データでわかる #うたの日 【機械学習編】

うたの日ではどんな短歌が評価されやすいのか知りたくないですか。だってハート欲しいじゃん。この記事ではdoc2vecと機械学習を用いて、短歌が「自由詠」の部屋に出詠された場合のハート数の予測を試みます。
この記事でやること
うたの日はインターネット上で歌会を開催しているサイトです。普段は「題」に沿った短歌を募集していますが、月一で「自由詠」の部屋が出現します。
今回はうたの日の自由詠に出詠された短歌(1001日目から1393日目までの「自由詠」に出詠された2269首)について、機械学習で〈詠まれているものごとの傾向〉を学習し、それにもとづいて〈私の自作短歌(445首)がもし自由詠に出されたらいくつハートを獲得できるか〉を予測してみます。
ただ、結論を先に言ってしまうと、今回のこの試みはあまり上手くいっていません。
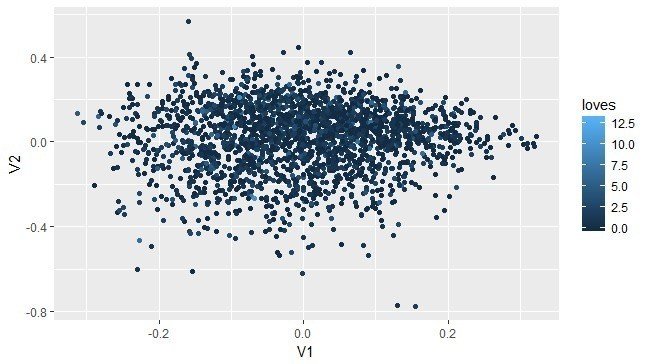
機械学習(教師あり学習)にできるのは、大まかには分類(=カテゴリの予想)と回帰(=値の予測)というタスクです。今回のケースだと、たとえば以下の図中の点についてV1とV2の値から点の色を予測するといったタスクに相当します。
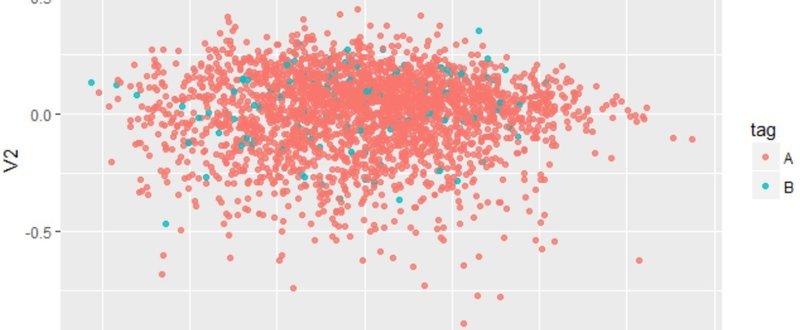
無理そうでしょ。ほとんど真っ暗だし。もうすこし問題を単純化して、色がAかBかを予想する問題にしてもこんな感じのイメージになります。
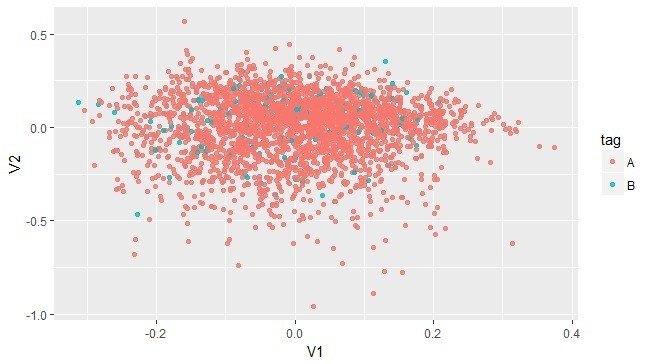
今回のケースでは、色Aと色BとはV1とV2というベクトルからなる空間上にほとんどランダムに分布していて、V1やV2の値からAかBかを予想するのは難しそうです。実際、Aに相当するかBに相当するかを当てようとした分類問題では、正答率は50%前後にとどまっています。2カテゴリへの分類では完全にランダムに分類してしまっても5割は正解すると期待されるので、正答率50%では予想として意味をなしません。学習に用いるモデルのパラメータを調整することでもうすこし正答率を上げられると思われますが、どうもあまりいい感じにはならなそうです。
上のイメージにおけるV1やV2は後述するdoc2vecというしくみによって〈詠まれているものごとの傾向〉をベクトルへ反映したものです。これらのベクトルから〈もし自由詠に出されたらいくつハートを獲得できるか〉を予測しようとしたけど、あまり上手くいきそうにない。以上のことから「こういうものごとについて詠んでおけばハート稼げるやろ」という作戦はうたの日の自由詠ではたぶん通用しないことが示唆されます。
要するに意味のある予測できてないんじゃんって話なんですが、手順を踏んで一応予測してみたのでよければ読んでみてください。
doc2vec
機械学習で文書の傾向を学習するには、文書のベクトル表現を用意する必要があります。doc2vecは文書のベクトル表現を得るための技術のひとつで、文脈(文書内における単語の順序)を考慮しつつ、文書をベクトル化することができます。これで得られるベクトルはなんやかんやで文書の意味内容を反映したものになります。
参考:Doc2Vecの仕組みとgensimを使った文書類似度算出チュートリアル - DeepAge
今回は自由詠に出された短歌と私の自作短歌をまとめてひとつの文書集合としたうえで、各文書(ここではそれぞれの短歌)を100次元の空間内に埋めこんでいます。
分類の手順
自由詠に出された短歌を付けられたハートの数によってタグ付けします。ここではハートが4つ未満の短歌をA、4つ以上付いた短歌をBとしました。タグ付けしたデータを分割して9割を訓練用データ、残りの1割をテスト用データにします。
うたの日で付けてもらえるハートの数はなかなかシビアなので、ハートが4つも付いている短歌というのは全体のなかではかなりの少数派になります(下図参照)。
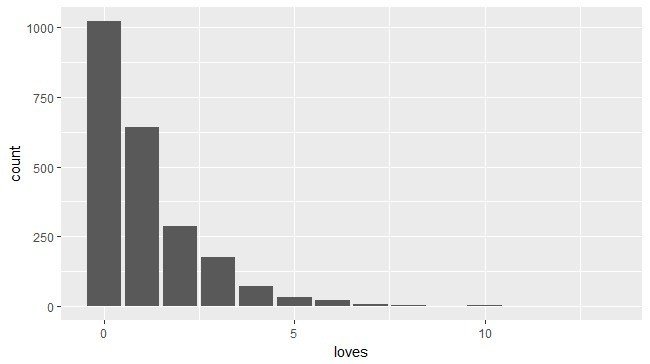
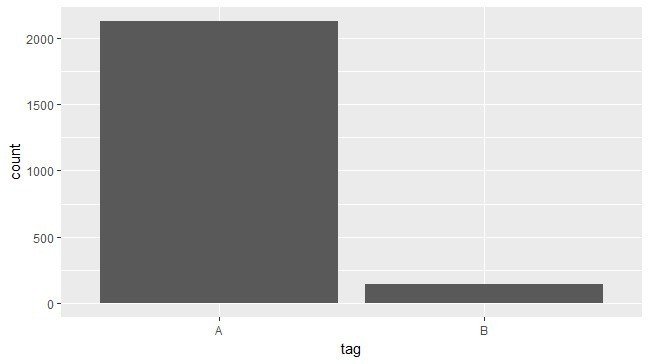
この比率のデータをそのまま学習させるとAの多さに引っ張られてほとんどすべての入力をAに分類するようになってしまいます。これを避けるためにSMOTEという技術を使ってそれぞれのサンプル数を調整して均衡したデータにします。
また、doc2vecで生成した100次元のベクトルは次元が多すぎて扱いづらいのでカーネル主成分分析で適当に圧縮します。
分類の結果
同一のデータについてSVMで学習した結果です。
- 5次元に圧縮した場合(正答率:47.22%)
- 10次元に圧縮した場合(正答率:52.38%)
- 15次元に圧縮した場合(正答率:56.06%)
- 20次元に圧縮した場合(正答率:50.00%)

正答率ベースでは15次元に圧縮した場合がもっともいい結果が出ました。誤分類は実際はBであるのにAと予想するケースが多いようです。ただし、いずれも50%前後なので分類の精度は悪いですね。
回帰の手順
分類のときと同様に、doc2vecで生成した100次元のベクトルをカーネル主成分分析で適当に圧縮します。これをすべて説明変数に投入して回帰します。
回帰の結果
ランダムフォレストとニューラルネット(単一中間層・階層型)で学習した結果です。

RMSEで見ると、10次元に圧縮したデータからニューラルネットで予測したときがもっとも絶対誤差が小さくなりました(それでも1以上の誤差がある)。しかし、ニューラルネットではモデルが変わるとハートが多く付くと予測される短歌が入れ替わってしまうことから、上手い具合に変数を反映しているわけではないと思われます。
ランダムフォレストでは「はるかぜはやさしいだけでぼくたちを殺してくれはしないってこと」という短歌だけは安定してベスト10に入っていました。こちらはハートが付く短歌の何かしらの傾向を学習しているのかもしれません。
ニューラルネット・10次元の場合のベスト10
1. (0.9992197)何もかも私のせいだあの雲もこんなすがたに変えてしまった
2. (0.9991078)カップヌードルができるのを待つあいだだけは未来がすぐそこにある
3. (0.9989329)名も知れぬ鳥のことばだ名も知れぬ花の名前をさえずる声だ
4. (0.9987641)何にでもなれる気がしたあの頃のおれは幼いガチャピンだった
5. (0.9986826)青空は文句ひとつもいわないで今日も静かに青々とある
6. (0.9986634)ぱっと見はアンモナイトの化石だが、これも誰かの恋だったのだ
7. (0.9986274)台風が来るとすべてが無理になる体質なので今日は無理です
8. (0.9985582)無印のホホバオイルが凍ってたあの冬の日が忘れられない
9. (0.9984671)自転車の漕ぎ方だけであなただとわかる自信がある(つまり恋)
10. (0.9984434)諸々の事情があって好きな子にパントマイムで告白をする
ランダムフォレスト・10次元の場合のベスト10
1. (2.399533)はるかぜはやさしいだけでぼくたちを殺してくれはしないってこと
2. (2.208633)じんせいのままならなさに泣きそうなので、今晩は肉を食べます
3. (2.195200)春と修羅、夏と極道、秋と魔女、冬と悪鬼と書き出してみた
4. (2.125100)(帰ってもよくないですか?)「すみませんお声が遠いようなのですが…」
5. (2.104267)ちょんまげの結い方なんか分かっても幕府ひらけるわけじゃないのよ?
6. (2.067567)めだかの学校にもモテる/モテないのヒエラルキーはあるのだろうか
7. (1.970167)ねえ今日ねニトリでちりとり・ほうき星セット売ってて買ってきちゃった
8. (1.965800)自転車の漕ぎ方だけであなただとわかる自信がある(つまり恋)
9. (1.913833)名も知れぬ鳥のことばだ名も知れぬ花の名前をさえずる声だ
10. (1.907500)ただ何をすればいいのかわからずに白湯を沸かせることのさみしさ
まとめ
機械学習は難しい。
この記事が気に入ったらサポートをしてみませんか?