験の概略を示します。同じプロンプトを2つのLLMに与えてそれぞれの回答をプロンプト理解度の観点で比較分析します。

結果1 結果とまとめ
それでは、LLMの挙動を具体的に体験して、分析してみましょう。
各表は、次のように構成されています。
質問:LLMに与えた指示であり、ユーザープロンプトとして使用しました。
LLM1:LLM1の回答(回答文そのままを記載しています)
LLM2:LLM2の回答(回答文そのままを記載しています)
分析:各LLMの回答が、指示に対してどのように働いたかを分析しました。分析は筆者の主観であるが、極力LLMに対し肯定的に、優れている点を示したつもりです。また、分析した上で、筆者の思うところをコメントとして追記してあります。



上記プロンプトをベースに用いて、Stable Diffusionで生成
質問を通じて、お題の物語を深掘りすることで、LLMの文章理解が一面的なものではなく、強力な特性や個性を持つものであることが明らかになりました。
具体的には、LLM1は物語の要素を簡潔かつ直接的に描き出す能力が特徴です。その回答は与えられた情報を短くまとめ、物語の主要な要点を素早く把握するのに有用です。物語の要素視点を変えた回答も相互に明確な矛盾がなく、物語の各要素がどのように連携し役割を果たしていたかを明確に示します。これにより、物語の全体像を簡潔に理解するのに役立ちます。
一方、LLM2は物語の要素を詳細に考察し、具体的に再構築する能力が特徴です。各要素の視点から新たに詳細で具体的な物語を再構築し、物語の各要素の背後にある意味や感情を深く掘り下げます。一見、与えられた物語と無関係な展開やエピソードの追加もありますが、これは物語の登場人物の視点を取り入れ、感情を強調するためのものです。その感情を共有することが可能で、これにより人々は感情的なレベルで物語に参加し、物語の深い理解を可能にすることでしょう。ただし、それぞれの回答が必ずしも元の物語を完全に説明できるわけではありません。
実験2 LLMの結果を組み合わせてみる
個性の異なる、意見をぶつけ合い、すり合わせて統合することでより有用で優れた意見が生まれることは、人間同士の付き合いの中でもよく体験することです。LLMでも、同様な効果が得られるのではないでしょうか。
GPT4を用いて、実験1の結果を”いい感じに”まとめてみました。
まとめた結果を分析します。
観察方法
ユーザープロンプト:
あなたは、優秀なライターであり、与えられた指示に従って文章を作成します。与えられるのは、お題に対する質問と、その質問に対するLLM1、LLM2の回答です。あなたは、それぞれのLLMの回答の長所を尊重して、統合することで、質問に対する回答を再構成してください。
結果2 結果とまとめ

分析 LLM1は物語の具体的な要素と詳細を強調することを特徴とする一方で、LLM2は物語のテーマやキャラクターの感情に焦点を当てる傾向があります。これらの違いを理解し、それぞれの特性を活用するだけでなく、これらの要素を適切に組み合わせることで、事実に基づきつつも人の感情に響く、より豊かな回答が得られる可能性があります。今回は、得られた回答を後からまとめましたが、複数のLLMがユーザーの質問に対して共同して議論を行い、その結果を適切にまとめるシステムを構成することで、より人間に寄り添った回答を提供できる可能性を感じます。
まとめ
以上、実験1ではお題の内容を深掘りすることで、LLMのプロンプト理解における個性を観察し、実験2では個性の異なるLLMの回答を統合することを試みました。その結果、
LLMによってその理解内容は大きく異なることが確認できました。
そつなく正確に答えたLLM1と、予想外の深掘りをしたLLM2、どちらがより良く理解しているかは一概には言えませんが、いずれも面白い個性を発揮してくれました。
個性の異なる意見を統合することで、より正確で情感に訴えるいい意味で人間的な良い回答を実現することができました。
今後のCE-LLMを用いたAIパートナーを実現する上で、より人間に寄り添った相棒を実現してくれる重要な手法となることを期待しています。
今後も複合的なLLMの使いこなしについては、色々検討していくつもりです。また、機会があれば紹介しましょう。
参考文献
付録
ここでは、本文中では紹介しなかった、内容を紹介します。興味があれば見てくださいね。
付録1 ELYZAに対する設定
質問4を例に、ELYZA用のプロンプトと生成パラメータを示します。ただし、この通りに設定したとしても、本稿と全く同じ結果が得られるとは限らないことはご承知ください。
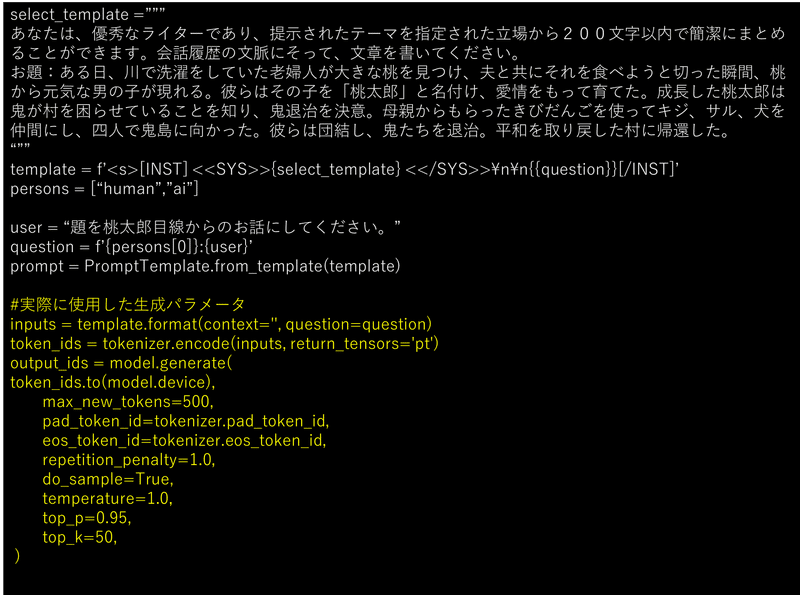
付録2 実験1:その他の質問に対する回答と分析
質問1,4,5,6に対する回答と分析を紹介します。

付録3 実験2:その他の質問に対する統合事例
質問1,4,5,6に対するLLM1、LLM2の回答の統合事例を示す。
付録4 急遽 Google Geminiを試してみた
つい先日(2023/12/8)にGoogleのGoogle Geminiが発表されました。12/13にはProモデルの機能がGoogle AI Studioで利用可能になったので、実験1の質問2,3を試してみました。
なかなかバランスの良い回答をするようです。使いこなし条件はこれから詰めることですが、今後CE-LLMを構成するLLMの候補として継続的に評価しても良いと感じます。
なお、生成オプションはデフォルトです。
また、独自の安全基準(鬼とか退治に反応?)があるのか、お題が寓話であり、文章生成のテストであることを追加で明示しないと不適切な表現を含むとして回答を拒否することがあります。

この記事が気に入ったらサポートをしてみませんか?