BERTの解説

前回ではトランスフォーマーのデコーダーの部分について書きました。
次はエンコーダーの部分を書こうと思っていたので、トランスフォーマーのエンコーダーを使っているBERTについて書くことにしました。内容は2018年に発表されたBERTの論文を基に進めていきます。
2017年にGoogleの研究者によりトランスフォーマーが論文「Attention is All You Need」に発表されました。間もなく2018年にOpenAIによりトランスフォーマーのデコーダーモデルを下流タスクに対応する論文を発表しています。また同じ年の2018年にGoogleのチームによりBERTが論文で発表され、当時のOpenAIのモデルよりも様々な下流タスクに向いていることが発表されました。
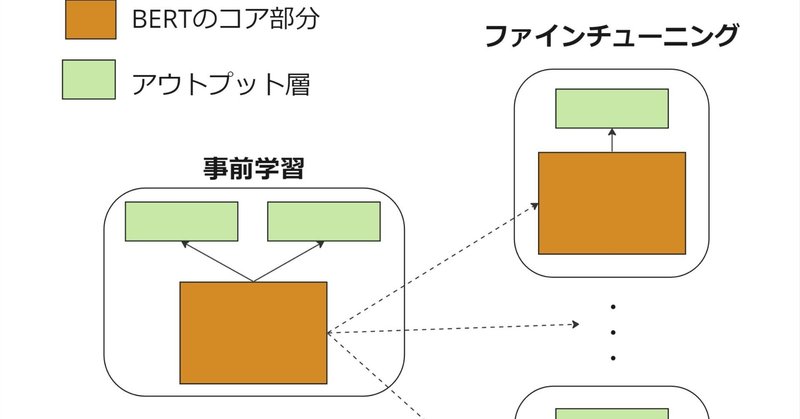
大規模言語モデルを下流タスクへ対応

上の図のイメージでは、ファインチューニングにより下流タスクへの対応を示したものです。事前学習で大規模データで学習することにより基礎知識はBERTのコア部分に保持されます。特定の下流タスクに適用するために、タスク固有のアウトプット層を追加します。ファインチューニングの段階は比較的少ないデータ量で行われ、この段階で事前学習済みのコア部分とアウトプット層(タスク固有の層)の両方のパラメータを微調整します。
事前学習の入力と出力データ構造
BERTでは事前学習のステップで二つのタスクを行います。
マスクされた単語予測タスク:入力からランダムに選ばれた単語をマスクし、そのマスクされた単語が何であるかを予測するタスク。
次の文章予測タスク:二つの文章(前文と後文)を見て、後文が前文に論理的に続くものかどうかを判定するタスク。
BERTに入力するテキストにマスキング([MASK])と文章の区切り([SEP])を同時に行うことで、マスクされた単語予測タスクと次の文章予測タスクを同時に学習することができます。

以下の三つのトークンがあります。
[MASK]
マスクされた単語予測タスクのため、トークンをマスキング
[SEP]
次の文章予測タスクのため、二つの文章を区切る役割
[CLS]
[CLS]トークン自体は特定の「意味」を持たないものの、モデルによる処理を通じて、文章全体の文脈を捉える情報を集約します。最終的に、分類タスクのための出力を提供する重要な役割を持ちます。

論文のTable 5に条件を変えて下流タスクでの精度比較を行っています。

一番良い → BERTがエンコーダーに二つのタスクで事前学習。
少し劣る → No NSPがエンコーダーに単語予測タスクのみで事前学習。
著しく劣る→LTR&No NSPがデコーダーに単語予測タスクのみで事前学習(これはOpenAIのGPTによる結果の条件に合わせたもの)。
単語予測タスクについて
Step1:トークン数全体の15%をランダムに選択
Step2:選択されたトークンに対して
・80%の確率で[MASK]に変換
・10%の確率でランダムに別のトークンに変換
・10%の確率でそのまま

Step1では、マスキングを過度にすると文脈がわからなくなる、また少なすぎても学習データが少なすぎる、そのため(ちょうど良い?)15%が設定されたと思います。
Step2では、[MASK]に変換する以外にもランダムに別トークンに変換したりしています。[MASK]が事前学習の時しか現れないために下流タスクの精度に影響してしまうのでは、といった仮定がされていたためです。

論文のTable 8から、
MASKが100%の確率で行われる場合、Feature-based(特徴量ベース)の精度が他のケースと比べて一番低いです。特徴量ベースではBERTのパラメータを微調整せずに、出力をそのまま特徴量としてつかう手法です。この場合、
[MASK]が下流タスクに存在しないために、影響していると思われます。
RNDが100%の確率で行われる場合(ランダムに別のトークンに置き換える)、MNLI(分類タスク)では一番低い結果を出しています。見解については論文に書かれていません。個人的な見解としては、MASKではどの単語がマスクされているか明確のためタスクの難易度としては低くい、一方でRNDだと文脈に合わない単語を見つける必要があり難易度が比較的高いため、MASKのほうが学びやすいからではと思います。しかし、下流タスクに[MASK]が現れない欠点があるため、20%は別のやり方で補っているような感じだと思います。
文章の分類タスク

文章2は50%の確率で正しいペアを用意します。ファインチューニングでは、正しいペアか否かの二値分類でモデルを学習させます。
BERTのコア部分
Transformerのエンコーダーの部分
元々の論文では翻訳機を応用として取り上げており、エンコーダーの箇所に翻訳したいテキストが入り、文章生成に適したデコーダーで翻訳テキストを生成します。

上の図のエンコーダーの部分がBERTのコア部分です。
以下の要素に構成されています。
Input Embedding(単語埋め込み)
Positional Embedding + Segment Embedding(位置埋め込みとセグメント埋め込み)
BERTではSegment Embeddingを使い2つの異なる文書を区別するために使用されます。
以下の層を数回繰り返す
Multi-Head Attention (マルチヘッドアテンション)
Add & Norm (スキップ接続とレイヤー正規化)
Feed Forward(全結合層とReLU層)
個々の影響について以前の記事でまとめています。簡単に書き綴ると
単語埋め込み?
各トークン(トークンとは?)を多次元ベクトルで情報を保持。
位置埋め込み?
トークンの位置を表現するために必要。アテンションメカニズムでは位置を認識する仕組みはないために、事前に位置情報を保持される必要がある。
マルチヘッドアテンション?
アテンションでは、トークン間の情報の伝達を可能にする。マルチヘッドでは、同じアテンション処理を複数平行に行うことにより、様々な観点から情報の伝達をおこない、最後に情報の結合をする。
Feed Forward(全結合層とReLU層)?
二つの全結合層でReLU層を挟む構造になっている。最初の全結合層でトークンのベクトルを4倍のサイズにして、ReLU層を通した後に、元のサイズに全結合層で戻す処理を行う。できるだけ情報を分解して、余分なところを切るような操作。
マルチヘッドアテンションの部分をもう少し詳しく説明していきます。
アテンション
アテンションメカニズムのデータの流れを以下にまとめます。

ステップ①
入力データが全結合層を通過し、この処理によって生成されるデータをQ(クエリ)、K(キー)、V(バリュー)と呼びます。クエリはどのような情報を探しているのか、キーはどのような情報を持っているか、バリューは具体的な情報、として捉えることができ、それぞれは各トークンのベクトル表現を保持してます。
ステップ②
QとKの内積を取り、アテンションスコアを計算します。これにより、各トークンが他のトークンとどの程度関連しているかのスコアが得られます。スコアは適切に正規化され、ソフトマックス関数を適用して重み係数を求めます。
例えば、トークン1が探している情報を他のトークンから検索するために、トークン1のクエリとすべてのトークン1, 2, …, Nのキーとの内積をとります。N個の内積の結果がそれぞれがトークン1と任意のトークンとの関係度を示しています。適切に正規化された値は、ステップ③で重み係数として使われます。
ちなみに、デコーダーでは、将来のトークンへのアクセスを防ぐためにマスキングが施され、情報が一方向(左から右へ)のみに流れるように制限されます。これに対し、エンコーダーでは全てのトークンが互いに情報を参照でき、双方向の情報流れが可能です。
→トランスフォーマーのエンコーダとデコーダーの違いはマスキングの有無。
ステップ③
アテンションスコアとバリュー(V)との積をとり、トークン間の情報が伝達されます。
マルチヘッドアテンション
マルチヘッドでは複数のアテンションの並行処理を行います。以下のイラストの「アテンション」の部分は上記のアテンションメカニズムがそのまま入ります。このように各アテンションで異なる特徴を抽出していると理解できます。

各アテンションから出力は結合され、そして最後に全結合層を通ります。マルチヘッドアテンションに入れる前と後のデータの次元(各トークンのベクトル表現)は必ず一致します。
参考文献
Attention Is All You Need
Improving Language Understanding by Generative Pre-Training
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
この記事が気に入ったらサポートをしてみませんか?