
LLM評価データセット概観

研究開発本部 海老原樹
はじめに
このような記事を書くときは、最近では ChatGPT をはじめとした大規模言語モデル(Large Language Model: LLM) の力を大いに借りています。真面目な評価をしなくても、文章力において私はChatGPTに白旗を挙げています。。。
ただ、どのLLMを使うかを決めるときには、LLMの性能を調べる必要があります。特に自分でLLMを開発するときはLLMの性能評価は必須ですよね。社内でもLLMの評価について調査を進めています。今回は「LLM評価の事始め」として、さまざまな角度からLLMを評価するために世の中で使われている評価データセット※1に目を向けてみました。
本記事では、LLMのデータセットサーベイ論文を取り上げ、特にLLMの評価データセットについて概観します。いくつかのデータセットについては、ピックアップして詳細をご紹介します。
※ 英語(とそれに次いで中国語)のデータセットを主に扱う点にご注意ください。
※1 評価データセット(やそれに関連した評価のフレームワーク)では、一般的にそれに対応する評価手法が存在します。実際に、後述するサーベイ論文中では、各評価データセットの属性の一つとして評価手法が含まれています。この記事でも、「評価データセット」という言葉を単にデータの集まりではなく、対応する評価手法も含めた意味で用います。
Datasets for Large Language Models: A Comprehensive Survey
本記事で扱うLLMデータセットのサーベイ論文はこちらです。(2024/02/28 公開)
論文中では、LLMデータセットを大きく以下の5つの視点からまとめ、カテゴリ化しています。
(1) 事前学習コーパス
(2) インストラクション-ファインチューニングデータセット
(3) プリファレンスデータセット(強化学習用データセット)
(4) 評価データセット
(5) 従来の自然言語処理(NLP)データセット
合計で 444 のデータセットが調査されており、LLMデータセットの全体像を把握にするには良い参考資料と言えそうです。 (4) 評価データセットにおいては、代表的な112個のLLMの評価データセットについて、リリース時期、データセットサイズ、使用言語、カテゴリ、評価手法、ライセンス等、計14 種類の属性の情報がまとめられています。以下では評価データセットの内容の一部をご紹介します。
評価データセット概観
言語: 英語、中国語の順で数が多い
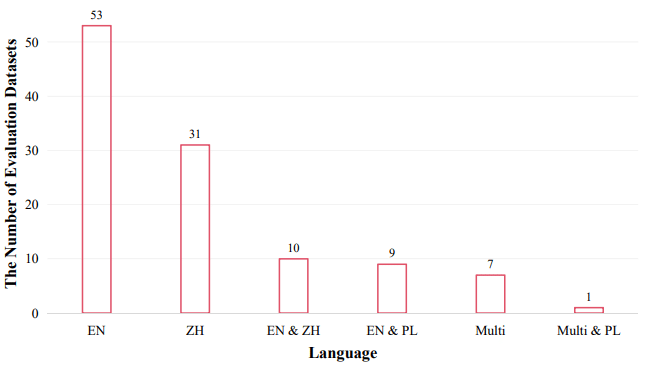
112 個のLLMの評価データセットのうち、半分近くは英語をメインで使用しています。それに次いで、中国語のデータセットが大きな割合を占めています。LLMの研究においては、特に英語と中国語のタスクを評価することに重点が置かれていることがわかります。
そのほかには、プログラミング言語を使ったデータセット、多言語データセットがそれぞれ 1 割弱ずつ存在します。
カテゴリ: 幅広いカテゴリに比較的均等に分布
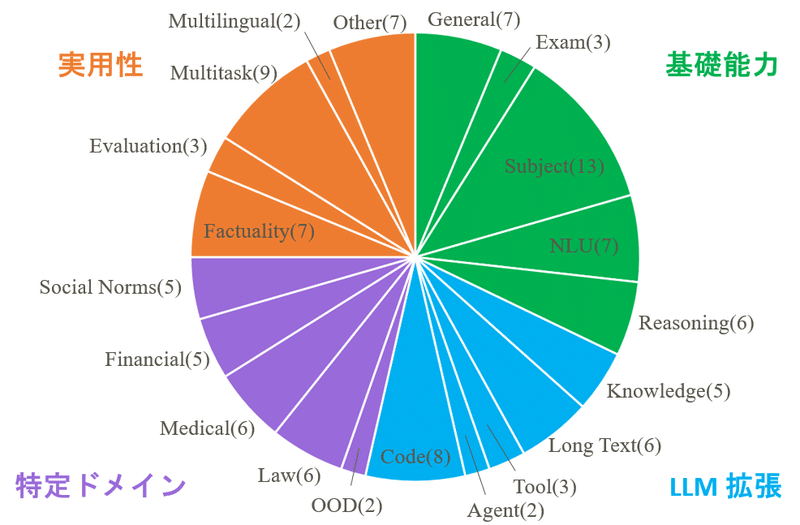
著者らは、評価データセットを20種類のカテゴリに分類しています。また、論文中では触れられていませんが、さらに4つの上位の分野 ー 基礎能力、LLM拡張、特定ドメイン、実用性 ー に分類できそうです。
分布をみると、Subject(さまざまな学問領域で評価するカテゴリ)、Multitask、Codeなどのカテゴリのデータセットの数が多いですが、どのカテゴリも比較的均等に分布していることがわかります。LLMの応用範囲の広さと同時に、幅広い視点からLLMの性能が評価されていることが伺えます。
評価手法: コード評価が支配的
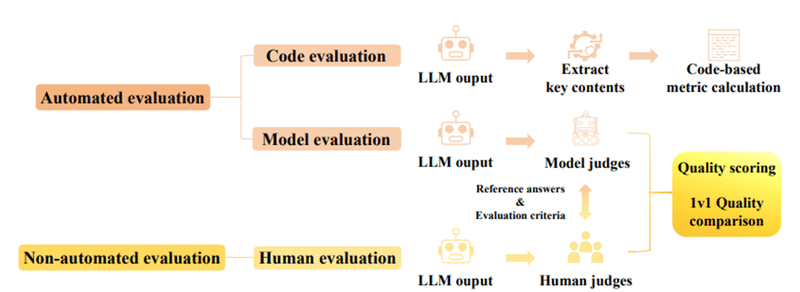
評価手法は、コード評価、モデル評価、人による評価の 3 タイプに分類されます。コード評価はコードを使用して事前に定義された評価指標を統計的に計算する手法です。主な評価指標には、正解率、F1スコア※2、BLEU※3 などがあります。人による評価は、より主観的な評価に適した方法で、(人間の)評価者がLLMの回答を評価します。人による評価では、品質スコアリング、品質比較評価などの方法がとられます。モデル評価は、この人による評価をLLMに代替させる手法です。
コード評価とモデル評価はパイプラインを通じて評価を自動で行います。一方で人による評価は、非自動的な評価です。
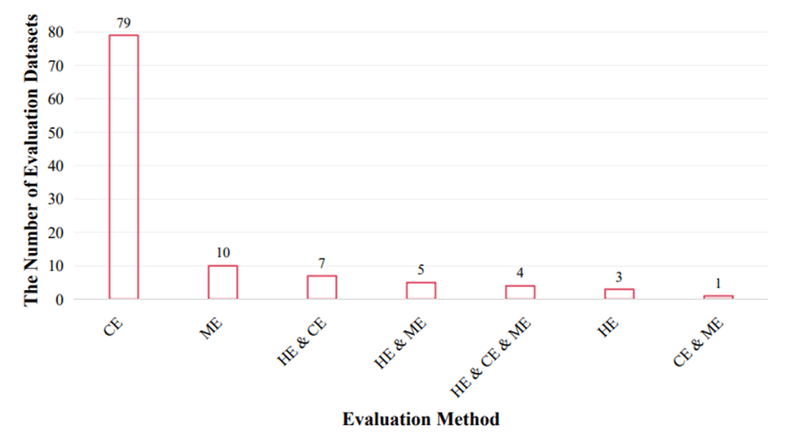
評価方法の分布については、コード評価が大半を占めています。コード評価は自動で評価行えること、客観的な指標を用いることから、効率性と一貫性に優れていることが理由として考えられそうです。
人による評価を行うデータセットは、コストの観点からか、数が少ないです。モデル評価手法は、評価に使うLLMの性能に依存するという課題がありますが、人による評価の欠点をカバーする手段として、今後は数を増やしていくかもしれません。
※2 適合率(Precision)と再現率(Recall)のバランスを評価する指標。
※3 候補文と参照文とのn-gram(連続するn個の単語)がどれだけ一致しているかを評価する指標。
「人気な」評価データセット
サーベイ論文中では、112 個もの評価データセットの分布が分析されていました。ここでは、その中でも「人気な」評価データセットをピックアップしてご紹介したいと思います。
被引用数の分布
「人気な」=頻繁に利用される評価データセットを調べるために、まずは各論文の利用頻度を調査しました。利用頻度の目安としては、評価データセットの提案論文の被引用数を使いました※4。
被引用数を調査する対象のデータセットは、LLMの基本的な能力を評価するデータセットに限定する目的で、サーベイ論文中の112個の評価データセットの内、図2中の「基礎能力」、「LLM拡張」分野のものとしました。また、2023年1月以降にリリースされた、比較的最近のデータセットのみを対象にしました。データセットに対応する提案論文が見つからないものに関しては調査の対象外としています。
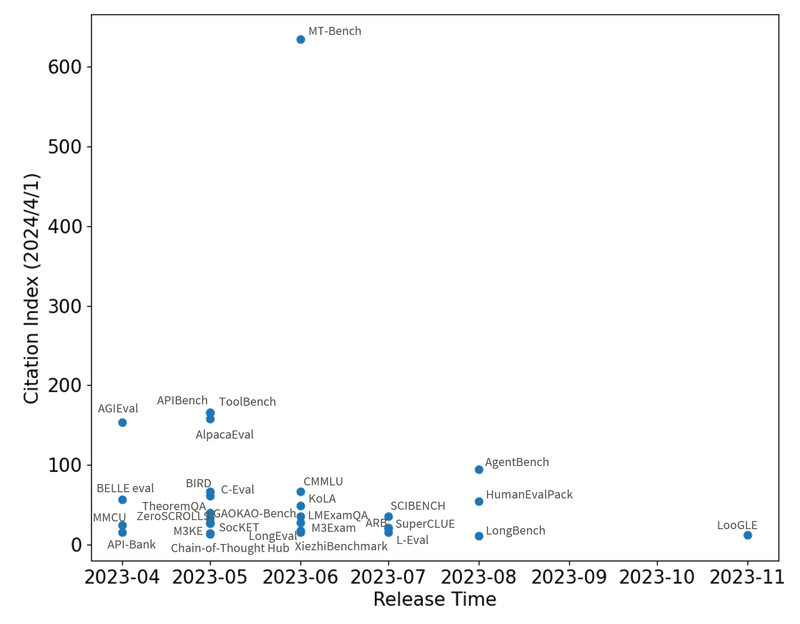
被引用数の分布をみると、MT-Bench[2]が目立って被引用数が高く、そのほかにも被引用数が100件を超すものがいくつかあります。以下では被引用数が多い、MT-Bench[2]、AGIEval[3]、APIBench[4]、ToolBench[5]、AlpacaEval[6]、AgentBench[7]を紹介します。
※4 今回は被引用数をデータセットの利用頻度の目安としていますが、厳密には被引用数が適切な指標であるかは議論の余地があります。例えばデータセットの提案論文がデータセットと同時に新しい技術を提案しているケースでは、被引用数にはデータセットの引用と技術の引用の両方が反映されるため、純粋な利用頻度とは異なるかもしれません。
MT-Bench
MT-Benchのデータセットは、マルチターンの質問を含む、高品質な 80 の英語の指示-応答データセットです。このデータセットの主な目的は、英語環境におけるLLMの総合的な能力を評価することです。
ライティング、ロールプレイ、推論、数学、プログラミング、情報抽出、STEM(科学、技術、工学、数学)、人文科学などの領域をカバーする8つのカテゴリを評価します。評価方法は、GPT-4を活用したモデル評価です。

AGIEval
AGIEvalデータセットは、大学入学試験など人間の受験者を対象にした問題を使ってLLM性能を評価するベンチマークです。公開されている試験問題やデータセットから収集した、英語と中国語の 8,062 の問題-回答データセットです。評価内容は、一般的な大学入試(GRE、Gaokao、SAT)、専門的な入試(LSAT、GMAT)、高校の数学競技会(AMC、AIME)、中国の公務員入試、法曹資格試験など、さまざまな分野から出題されます。
出題形式は多肢選択式と穴埋め式があり、評価方法はコード評価(多肢選択式では標準的な分類精度、穴埋め式では、完全一致とF1スコア)です。

APIBench
APIBenchデータセットは、API コールに特化したデータセットです。TorchHub、TensorHub、およびHuggingFaceの3つの主要なモデルハブから合計1645個のAPIを含みます。GPT-4を使って、各 API ごとに10個のユーザー質問が生成された、合計で16,450の英語による指示-APIコールのセットからなるデータセットです。LLMをファインチューニングするためのデータセットとしても、API関連命令の実行におけるモデルの習熟度を評価するベンチマークとしても役立ちます。
評価方法はコード評価です。
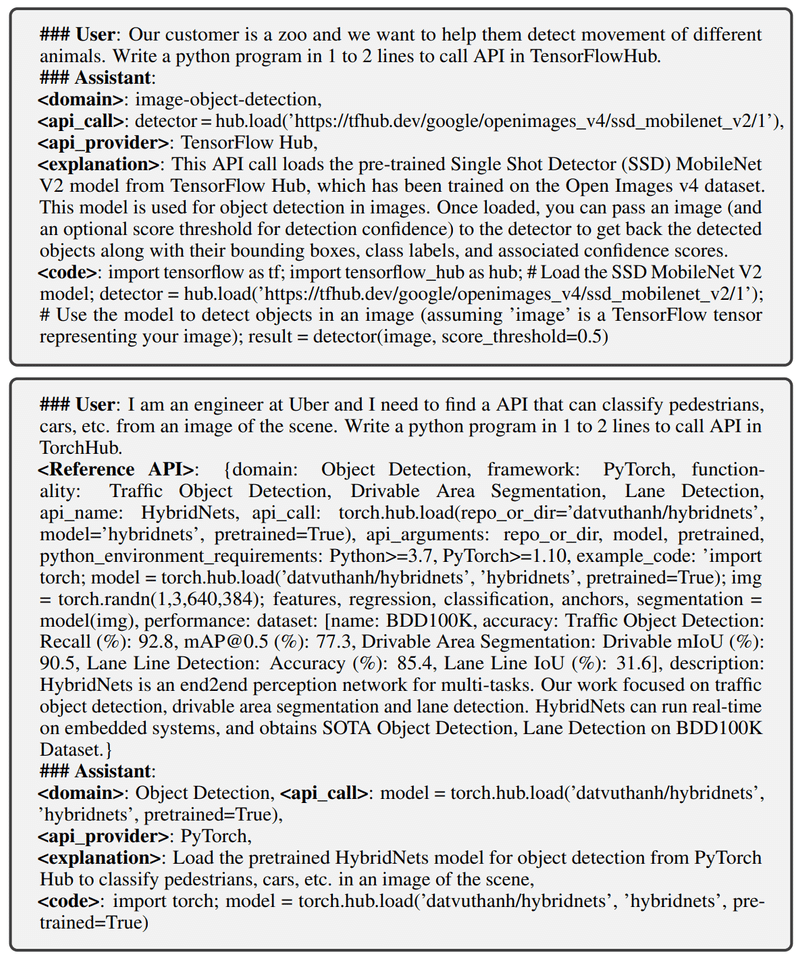
ToolBench
ToolBenchデータセットは、APIコールのためのファインチューニングおよびベンチマークデータセットです。以下の3ステップを経て構築されます。
RapidAPI Hubから16,464のAPIを収集
ChatGPTを用いて、単一API、および複数APIのシナリオを含む、APIを使用するための指示文を生成
ChatGPTを用いて、各指示に対する有効な解決策パス(API呼び出しの連鎖)を検索し、ラベル付け
最終的に、データセットは合計126,486の指示-解決策パスのセットになり、ツール呼び出しのための豊富なリソースを提供します。
評価方法はコード評価です。
AlpacaEval
AlpacaEvalは主に一般的な領域における様々な主観的な自由形式問題に対するLLMのパフォーマンスを評価することが目的のベンチマークです(AlpacaFarm[6]の改善、簡略化したもので、評価データセット・評価方法は共通です)。データセットに含まれる805の英語の指示は、既存の複数のデータセットから収集しています。
評価方法はモデル評価で、GPT-4などのモデルを用いて、LLMの応答を「davinci003」の応答と比較し、採点してます。

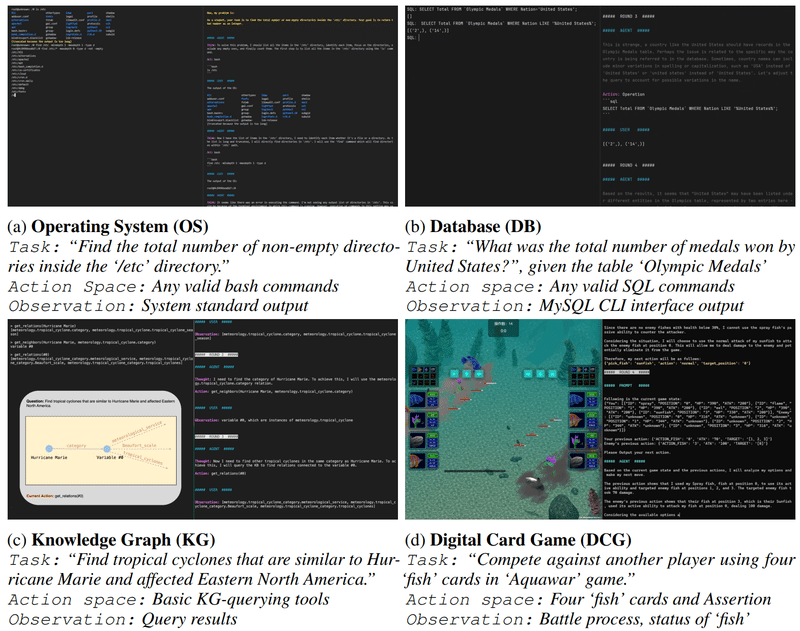
AgentBench
AgentBenchデータセットはLLMが駆動するAIエージェントの性能を評価する最初のベンチマークです。1,360の英語の指示が含まれ、8つの異なる環境とデータセットからなるタスクを用いて、AIエージェントとして機能するLLMのパフォーマンスを評価します。以下の8つの環境でテストします:オペレーティングシステム、データベース、ナレッジグラフ、デジタルカードゲーム、ラテラルシンキングパズル、家事、ウェブショッピング、ウェブブラウジング。
評価はコード評価です(タスクの成功率やF1スコアなど)。
最後に
LLMのデータセットについてのサーベイ論文を通して、世の中の代表的な評価データセットを概観することができました。その中で、評価データセットの分布には、以下のような特徴があることがわかりました。
評価データセットの半分近くは英語をメインで使用しており、それに次いで、中国語のデータセットが大きな割合を占めている。
評価データセットを20種類の幅広いカテゴリに分類することができるが、どのカテゴリにも比較的均等に分布している。
ほとんどの評価データセットはコード評価を採用している。
また、被引用数を指標にして「人気な」評価データセットを6つピックアップしてご紹介しました。その中には、LLMを用いたモデル評価を採用しているもの、評価データをLLMに生成させる手法を取るものがありました。
このように、LLMを用いて評価のコストを下げる・評価データセット作成のコストを下げる取り組みは、LLMの性能向上とともに、今後も継続していくと感じられます。
幅広いカテゴリの評価データセットがあることがわかりましたが、一方で、LLMを特定のアプリケーションで利用する際には、そのアプリケーション専用の評価データセットが必要になるでしょう。それは既存のデータセットでは代替できないこともあると思います。例えば、自分の好きなアニメキャラクターに(学習して)なりきったLLMとチャットする場合、どれだけキャラクターに"なりきれているか"(口調や記憶)を評価する必要があり、評価のための手法やデータセットを考える・作成する必要があります。
上記のような、特定アプリケーション向けの専用評価データセットの作成コストをLLMで下げることは可能だと考えられ、また個人的にも興味があります。ただ、人手で作成した高品質なデータセットとLLMを利用して作成したデータセットとで、評価にどのような差が出るのか、つまり「LLMが作成した評価データセットは信頼できるか」というのは気になるところです。この点は今後も調査を継続していきたいと思います。
参考文献
この記事が気に入ったらサポートをしてみませんか?